
By Peter Gleeson
From a signalling perspective, the world is a noisy place. In order to make sense of anything, we have to be selective with our attention.
We humans have, over the course of millions of years of natural selection, become fairly good at filtering out background signals. We learn to associate particular signals with certain events.
For instance, imagine you’re playing table tennis in a busy office.
To return your opponent’s shot, you need to make a huge array of complex calculations and judgements, taking into account multiple competing sensory signals.
To predict the motion of the ball, your brain has to repeatedly sample the ball’s current position and estimate its future trajectory. More advanced players will also take into account any spin their opponent applied to the shot.
Finally, in order to play your own shot, you need to account for the position of your opponent, your own position, the speed of the ball, and any spin you intend to apply.
All of this involves an amazing amount of subconscious differential calculus. We take it for granted that, generally speaking, our nervous system can do this automatically (at least after a bit of practice).
Just as impressive is how the human brain differentially assigns importance to each of the myriad competing signals it receives. The position of the ball, for example, is judged to be more relevant than, say, the conversation taking place behind you, or the door opening in front of you.
This may sound so obvious as to seem unworthy of stating, but that is testament to the just how good we are at learning to make accurate predictions out of noisy data.
Certainly, a blank-state machine given a continuous stream of audiovisual data would face a difficult task knowing which signals best predict the optimal course of action.
Luckily, there are statistical and computational methods that can be used to identify patterns in noisy, complex data.
Correlation 101
Generally speaking, when we talk of ‘correlation’ between two variables, we are referring to their ‘relatedness’ in some sense.
Correlated variables are those which contain information about each other. The stronger the correlation, the more one variable tells us about the other.
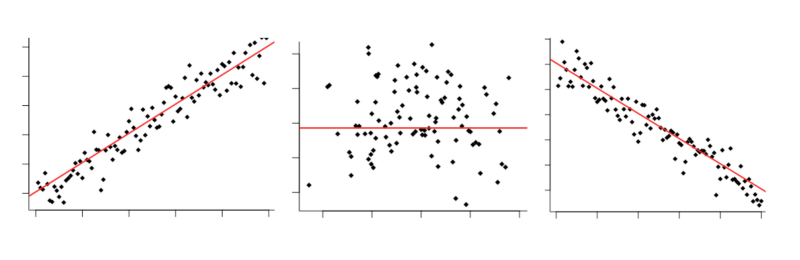 You may have seen it all before: Positive correlation, zero correlation, negative correlation
You may have seen it all before: Positive correlation, zero correlation, negative correlation
You may well already have some understanding of correlation, how it works and what its limitations are. Indeed, it’s something of a data science cliche:
“Correlation does not imply causation”
This is of course true — there are good reasons why even a strong correlation between two variables is not a guarantor of causality. The observed correlation could be due to the effects of a hidden third variable, or just entirely down to chance.
That said, correlation does allow for predictions about one variable to made based upon another. There are several methods that can be used to estimate correlated-ness for both linear and non-linear data. Let’s take a look at how they work.
We’ll go through the math and the code implementation, using Python and R. The code for the examples this article can be found here.
Pearson’s Correlation Coefficient
What is it?
Pearson’s Correlation Coefficient (PCC, or Pearson’s r) is a widely used linear correlation measure. It’s often the first one taught in many elementary stats courses. Mathematically speaking, it is defined as “the covariance between two vectors, normalized by the product of their standard deviations”.
Tell me more…
The covariance between two paired vectors is a measure of their tendency to vary above or below their means together. That is, a measure of whether each pair tend to be on similar or opposite sides of their respective means.
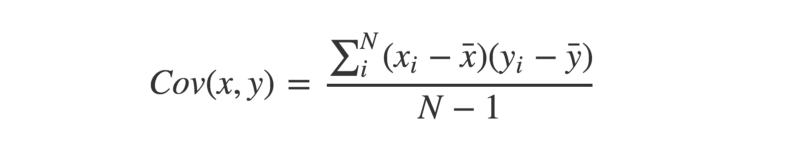
Let’s see this implemented in Python:
def mean(x):
return sum(x)/len(x)
def covariance(x,y):
calc = []
for i in range(len(x)):
xi = x[i] - mean(x)
yi = y[i] - mean(y)
calc.append(xi * yi)
return sum(calc)/(len(x) - 1)
a = [1,2,3,4,5] ; b = [5,4,3,2,1]
print(covariance(a,b))
The covariance is calculated by taking each pair of variables, and subtracting their respective means from them. Then, multiply these two values together.
- If they are both above their mean (or both below), then this will produce a positive number, because a positive×positive=positive, and likewise a negative×negative=positive.
- If they are on different sides of their means, then this produces a negative number (because positive×negative=negative).
Once we have all these values calculated for each pair, sum them up, and divide by n-1, where n is the sample size. This is the sample covariance.
If the pairs have a tendency to both be on the same side of their respective means, the covariance will be a positive number. If they have a tendency to be on opposite sides of their means, the covariance will be a negative number. The stronger this tendency, the larger the absolute value of the covariance.
If there is no overall pattern, then the covariance will be close to zero. This is because the positive and negative values will cancel each other out.
At first, it might appear that the covariance is a sufficient measure of ‘relatedness’ between two variables. However, take a look at the graph below:
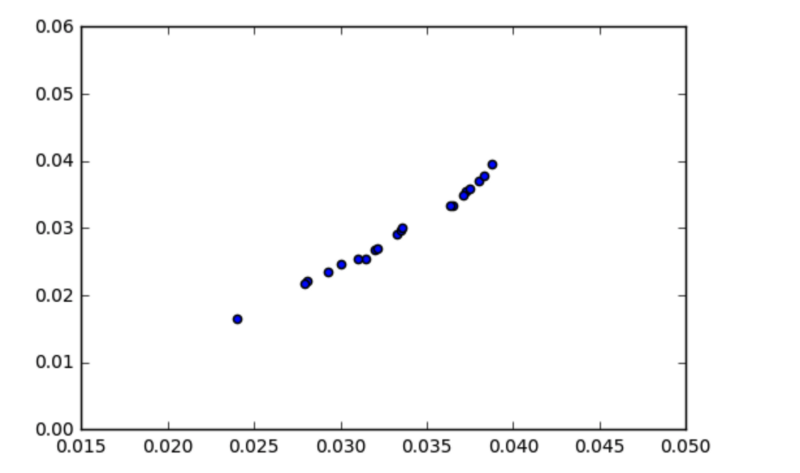 _Covariance = 0.00003. From a [question posted recently on stackexchange](https://stats.stackexchange.com/questions/320001/why-does-this-set-of-data-have-no-covariance" rel="noopener" target="blank" title=")
_Covariance = 0.00003. From a [question posted recently on stackexchange](https://stats.stackexchange.com/questions/320001/why-does-this-set-of-data-have-no-covariance" rel="noopener" target="blank" title=")
Looks like there’s a strong relationship between the variables, right? So why is the covariance so low, at approximately 0.00003?
