

Have you ever noticed that your network connection sometimes feels fast and then suddenly slow, even when nothing obvious has changed? A request that takes 20 ms at one moment can take 80 ms the next, and sometimes it does not return at all. Terms like RTT, jitter, and packet loss are often used to explain this behavior, but the real connection between them is easy to miss.
In this article, we’ll look at RTT, jitter, and packet loss as parts of a single timing system rather than separate metrics. You’ll start by understanding RTT and why it changes over time. Then you’ll learn how jitter emerges as an extra delay relative to a baseline. Finally, you’ll see how TCP uses this timing information to decide when delay turns into packet loss, with a focus on real protocol behaviour such as TLS and post-quantum TLS handshakes.
The goal is simple: to understand how timing turns into decisions.
Table of Contents
RTT (Round Trip Time)
Before talking about delay, jitter, or packet loss, we need to clearly understand what RTT is. If RTT is not clear, everything that comes after it becomes confusing.
RTT stands for Round Trip Time. It is the total time taken for a packet to travel from a client to a server and for the response to return to the client.
![RTT [Image Source: speedvitals.com ]](https://cdn-images-1.medium.com/max/1600/1*tKeOZNVYvkDuXMl4WytN5Q.jpeg)
Assuming you send a packet and receive the reply after 50 milliseconds, then the RTT is 50 ms. That is the basic definition.
But here is the important part: RTT is not a fixed number. It changes all the time. Even when you communicate with the same server, RTT can change from one packet to the next. This happens because the network is always changing, and this can be because of any of these reasons:
Packets waiting in queues
Temporary congestion
Scheduling inside routers
Background traffic on the same path
Let’s assume you connect to Google, and you send a packet now. In practice, RTT can be measured using simple tools. One common way is the ping command, which sends a packet and measures how long it takes for the reply to return.
ping -n 1 google.com

And here, you get the reply after 50 ms.
RTT = 50 ms
That value is real, but it is incomplete. A single RTT measurement does not tell us whether the network path itself takes 50 ms, or whether the path is faster and the packet experienced a small temporary delay along the way.
For example, the actual path delay might be 49 ms, with an additional 1 ms spent waiting in a queue. From a single RTT value, there is no way to separate these effects. RTT only makes sense after multiple measurements.
So, let’s measure multiple RTT values.

