
By Wolfgang Beyer
This isn’t a general introduction to Artificial Intelligence, Machine Learning or Deep Learning. There are already lots of great articles covering these topics (for example here or here).
And this isn’t a discussion about whether AI will enslave humankind or merely steal all our jobs. You can find plenty of speculation and some premature fearmongering elsewhere.
Instead, this post is a detailed description of how to get started in Machine Learning by building a system that is (somewhat) able to recognize what it sees in an image.
I’m currently on a journey to learn about Artificial Intelligence and Machine Learning. And the way I learn best is by not only reading stuff, but by actually building things and getting some hands-on experience. And that’s what this post is about. I want to show you how you can build a system that performs a simple computer vision task: recognizing image content.
I don’t claim to be an expert myself. I’m still learning, and there is a lot to learn. I’m describing what I’ve been playing around with, and if it’s somewhat interesting or helpful to you, that’s great! If, on the other hand, you find mistakes or have suggestions for improvements, please let me know, so that I can learn from you.
You don’t need any prior experience with machine learning to be able to follow along. The example code is written in Python, so a basic knowledge of Python would be great, but knowledge of any other programming language is probably enough.
Why image recognition?
Image recognition is a great task for developing and testing machine learning approaches. Vision is debatably our most powerful sense and comes naturally to us humans. But how do we actually do it? How does the brain translate the image on our retina into a mental model of our surroundings? I don’t think anyone knows exactly.
The point is, it’s seemingly easy for us to do — so easy that we don’t even need to put any conscious effort into it — but difficult for computers to do (Actually, it might not be that easy for us either, maybe we’re just not aware of how much work it is. More than half of our brain seems to be directly or indirectly involved in vision).
How can we get computers to do visual tasks when we don’t even know how we are doing it ourselves? That’s where machine learning comes into play. Instead of trying to come up with detailed step by step instructions of how to interpret images and translating that into a computer program, we’re letting the computer figure it out itself.
The goal of machine learning is to give computers the ability to do something without being explicitly told how to do it. We just provide some kind of general structure and give the computer the opportunity to learn from experience, similar to how we humans learn from experience too.
But before we start thinking about a full blown solution to computer vision, let’s simplify the task somewhat and look at a specific sub-problem which is easier for us to handle.
Image classification and the CIFAR-10 dataset
We will try to solve a problem which is as simple and small as possible while still being difficult enough to teach us valuable lessons. All we want the computer to do is the following: when presented with an image (with specific image dimensions), our system should analyze it and assign a single label to it. It can choose from a fixed number of labels, each being a category describing the image’s content. Our goal is for our model to pick the correct category as often as possible. This task is called image classification.
We will use a standardized dataset called CIFAR-10. CIFAR-10 consists of 60,000 images. There are 10 different categories and 6,000 images per category. Each image has a size of only 32 by 32 pixels. The small size makes it sometimes difficult for us humans to recognize the correct category, but it simplifies things for our computer model and reduces the computational load required to analyze the images.
 Random images from each of the 10 classes of the CIFAR-10 dataset. Because of their small resolution humans too would have trouble labeling all of them correctly.
Random images from each of the 10 classes of the CIFAR-10 dataset. Because of their small resolution humans too would have trouble labeling all of them correctly.
The way we input these images into our model is by feeding the model a whole bunch of numbers. Each pixel is described by three floating point numbers representing the red, green and blue values for this pixel. This results in 32 x 32 x 3 = 3,072 values for each image.
Apart from CIFAR-10, there are plenty of other image datasets which are commonly used in the computer vision community. Using standardized datasets serves two purposes. First, it is a lot of work to create such a dataset. You need to find the images, process them to fit your needs and label all of them individually. The second reason is that using the same dataset allows us to objectively compare different approaches with each other.
In addition, standardized image datasets have lead to the creation of computer vision high score lists and competitions. The most famous competition is probably the Image-Net Competition, in which there are 1000 different categories to detect. 2012’s winner was an algorithm developed by Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton from the University of Toronto (technical paper) which dominated the competition and won by a huge margin. This was the first time the winning approach was using a convolutional neural network, which had a great impact on the research community. Convolutional neural networks are artificial neural networks loosely modeled after the visual cortex found in animals. This technique had been around for a while, but at the time most people did not yet see its potential to be useful. This changed after the 2012 Image-Net competition. Suddenly there was a lot of interest in neural networks and deep learning (deep learning is just the term used for solving machine learning problems with multi-layer neural networks). That event plays a big role in starting the deep learning boom of the last couple of years.