The key here is to realise that the covariance is scale-dependent. Look at the x and y axes — pretty much all the data points fall between the range of 0.015 and 0.04. The covariance is likewise going to be close to zero, since it is calculated by subtracting the means from each individual observation.
To obtain a more meaningful figure, it is important to normalize the covariance. This is done by dividing it by the product of the standard deviations of each of the vectors.
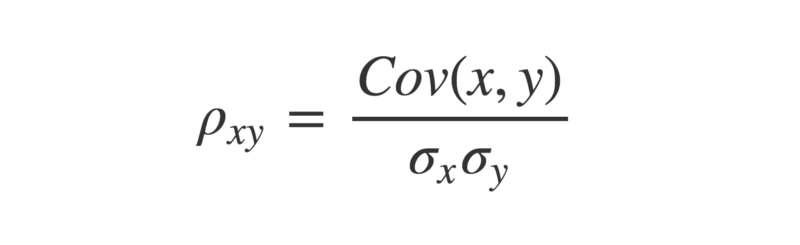 The Greek letter rho is often used to denote Pearson’s r
The Greek letter rho is often used to denote Pearson’s r
In Python:
import math
def stDev(x):
variance = 0
for i in x:
variance += (i - mean(x) ** 2) / len(x)
return math.sqrt(variance)
def Pearsons(x,y):
cov = covariance(x,y)
return cov / (stDev(x) * stDev(y))
The reason this is done is because the standard deviation of a vector is the square root of its variance. This means if two vectors are identical, then multiplying their standard deviations will equal their variance.
Funnily enough, the covariance of two identical vectors is also equal to their variance.
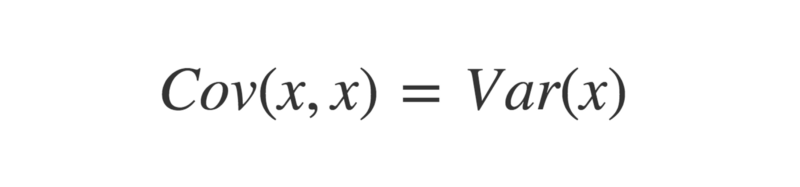
Therefore, the maximum value the covariance between two vectors can take is equal to the product of their standard deviations, which occurs when the vectors are perfectly correlated. It is this which bounds the correlation coefficient between -1 and +1.
Which way do the arrows point?
As an aside, a much cooler way of defining the PCC of two vectors comes from linear algebra.
First, we center the vectors, by subtracting their means from their individual values.
a = [1,2,3,4,5] ; b = [5,4,3,2,1]
a_centered = [i - mean(a) for i in a]
b_centered = [j - mean(b) for j in b]
Now, we can make use of the fact that vectors can be considered as ‘arrows’ pointing in a given direction.
For instance, in 2-D, the vector [1,3] could be represented as an arrow pointing 1 unit along the x-axis, and 3 units along the y-axis. Likewise, the vector [2,1] could be represented as an arrow pointing 2 units along the x-axis, and 1 unit along the y-axis.
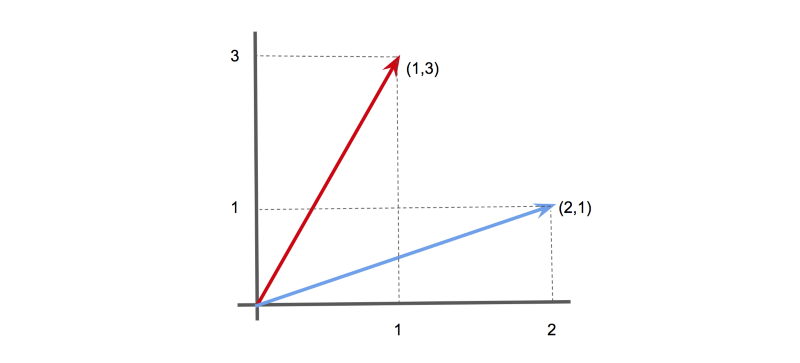 Two vectors (1,3) and (2,1) shown as arrows.
Two vectors (1,3) and (2,1) shown as arrows.
Similarly, we can represent our data vectors as arrows in an n-dimensional space (although don’t try visualising when n > 3…)
The angle ϴ between these arrows can be worked out using the dot product of the two vectors. This is defined as:
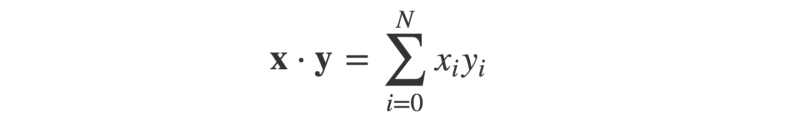
Or, in Python:
def dotProduct(x,y):
calc = 0
for i in range(len(x)):
calc += x[i] * y[i]
return calc
The dot product can also be defined as:
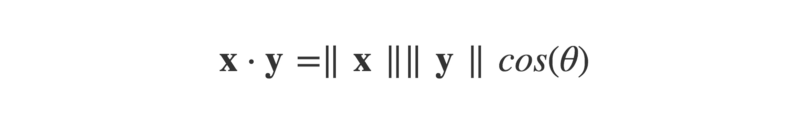
Where ||x|| is the magnitude (or ‘length’) of the vector x (think Pythagoras’ theorem), and ϴ is the angle between the arrow vectors.
