
By Tom Winter
We recently released DataFairy, a free tool that generates test data. But first, let me tell you the story of how it came about.
This is the story of how we turned a fun open source side project into something that has turned out to be really useful.
This is not about fake news or tricking the masses. But the fact remains that for developers, software testers, and really anyone who has ever given a demo, fake data is essential and is surprisingly difficult to make up off the top of your head.
Our story with fake data starts back when we first developed our SaaS tool, Devskiller. Like all applications, we needed users. We weren’t even looking for paying users at this point. We just needed candidate profiles for our application. What we needed was dummy data that looked real.
We needed a test data generator
We needed fake data for a couple of reasons:
1. We needed to see if our system worked
This meant that we needed to build a number of different dummy profiles to see if the system stored and displayed them correctly.
2. We needed to sell our product
We needed to do demos for our first prospective customers. We wanted to show our customers what the system would look like after 6 months of inviting and testing hundreds of candidates.
Our first thought was to look for an available test data generator. But the problem is that data is hard to fake convincingly. Just ask this guy,
or him,
A lot of data is validated algorithmically
If it was easy to make convincing data, we probably wouldn’t need a tool. But generating data can be tricky for a couple of reasons.
Fake data is more than just random numbers. Take the example of a credit card number. Most credit card numbers are based on something called a Luhn algorithm. To explain this we are going to use the example of a Visa card:

How to check if a credit card number is valid
Before you start, it’s important to know that all Visa card numbers start with a 4. Also, they all have either 16 or 13 digits.
Take this Visa card number:

The first thing you need to do to see if you can validate the number is to double the alternating digits starting with the first digit in the sequence.
4574487405351567
(4x2), (7x2), (4x2), (7x2), (0x2), (3x2), (1x2), (6x2)
8, 14, 8, 14, 0, 6, 2, 12
If the doubling that you’ve just done results in a number with two digits, add them together to get a single digit number.
8, 5, 8, 5, 0, 6, 2, 3
You then need to go back to the original credit card number and replace the digits that you doubled the new value.
8554885405652537
This could either be the doubles value or the table of values with the digits added together. Now add it all up.
8+5+5+4+8+8+5+4+0+5+6+5+2+5+3+7=80
And then check to see if the sum is evenly divisible by 10. In this case it is, so the number is valid.
You need some sort of computational algorithm to validate credit card numbers at scale. But credit card numbers are relatively easy pieces of data to get right. We didn’t just need individual pieces of verifiable data, we needed entire profiles.
Verifiable profiles need different kinds of data that relate to each other logically
Credit card numbers are relatively easy to generate, because they only relate to themselves. But personal identity numbers often relate to other things about a person. Take the Swedish personal identity number, practically called the personnummer.

For those of you who don’t know, personnummers are designed for paying taxes, sort of like an American Social Security number. But they’re also used as a way to access services like healthcare and schools as well as non-governmental services like credit ratings.
The format of a personnummer is slightly different than that of a credit card. It is a 10 digit number split into a six digit section and a four digit section connected by a hyphen.
Cool fact: Swedes over the age of 100 replace the hyphen in their personnummer with a plus sign.
The first six digits in the personnummer are simple and correspond to the person’s birthday using a YYMMDD format. Of the second 4 digit section, the first three are a serial number. The third serial number digit is odd for males and even for females. The last number is a checksum digit.
So if you take the personnummer:
601128–9235
You know that it is for a man born November 28th, 1960.
60(year)11(month)28(day)-(under 100 years old)92(unique numbers)3(unique odd number for male)5(checksum digit)
To calculate the checksum, multiply the individual digits in the identity number with the corresponding digits in the number 212121–212.
(6x2)(0x1)(1x2)(1x1)(2x2)(8x1)(9x2)(2x1)(3x2)
12, 0, 2, 1, 4, 8, 18, 2, 6
Just like with the Visa card above, if the product of any of these numbers results in a two digit number, simply add the two digits together.
3, 0, 2, 1, 4, 8, 9, 2, 6
Add all the remaining products together.
3+0+2+1+4+8+9+2+6=35
To get the checksum digit, subtract the last digit of the added products from 10 (the exception is that if the last digit is zero, the checksum is also zero).
10–5=5
So if you were going to generate a profile of this person, it couldn’t be of a woman born on April 10th, 1916. Her personnummer would have to be something like: 160410+1244. In other words, you couldn’t just come up with a random number and expect it to work with just any fake profile you’ve generated.
We needed logical test data
The data would need to relate to each other in a logical way, since the personnummer isn’t the only piece of data that is built on outside information. Most types of identification numbers relate to other information in some way. We simply couldn’t find a test data generator which would do that, so we decided to build our own. It looks like we weren’t the only one having this problem.
JFairy
As regular contributors the open source community, we decided that the best way to generate the test data we needed was to build our own library. Called JFairy, our goal was for it to generate sets of data that were all verifiable and logically connected.
This way we could populate our app with users. Our user data couldn’t be gibberish or else it couldn’t be imputed. So we put the library to work and it performed better than we could have expected. It even generates real people from time to time. We found this out because we used Gravatar to show the candidate pictures. We were surprised when a real photo appeared on our test account.