Now you can see a pattern. From the measurements:
min RTT ≈ 18 ms
max RTT ≈ 19 ms
average RTT ≈ 18 ms
That is why RTT is not something you magically know from one packet. It is something you observe over time.
But now, at this point, an important question comes up: Which of these RTT values represents the real network path?
When RTT is measured repeatedly, the values are not consistent. Some RTT measurements are small, some are larger, and some suddenly jump due to temporary network conditions.
You may see something like this: small, small, small, small, BIG. That is why we need a reference point, which we can call the stable point. Without it, every RTT value looks equally confusing, and we cannot tell whether a packet was slow because the path itself is slow or because something temporary happened.
Baseline RTT
That stable point is the baseline RTT. Baseline RTT means the minimum RTT observed over time. This represents the RTT without temporary effects.
For example, in the above example, our repeated measurements show minimum RTT ≈ 18 ms. 18 ms becomes our baseline RTT. You can think of baseline RTT as the fastest possible RTT for a given path, representing the calm state of the network where packets do not wait in queues, there is no congestion, and no retransmissions occur.
In other words, baseline RTT reflects what the network is capable of when nothing unusual is happening. The best happy case that usually excludes temporary effects.
Why Baseline RTT Matters
Once we have a baseline RTT, individual RTT measurements stop feeling random. We can see when an RTT is close to the baseline, when it is higher than expected, and when extra delay has been introduced by temporary network conditions.
Without a baseline RTT, each RTT value stands alone, and comparison becomes guesswork. With a baseline in place, RTT values gain meaning, variation becomes visible, and we are finally able to reason about what causes RTT to increase, which naturally leads to jitter.
This is the point where we are finally ready to talk about what causes RTT to increase, which leads naturally to jitter.
What is Jitter?
Now comes Jitter. Once we have a baseline RTT, something important becomes clear. Most RTT values are not equal to the baseline. They are usually higher.
So the next natural question is: If baseline RTT shows the calm network, what is causing the RTT to increase in the other measurements?
That extra part is what we call jitter.
What Jitter Actually Means
Jitter is the extra delay added on top of the baseline RTT. In simple words, baseline RTT shows what the network can do when nothing is wrong, while jitter describes what happens when the network becomes busy, and packets experience extra delay.
So every observed RTT can be thought of like this: Observed RTT = Baseline RTT + Extra Delay
Example
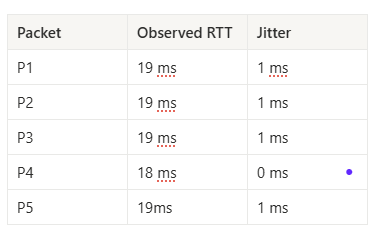
Baseline RTT = 18 ms. That extra delay is jitter.
There are two important points to remember. First, jitter is always positive because a packet can be delayed but can never arrive faster than the baseline RTT. Second, baseline RTT acts as the reference point, which means jitter only exists relative to that baseline. Without a baseline, jitter has no meaning.
Where Jitter Comes From
Jitter appears when packets do not move immediately through the network.
This usually happens because of:
Packets waiting in queues
Routers delaying packets before forwarding
Temporary congestion on links
Retransmissions after drops
These effects are not constant. They come and go. Because of that, jitter is irregular and bursty. Sometimes it is very small, and at other times it can suddenly become large.
What Jitter Tells Us
At this stage, jitter is still just an observation. It tells us how unstable the network timing is and how often packets experience extra delay. We are not making decisions yet. We are only describing what the network is doing.
How TCP Learns RTT and Jitter
We have seen that:
RTT changes over time
Baseline RTT gives us a reference
Jitter explains extra delay
So, up to this point, we have only been observing the network. But now a new question appears: If RTT keeps changing, and if delay and jitter exist, who is actually watching all this? More importantly, who decides when waiting is normal and when waiting becomes a problem?
This is the point where TCP enters the picture. TCP is the component that observes these timing changes and uses them to decide what to do next.
TCP Does Not Know RTT in Advance
TCP does not start with any knowledge of how long the path is, how stable the network will be, or how much delay to expect. It learns all of this dynamically while the connection is running.
TCP learns everything while the connection is running, only by looking at time. Every time TCP sends data and receives an acknowledgement, it gets one RTT sample. Over time, these samples are used to build expectations.
To make sense of these timing samples, TCP maintains two internal values that summarize what it has learned so far.
SRTT (Smoothed RTT)
SRTT is the RTT that TCP expects most of the time. It is not the minimum RTT, and it is not a simple average. It is a smoothed value that represents the normal RTT that the TCP has learned from recent history. This means recent RTT measurements matter more, while older RTT measurements gradually matter less.
Because of this, SRTT does not jump because of a single delayed packet. Instead, it adapts gradually as network conditions change.
For example, suppose TCP observes these RTT samples (in ms): 48, 50, 49, 51, 50.
Then TCP smooths these values into a stable expectation, such as: SRTT ≈ 50 ms.
You can think of SRTT as: The RTT that TCP believes is reasonable for this connection, based mostly on recent history. It is a memory-weighted average, biased toward recent RTT values.
RTTVAR (RTT Variance)
RTTVAR tells TCP how much RTT is changing. Now compare two situations.
Stable RTT
RTT samples: 49, 50, 51, 50
Because these values are close to each other, the variation is small, RTTVAR remains low, and TCP feels confident about its timing estimates.
Unstable RTT
RTT samples: 50, 52, 90, 48
Here, the sudden jump increases variation, causes RTTVAR to rise, and makes TCP less confident about its timing.
Why TCP Needs Both
SRTT alone is not enough for TCP to make reliable timing decisions. If TCP only knew that the RTT is around 50 ms, it would still have no way to tell whether delays are stable or whether sudden spikes are common.
RTTVAR fills this gap by capturing how much RTT changes over time. While SRTT tells TCP what RTT to expect under normal conditions, RTTVAR tells TCP how confident it should be in that expectation.
At this stage, TCP is still learning, not judging. It is building a timing model of the network.
So far, the network produces RTT variation, baseline RTT provides a calm reference, jitter explains extra delay, and TCP observes all of this using SRTT and RTTVAR.
TCP now has expectations. Only after this point does TCP start making decisions. And one of those decisions is packet loss.
How TCP Decides Packet Loss
Now that TCP has learned what RTT usually looks like and how much it varies, it has to answer one important question: How long should I wait before assuming a packet is gone?
This is where packet loss comes in.
TCP Never Sees a Packet Being Dropped
TCP does not see routers, queues, or links, and it does not know where packets go. TCP only sees time. It sends data and then waits.
If the acknowledgment arrives in time, everything is fine. If it does not, TCP must decide what to do next.
Retransmission Timeout (RTO)
To make this decision, TCP uses the Retransmission Timeout, or RTO. RTO is not random. It is computed from what TCP has already learned about network timing.
Conceptually, RTO is calculated as:
RTO=SRTT+max(𝐺,4×RTTVAR)
Here, SRTT sets the expected delay, while RTTVAR adds extra margin to account for jitter. As a result, RTO represents how long TCP is willing to wait, based on how uncertain the network timing is.
Suppose TCP has learned that the SRTT is 50 ms and the RTTVAR is 5 ms. In that case, the RTO becomes 70 ms.
RTO = 50 + 4 × 5
RTO = 70 ms
Now TCP behavior is simple:
ACK arrives at 60 ms → delay
ACK arrives at 75 ms → packet loss
The network is the same, and the packet is the same. Only the arrival time changes, and that alone leads to a different decision.
Delay vs Packet Loss
TCP logic is simple. If a packet arrives before the RTO expires, it is treated as delay. If it does not arrive before the RTO, TCP declares it lost.
This leads to an important rule: packet loss is a timing decision, not a certainty. The packet may still arrive later, but once the RTO expires, TCP has already acted.
How Jitter Turns Into Packet Loss
This behaviour connects directly to jitter. As long as jitter stays within the RTO window, packets are delayed but not considered lost. When jitter becomes large enough that delays cross the RTO boundary, TCP interprets delay as packet loss.
So packet loss does not always mean a packet disappeared. Often, it means the network timing has become too unpredictable.
Conclusion
At this point, everything connects: RTT, jitter, and packet loss are not separate network metrics. They describe different parts of the same timing process.
RTT shows how long communication usually takes.
Baseline RTT gives a stable reference.
Jitter explains why delays change.
Packet loss appears when that variation exceeds what the protocol can tolerate.
Once this flow is clear, network behavior stops feeling random. It becomes a matter of timing, uncertainty, and decisions.