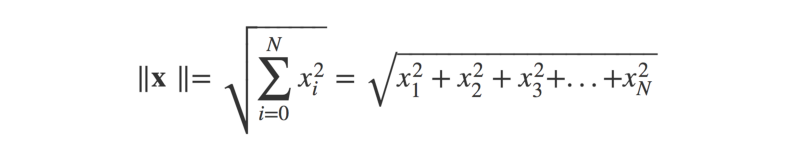
As a Python function:
def magnitude(x):
x_sq = [i ** 2 for i in x]
return math.sqrt(sum(x_sq))
This lets us find cos(ϴ), by dividing the dot product by the product of the magnitudes of the two vectors.
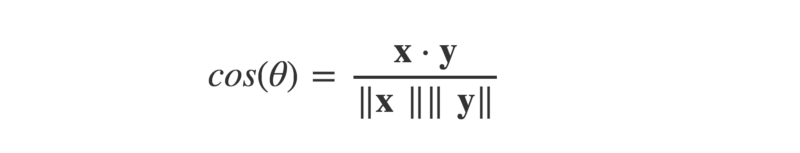
def cosTheta(x,y):
mag_x = magnitude(x)
mag_y = magnitude(y)
return dotProduct(x,y) / (mag_x * mag_y)
Now, if you know a little trigonometry, you may recall that the cosine function produces a graph that oscillates between +1 and -1.
 _[Source](http://cda.mrs.umn.edu/~mcquarrb/teachingarchive/Precalculus/Animations/SineCosineAnim.html" rel="noopener" target="blank" title=")
_[Source](http://cda.mrs.umn.edu/~mcquarrb/teachingarchive/Precalculus/Animations/SineCosineAnim.html" rel="noopener" target="blank" title=")
The value of cos(ϴ) will vary depending on the angle between the two arrow vectors.
- When the angle is zero (i.e., the vectors point in the exact same direction), cos(ϴ) will equal 1.
- When the angle is -180°, (the vectors point in exact opposite directions), then cos(ϴ) will equal -1.
- When the angle is 90° (the vectors point in completely unrelated directions), then cos(ϴ) will equal zero.
This might look familiar — a measure between +1 and -1 that seems to describe the relatedness of two vectors? Isn’t that Pearson’s r?
Well — that is exactly what it is! By considering the data as arrow vectors in a high-dimensional space, we can use the angle ϴ between them as a measure of similarity.
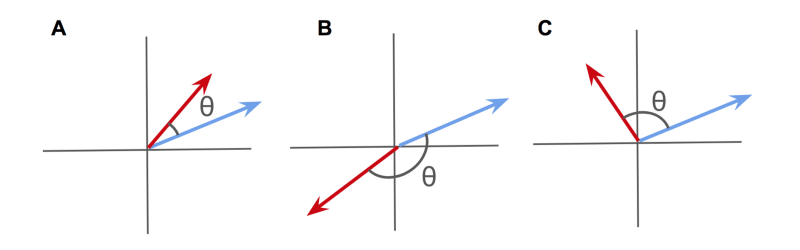 A) Positively correlated vectors; B) Negatively correlated vectors; C) Uncorrelated vectors
A) Positively correlated vectors; B) Negatively correlated vectors; C) Uncorrelated vectors
The cosine of this angle ϴ is mathematically identical to Pearson’s Correlation Coefficient.
When viewed as high-dimensional arrows, positively correlated vectors will point in a similar direction.
Negatively correlated vectors will point towards opposite directions.
And uncorrelated vectors will point at right-angles to one another.
Personally, I think this is a really intuitive way to make sense of correlation.
Statistical significance?
As is always the case with frequentist statistics, it is important to ask how significant a test statistic calculated from a given sample actually is. Pearson’s r is no exception.
Unfortunately, whacking confidence intervals on an estimate of PCC is not entirely straightforward.
This is because Pearson’s r is bound between -1 and +1, and therefore isn’t normally distributed. An estimated PCC of, say, +0.95 has only so much room for error above it, but plenty of room below.
Luckily, there is a solution — using a trick called Fisher’s Z-transform:
- Calculate an estimate of Pearson’s r as usual.
- Transform r→z using Fisher’s Z-transform. This can be done by using the formula z = arctanh(r), where arctanh is the inverse hyperbolic tangent function.
- Now calculate the standard deviation of z. Luckily, this is straightforward to calculate, and is given by SDz = 1/sqrt(n-3), where n is the sample size.
- Choose your significance threshold, alpha, and check how many standard deviations from the mean this corresponds to. If we take alpha = 0.95, use 1.96.
- Find the upper estimate by calculating z +(1.96 × SDz), and the lower bound by calculating z - (1.96 × SDz).
- Convert these back to r, using r = tanh(z), where tanh is the hyperbolic tangent function.
- If the upper and lower bounds are both the same side of zero, you have statistical significance!
Here’s a Python implementation:
r = Pearsons(x,y)
z = math.atanh(r)
SD_z = 1 / math.sqrt(len(x) - 3)
z_upper = z + 1.96 * SD_z
z_lower = z - 1.96 * SD_z
r_upper = math.tanh(z_upper)
r_lower = math.tanh(z_lower)
Of course, when given a large data set of many potentially correlated variables, it may be tempting to check every pairwise correlation. This is often referred to as ‘data dredging’ — scouring the data set for any apparent relationships between the variables.
If you do take this multiple comparison approach, you should use stricter significance thresholds to reduce your risk of discovering false positives (that is, finding unrelated variables which appear correlated purely by chance).
One method for doing this is to use the Bonferroni correction.
The small print
So far, so good. We’ve seen how Pearson’s r can be used to calculate the correlation coefficient between two variables, and how to assess the statistical significance of the result. Given an unseen set of data, it is possible to start mining for significant relationships between the variables.
However, there is a major catch — Pearson’s r only works for linear data.
Look at the graphs below. They clearly show what looks like a non-random relationship, but Pearson’s r is very close to zero.