This was really useful when we started shopping around our app. We wanted to show enterprise clients an account with 300 different test candidates on the platform. If we hadn’t built JFairy, we might have all tried to use the app a few times, but there were only five of us on the team. It would have been impractical for the five of us to come up with 300 logically connected fake profiles.
The data generated by JFairy proved to be so convincing that new customers were puzzled as to where we had gotten all of these people to test. In fact, they asked us if we could help them with sourcing new developers, as clearly we were in touch with a number of people who have technical backgrounds, some of whom actually had validated skills.
We needed to let the open source community have a look at JFairy
We realized that this was becoming something bigger than ourselves, so we decided to put the system out on open source. The first reason is that we are all avid users of open source code. We know that it’s important to give back to that community in order to get things in return. But on top of that, open source can bring real benefits back to the product. By putting our project out there so that a number of different developers can take a look at it, we can get some new ideas that we would never have considered.
The most notable contributions were the inclusion of new languages. We only built JFairy to generate data for English speakers and Polish speakers. After all, we are rather limited by the languages we know well. But of course, it could be a useful tool for people from any number of different countries. Through open source contributions, we’ve been able to add support for data in Spanish, French, German, Swedish, and Chinese.
We also realized that while we’re reaching a great group of users in software developers, Jfairy had applications well beyond a community whose members know how to code. So we decided to build on the success of the library and create an app which could support its use for more applications and more people.
Data Fairy gives everyone access to fake data
JFairy proved to be super useful for developers who knew how to code, but they weren’t the only people out there who would use the data JFairy generated. Software testers need to be able to populate their systems to see if they work. Salespeople and marketers need data to make their demos look realistic. To make JFairy useful to the most people, we had to make its fake data easy to access.
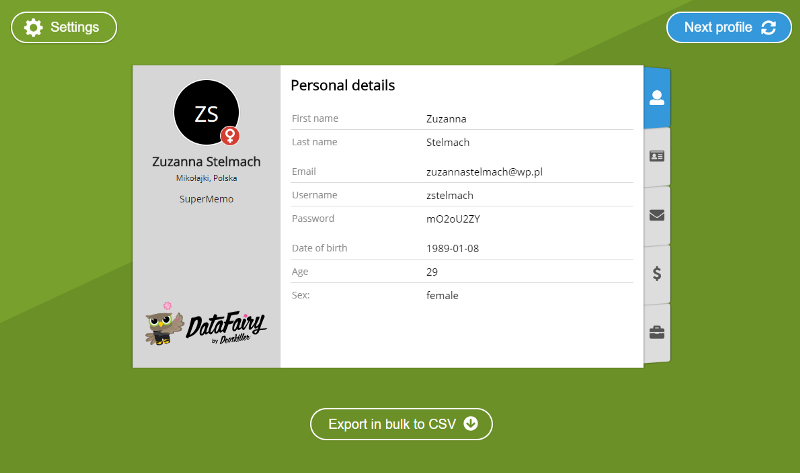
With that goal in mind, we built DataFairy. DataFairy is an app powered by JFairy so you can access our fake data without having to learn to code first. The data is presented in a neat notebook interface. To get more than one fake profile, you can either generate a new profile or export a bulk list of up to 100 profiles to a CSV file. It is a free and easy way to populate your software with logically connected valid data.

Our plans for DataFairy’s future
DataFairy can always be improved upon and have new features added to it. In addition to our own efforts, we want to stick to the tenants of the open source community. We continue to solicit new languages that we can add to our roster and we have an open GitHub project. We would also love to eventually have users add sample data. This will help us build a community of participants who will help DataFairy grow and become more useful for more people.
Whether you need to download large batches of logically validated data or simply want to have fun reading the profiles that pop up, check out DataFairy.