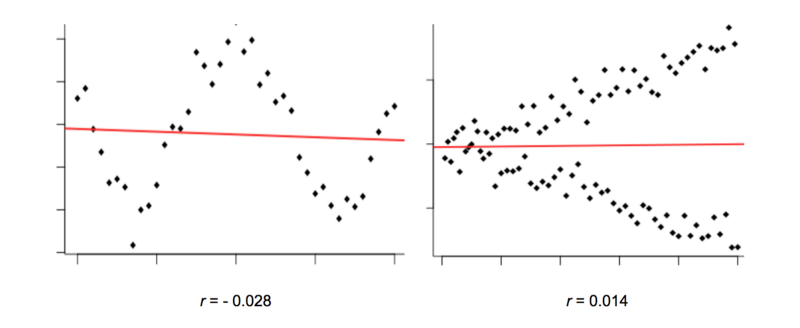
The reason why is because the variables in these graphs have a non-linear relationship.
We can generally picture a relationship between two variables as a ‘cloud’ of points scattered either side of a line. The wider the scatter, the ‘noisier’ the data, and the weaker the relationship.
However, Pearson’s r compares each individual data point with only one other (the overall means). This means it can only consider straight lines. It’s not great at detecting any non-linear relationships.
In the graphs above, Pearson’s r doesn’t reveal there being much correlation to talk of.
Yet the relationship between these variables is still clearly non-random, and that makes them potentially useful predictors of each other. How can machines identify this? Luckily, there are different correlation measures available to us.
Let’s take a look at a couple of them.
Distance Correlation
What is it?
Distance correlation bears some resemblance to Pearson’s r, but is actually calculated using a rather different notion of covariance. The method works by replacing our everyday concepts of covariance and standard deviation (as defined above) with “distance” analogues.
Much like Pearson’s r, “distance correlation” is defined as the “distance covariance” normalized by the “distance standard deviation”.
Instead of assessing how two variables tend to co-vary in their distance from their respective means, distance correlation assesses how they tend to co-vary in terms of their distances from all other points.
This opens up the potential to better capture non-linear dependencies between variables.
The finer details…
Robert Brown was a Scottish botanist born in 1773. While studying plant pollen under his microscope, Brown noticed tiny organic particles jittering about at random on the surface of the water he was using.
Little could he have suspected a chance observation of his would lead to his name being immortalized as the (re-)discoverer of Brownian motion.
Even less could he have known that it would take nearly a century before Albert Einstein would provide an explanation for the phenomenon — and hence proving the existence of atoms — in the same year he published papers on E=MC², special relativity and helped kick-start the field of quantum theory.
Brownian motion is a physical process whereby particles move about at random due to collisions with surrounding molecules.
The math behind this process can be generalized into a concept known as the Weiner process. Among other things, the Weiner process plays an important part in mathematical finance’s most famous model, Black-Scholes.
Interestingly, Brownian motion and the Weiner process turn out to be relevant to a non-linear correlation measure developed in the mid-2000’s through the work of Gabor Szekely.
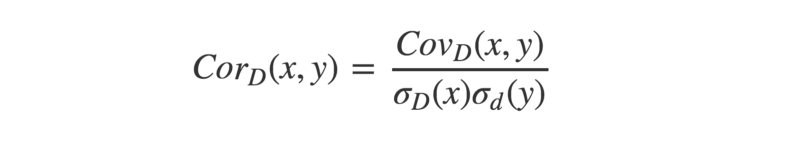
Let’s run through how this can be calculated for two vectors x and y, each of length N.
- First, we form N×N distance matrices for each of the vectors. A distance matrix is exactly like a road distance chart in an atlas — the intersection of each row and column shows the distance between the corresponding cities. Here, the intersection between row i and column j gives the distance between the i-th and j-th elements of the vector.
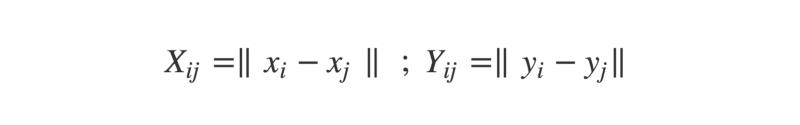
- Next, the matrices are “double-centered”. This means for each element, we subtract the mean of its row and the mean of its column. Then, we add the grand mean of the entire matrix.
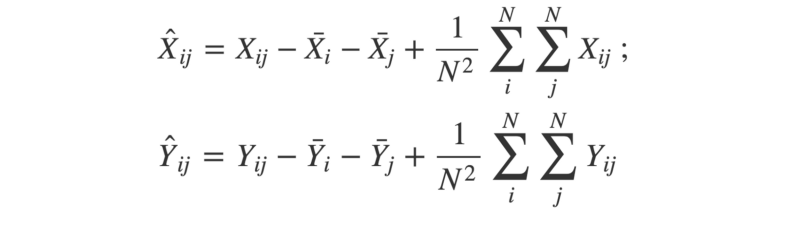 The ‘hat’ symbols mean ‘double-centred’; the ‘bar’ symbols mean ‘mean’
The ‘hat’ symbols mean ‘double-centred’; the ‘bar’ symbols mean ‘mean’
- With the two double-centered matrices, we can calculate the square of the distance covariance by taking the average of each element in X multiplied by its corresponding element in Y.
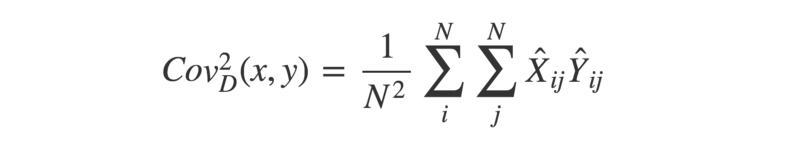
- Now, we can use a similar approach to find the “distance variance”. Remember — the covariance of two identical vectors is equivalent to their variance. Therefore, the squared distance variance can be described as below:
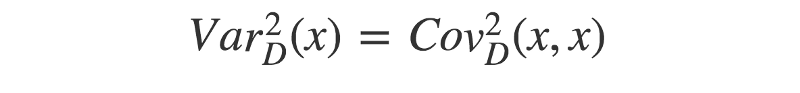
- Finally, we have all the pieces to calculate the distance correlation. Remember that the (distance) standard deviation is equal to the square-root of the (distance) variance.
If you prefer to work through code instead of math notation (after all, there is a reason people tend to write software in one and not the other…), then check out the R implementation below:
set.seed(1234)
doubleCenter <- function(x){
centered <- x
for(i in 1:dim(x)[1]){
for(j in 1:dim(x)[2]){
centered[i,j] <- x[i,j] - mean(x[i,]) - mean(x[,j]) + mean(x)
}
}
return(centered)
}
distanceCovariance <- function(x,y){
N <- length(x)
distX <- as.matrix(dist(x))
distY <- as.matrix(dist(y))
centeredX <- doubleCenter(distX)
centeredY <- doubleCenter(distY)
calc <- sum(centeredX * centeredY)
return(sqrt(calc/(N^2)))
}
distanceVariance <- function(x){
return(distanceCovariance(x,x))
}
distanceCorrelation <- function(x,y){
cov <- distanceCovariance(x,y)
sd <- sqrt(distanceVariance(x)*distanceVariance(y))
return(cov/sd)
}
# Compare with Pearson's r
x <- -10:10
y <- x^2 + rnorm(21,0,10)
cor(x,y) # --> 0.057
distanceCorrelation(x,y) # --> 0.509
The distance correlation between any two variables is bound between zero and one. Zero implies the variables are independent, whereas a score closer to one indicates a dependent relationship.
If you’d rather not write your own distance correlation methods from scratch, you can install R’s energy package, written by very researchers who devised the method. The methods available in this package call functions written in C, giving a great speed advantage.
Physical interpretation
One of the more surprising results relating to the formulation of distance correlation is that it bears an exact equivalence to Brownian correlation.
Brownian correlation refers to the independence (or dependence) of two Brownian processes. Brownian processes that are dependent will show a tendency to ‘follow’ each other.
A simple metaphor to help grasp the concept of distance correlation is to picture a fleet of paper boats floating on the surface of a lake.
If there is no prevailing wind direction, then each boat will drift about at random — in a way that’s (kind of) analogous to Brownian motion.
 Boats drifting under no prevailing wind
Boats drifting under no prevailing wind
If there is a prevailing wind, then the direction the boats drift in will be dependent upon the strength of the wind. The stronger the wind, the stronger the dependence.
 Under a prevailing wind, the boats will tend to drift in the same direction
Under a prevailing wind, the boats will tend to drift in the same direction
In a comparable way, uncorrelated variables can be thought of as boats drifting without a prevailing wind. Correlated variables can be thought of as boats drifting under the influence of a prevailing wind. In this metaphor, the wind represents the strength of the relationship between the two variables.
If we allow the prevailing wind direction to vary at different points on the lake, then we can bring a notion of non-linearity into the analogy. Distance correlation uses the distances between the ‘boats’ to infer the strength of the prevailing wind.

Confidence Intervals?
Confidence intervals can be established for a distance correlation estimate using a ‘resampling’ technique. A simple example is bootstrap resampling.
This is a neat statistical trick that requires us to ‘reconstruct’ the data by randomly sampling (with replacement) from the original data set. This is repeated many times (e.g., 1000), and each time the statistic of interest is calculated.
This will produce a range of different estimates for the statistic we’re interested in. We can use these to estimate the upper and lower bounds for a given level of confidence.
Check out the R code below for a simple bootstrap function:
set.seed(1234)
bootstrap <- function(x,y,reps,alpha){
estimates <- c()
original <- data.frame(x,y)
N <- dim(original)[1]
for(i in 1:reps){
S <- original[sample(1:N, N, replace = TRUE),]
estimates <- append(estimates, distanceCorrelation(S$x, S$y))
}
u <- alpha/2 ; l <- 1-u
interval <- quantile(estimates, c(l, u))
return(2*(dcor(x,y)) - as.numeric(interval[1:2]))
}
# Use with 1000 reps and threshold alpha = 0.05
x <- -10:10
y <- x^2 + rnorm(21,0,10)
bootstrap(x,y,1000,0.05) # --> 0.237 to 0.546
If you want to establish statistical significance, there is another resampling trick available, called a ‘permutation test’.
This is slightly different to the bootstrap method defined above. Here, we keep one vector constant and ‘shuffle’ the other by resampling. This approximates the null hypothesis — that there is no dependency between the variables.
The ‘shuffled’ variable is then used to calculate the distance correlation between it and the constant variable. This is done many times, and the distribution of outcomes is compared against the actual distance correlation (obtained from the unshuffled data).
The proportion of ‘shuffled’ outcomes greater than or equal to the ‘real’ outcome is then taken as a p-value, which can be compared to a given significance threshold (e.g., 0.05).
Check out the code to see how this works:
permutationTest <- function(x,y,reps){
estimates <- c()
observed <- distanceCorrelation(x,y)
N <- length(x)
for(i in 1:reps){
y_i <- sample(y, length(y), replace = T)
estimates <- append(estimates, distanceCorrelation(x, y_i))
}
p_value <- mean(estimates >= observed)
return(p_value)
}
# Use with 1000 reps
x <- -10:10
y <- x^2 + rnorm(21,0,10)
permutationTest(x,y,1000) # --> 0.036
Maximal Information Coefficient
What is it?
The Maximal Information Coefficient (MIC) is a recent method for detecting non-linear dependencies between variables, devised in 2011. The algorithm used to calculate MIC applies concepts from information theory and probability to continuous data.
Diving in…
Information theory is a fascinating field within mathematics that was pioneered by Claude Shannon in the mid-twentieth century.
A key concept is entropy — a measure of the uncertainty in a given probability distribution. A probability distribution describes the probabilities of a given set of outcomes associated with a particular event.
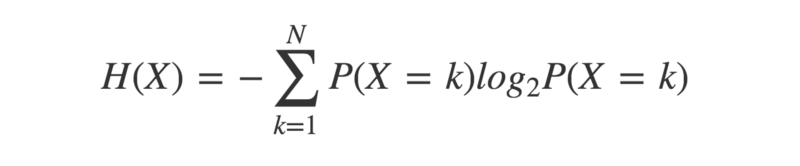 Entropy of a probability distribution is minus “the sum of the probability of each outcome, multiplied by the logarithm of itself”
Entropy of a probability distribution is minus “the sum of the probability of each outcome, multiplied by the logarithm of itself”
To understand how this works, compare the two probability distributions below:
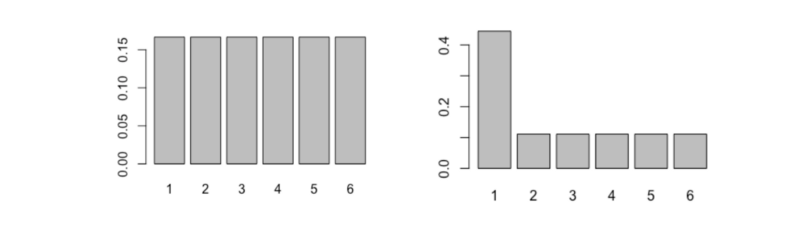 Possible outcomes are on the X-axis; their respective probabilities are on the Y-axis
Possible outcomes are on the X-axis; their respective probabilities are on the Y-axis
On the left is that of a fair six-sided dice, and on the right is the distribution of a not-so-fair six-sided dice.
Intuitively, which would you expect to have the higher entropy? For which dice is the outcome the least certain? Let’s calculate the entropy and see what the answer turns out to be.
entropy <- function(x){
pr <- prop.table(table(x))
H <- sum(pr * log(pr,2))
return(-H)
}
dice1 <- 1:6
dice2 <- c(1,1,1,1,2:6)
entropy(dice1) # --> 2.585
entropy(dice2) # --> 2.281
As you may have expected, the fairer dice has the higher entropy.
That is because each outcome is as likely as any other, so we cannot know in advance which to favour.
The unfair dice gives us more information — some outcomes are much more likely than others — so there is less uncertainty about the outcome.
By that reasoning, we can see that entropy will be highest when each outcome is equally likely. This type of probability distribution is called a ‘uniform’ distribution.
Cross-entropy is an extension to the concept of entropy, that takes into account a second probability distribution.
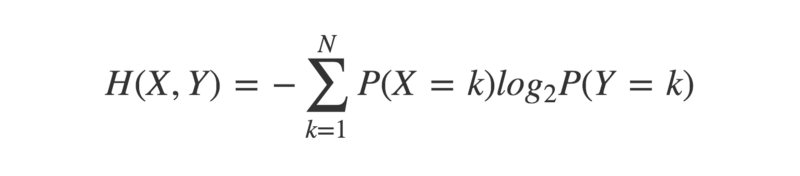
crossEntropy <- function(x,y){
prX <- prop.table(table(x))
prY <- prop.table(table(y))
H <- sum(prX * log(prY,2))
return(-H)
}
This has the property that the cross-entropy between two identical probability distributions is equal to their individual entropy. When considering two non-identical probability distributions, there will be a difference between their cross-entropy and their individual entropies.
This difference, or ‘divergence’, can be quantified by calculating their Kullback-Leibler divergence, or KL-divergence.
The KL-divergence of two probability distributions X and Y is:
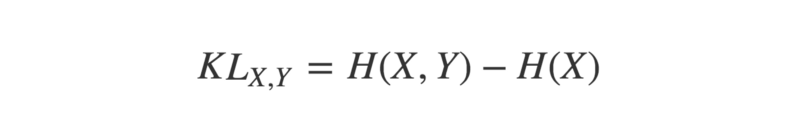 KL-divergence of probability distributions X and Y equals their cross-entropy, minus the entropy of X
KL-divergence of probability distributions X and Y equals their cross-entropy, minus the entropy of X
The minimum value of the KL-divergence between two distributions is zero. This only happens when the distributions are identical.
KL_divergence <- function(x,y){
kl <- crossEntropy(x,y) - entropy(x)
return(kl)
}
One use for KL-divergence in the context of discovering correlations is to calculate the Mutual Information (MI) of two variables.
Mutual Information can be defined as “the KL-divergence between the joint and marginal distributions of two random variables”. If these are identical, MI will equal zero. If they are at all different, then MI will be a positive number. The more different the joint and marginal distributions are, the higher the MI.
To understand this better, let’s take a moment to revisit some probability concepts.
The joint distribution of variables X and Y is simply the probability of them co-occurring. For instance, if you flipped two coins X and Y, their joint distribution would reflect the probability of each observed outcome. Say you flip the coins 100 times, and get the result “heads, heads” 40 times. The joint distribution would reflect this.
P(X=H, Y=H) = 40/100 = 0.4
jointDist <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
joint <- c()
for(i in u){
for(j in u){
f <- x[paste0(x,y) == paste0(i,j)]
joint <- append(joint, length(f)/N)
}
}
return(joint)
}
The marginal distribution is the probability distribution of one variable in the absence of any information about the other. The product of two marginal distributions gives the probability of two events’ co-occurrence under the assumption of independence.
For the coin flipping example, say both coins produce 50 heads and 50 tails. Their marginal distributions would reflect this.
P(X=H) = 50/100 = 0.5 ; P(Y=H) = 50/100 = 0.5
P(X=H) × P(Y=H) = 0.5 × 0.5 = 0.25
marginalProduct <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
marginal <- c()
for(i in u){
for(j in u){
fX <- length(x[x == i]) / N
fY <- length(y[y == j]) / N
marginal <- append(marginal, fX * fY)
}
}
return(marginal)
}
Returning to the coin flipping example, the product of the marginal distributions will give the probability of observing each outcome if the two coins are independent, while the joint distribution will give the probability of each outcome, as actually observed.
If the coins genuinely are independent, then the joint distribution should be (approximately) identical to the product of the marginal distributions. If they are in some way dependent, then there will be a divergence.
In the example, P(X=H,Y=H) > P(X=H) × P(Y=H). This suggests the coins both land on heads more often than would be expected by chance.
The bigger the divergence between the joint and marginal product distributions, the more likely it is the events are dependent in some way. The measure of this divergence is defined by the Mutual Information of the two variables.
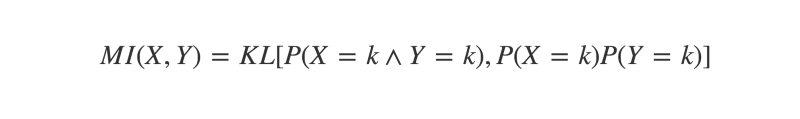 The Mutual Information of X and Y equals “the KL divergence of their joint distribution, and the product of their marginal distributions”
The Mutual Information of X and Y equals “the KL divergence of their joint distribution, and the product of their marginal distributions”
mutualInfo <- function(x,y){
joint <- jointDist(x,y)
marginal <- marginalProduct(x,y)
Hjm <- - sum(joint[marginal > 0] * log(marginal[marginal > 0],2))
Hj <- - sum(joint[joint > 0] * log(joint[joint > 0],2))
return(Hjm - Hj)
}
A major assumption here is that we are working with discrete probability distributions. How can we apply these concepts to continuous data?
Binning
One approach is to quantize the data (make the variables discrete). This is achieved by binning (assigning data points to discrete categories).
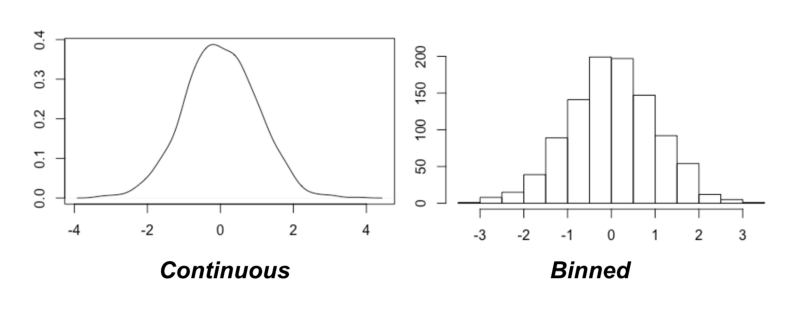
The key issue now is deciding how many bins to use. Luckily, the original paper on the Maximal Information Coefficient provides a suggestion: try most of them!
That is to say, try differing numbers of bins and see which produces the greatest result of Mutual Information between the variables. This raises two challenges, though:
- How many bins to try? Technically, you could quantize a variable into any number of bins, simply by making the bin size forever smaller.
- Mutual Information is sensitive to the number of bins used. How do you fairly compare MI between different numbers of bins?
The first challenge means it is technically impossible to try every possible number of bins. However, the authors of the paper offer a heuristic solution (that is, a solution which is not ‘guaranteed perfect’, but is a pretty good approximation). They also suggest an upper limit on the number of bins to try.
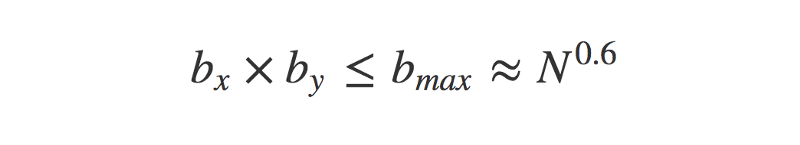 The maximum number of bins to try is determined by the sample size, N
The maximum number of bins to try is determined by the sample size, N
As for fairly comparing MI values between different binning schemes, there’s a simple fix… normalize it! This can be done by dividing each MI score by the maximum it could theoretically take for that particular combination of bins.
The binning combination that produces the highest normalized MI overall is the one to use.
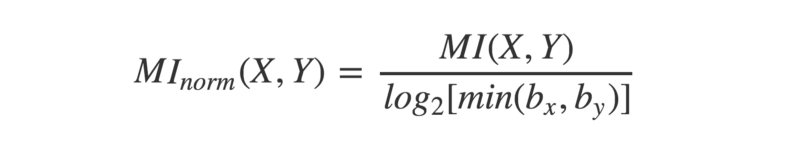 Mutual Information can be normalized by dividing by the logarithm of the smallest number of bins
Mutual Information can be normalized by dividing by the logarithm of the smallest number of bins
The highest normalized MI is then reported as the Maximal Information Coefficient (or ‘MIC’) for those two variables. Let’s check out some code that will estimate the MIC of two continuous variables.
MIC <- function(x,y){
N <- length(x)
maxBins <- ceiling(N ** 0.6)
MI <- c()
for(i in 2:maxBins) {
for (j in 2:maxBins){
if(i * j > maxBins){
next
}
Xbins <- i; Ybins <- j
binnedX <-cut(x, breaks=Xbins, labels = 1:Xbins)
binnedY <-cut(y, breaks=Ybins, labels = 1:Ybins)
MI_estimate <- mutualInfo(binnedX,binnedY)
MI_normalized <- MI_estimate / log(min(Xbins,Ybins),2)
MI <- append(MI, MI_normalized)
}
}
return(max(MI))
}
x <- runif(100,-10,10)
y <- x**2 + rnorm(100,0,10)
MIC(x,y) # --> 0.751
The above code is a simplification of the method outlined in the original paper. A more faithful implementation of the algorithm is available in the R package minerva. In Python, you can use the minepy module.
MIC is capable of picking out all kinds of linear and non-linear relationships, and has found use in a range of different applications. It is bound between 0 and 1, with higher values indicating greater dependence.
Confidence Intervals?
To establish confidence bounds on an estimate of MIC, you can simply use a bootstrapping technique like the one we looked at earlier.
To generalize the bootstrap function, we can take advantage of R’s functional programming capabilities, by passing the technique we want to use as an argument.
bootstrap <- function(x,y,func,reps,alpha){
estimates <- c()
original <- data.frame(x,y)
N <- dim(original)[1]
for(i in 1:reps){
S <- original[sample(1:N, N, replace = TRUE),]
estimates <- append(estimates, func(S$x, S$y))
}
l <- alpha/2 ; u <- 1 - l
interval <- quantile(estimates, c(u, l))
return(2*(func(x,y)) - as.numeric(interval[1:2]))
}
bootstrap(x,y,MIC,100,0.05) # --> 0.594 to 0.88
Summary
To conclude this tour of correlation, let’s test each different method against a range of artificially generated data. The code for these examples can be found here.
Noise
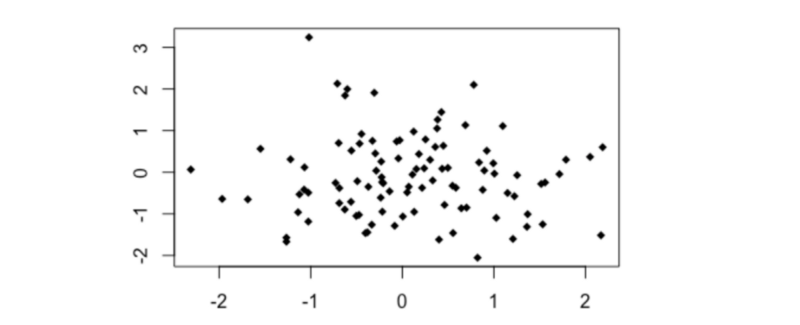
set.seed(123)
# Noise
x0 <- rnorm(100,0,1)
y0 <- rnorm(100,0,1)
plot(y0~x0, pch = 18)
cor(x0,y0)
distanceCorrelation(x0,y0)
MIC(x0,y0)
- Pearson’s r = - 0.05
- Distance Correlation = 0.157
- MIC = 0.097
Simple linear
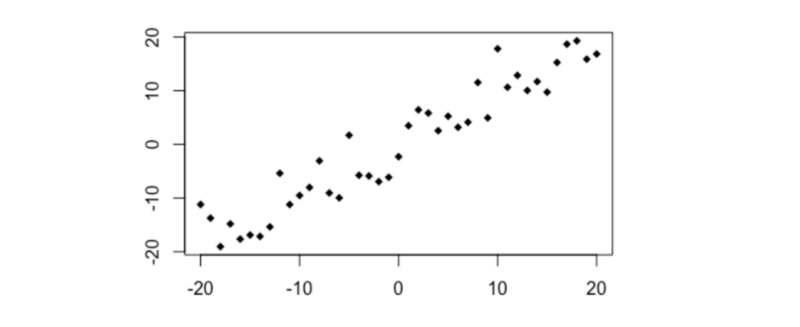
# Simple linear relationship
x1 <- -20:20
y1 <- x1 + rnorm(41,0,4)
plot(y1~x1, pch =18)
cor(x1,y1)
distanceCorrelation(x1,y1)
MIC(x1,y1)
- Pearson’s r =+0.95
- Distance Correlation = 0.95
- MIC = 0.89
Simple quadratic
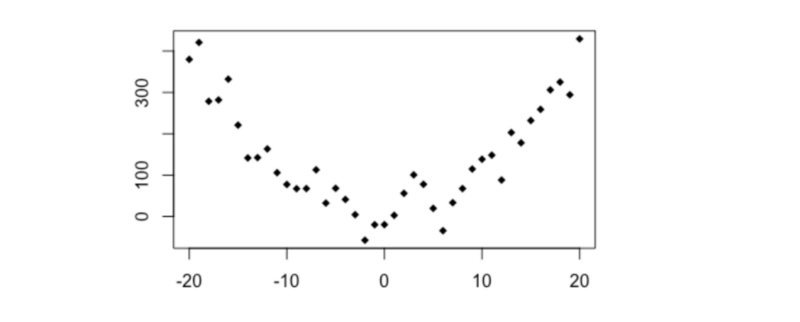
# y ~ x**2
x2 <- -20:20
y2 <- x2**2 + rnorm(41,0,40)
plot(y2~x2, pch = 18)
cor(x2,y2)
distanceCorrelation(x2,y2)
MIC(x2,y2)
- Pearson’s r =+0.003
- Distance Correlation = 0.474
- MIC = 0.594
Trigonometric
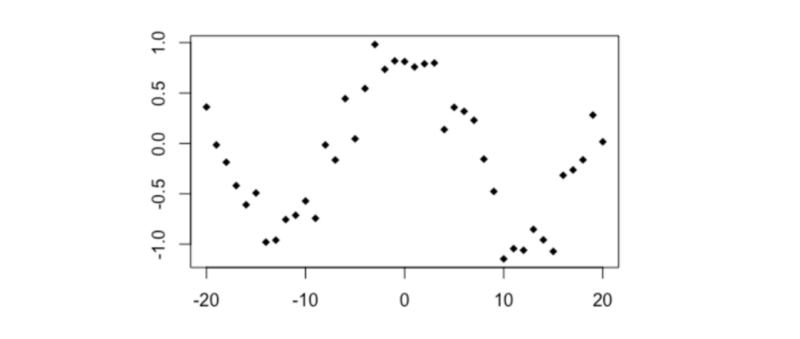
# Cosine
x3 <- -20:20
y3 <- cos(x3/4) + rnorm(41,0,0.2)
plot(y3~x3, type='p', pch=18)
cor(x3,y3)
distanceCorrelation(x3,y3)
MIC(x3,y3)
- Pearson’s r = - 0.035
- Distance Correlation = 0.382
- MIC = 0.484
Circle
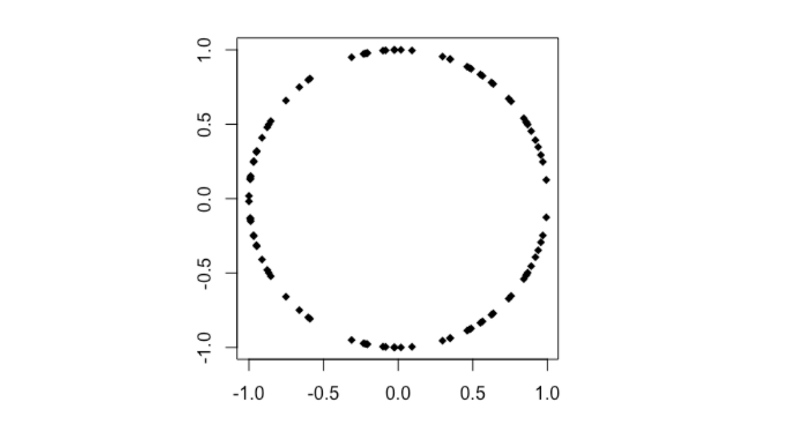
# Circle
n <- 50
theta <- runif (n, 0, 2*pi)
x4 <- append(cos(theta), cos(theta))
y4 <- append(sin(theta), -sin(theta))
plot(x4,y4, pch=18)
cor(x4,y4)
distanceCorrelation(x4,y4)
MIC(x4,y4)
- Pearson’s r < 0.001
- Distance Correlation = 0.234
- MIC = 0.218
Thanks for reading!