Supervised Learning
How can we use the image dataset to get the computer to learn on its own? Even though the computer does the learning part by itself, we still have to tell it what to learn and how to do it. The way we do this is by specifying a general process of how the computer should evaluate images.
We’re defining a general mathematical model of how to get from input image to output label. The model’s concrete output for a specific image then depends not only on the image itself, but also on the model’s internal parameters. These parameters are not provided by us, instead they are learned by the computer.
The whole thing turns out to be an optimization problem. We start by defining a model and supplying starting values for its parameters. Then we feed the image dataset with its known and correct labels to the model. That’s the training stage. During this phase the model repeatedly looks at training data and keeps changing the values of its parameters. The goal is to find parameter values that result in the model’s output being correct as often as possible. This kind of training, in which the correct solution is used together with the input data, is called supervised learning. There is also unsupervised learning, in which the goal is to learn from input data for which no labels are available, but that’s beyond the scope of this post.
After the training has finished, the model’s parameter values don’t change anymore and the model can be used for classifying images which were not part of its training dataset.
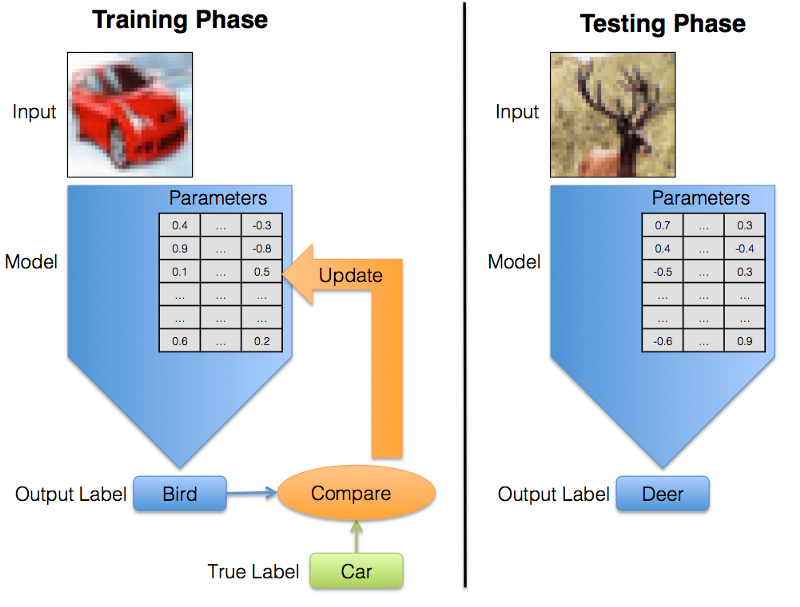 During training the model’s predictions are compared to their true values. This information is then used to update the parameters. During testing there is no feedback anymore, the model just generates labels.
During training the model’s predictions are compared to their true values. This information is then used to update the parameters. During testing there is no feedback anymore, the model just generates labels.
TensorFlow
TensorFlow is a open source software library for machine learning, which was released by Google in 2015 and has quickly become one of the most popular machine learning libraries being used by researchers and practitioners all over the world. We use it to do the numerical heavy lifting for our image classification model.
Building the Model, a Softmax Classifier
The full code for this model is available on Github. In order to use it, you need to have the following installed:
- Python (the code has been tested with Python 2.7, but Python 3.3+ should work too, Link to Installation Instructions)
- TensorFlow (Link to Installation Instructions)
- CIFAR-10 dataset: Download the Python version of the dataset from https://www.cs.toronto.edu/~kriz/cifar.html or use the direct link to the compressed archive. Place the extracted
cifar-10-batches-py/directory in the directory where you are putting the python source code, so that the path to the images is/path-to-your-python-source-code-files/cifar-10-batches-py/.
Alright, now we’re finally ready to go. Let’s look at the main file of our experiment, softmax.py and analyze it line by line:
The future-Statements should be present in all TensorFlow Python files to ensure compatibility with both Python 2 and 3 according to the TensorFlow style guide.
Then we are importing TensorFlow, numpy for numerical calculations, and the time module. data_helpers.py contains functions that help with loading and preparing the dataset.
We start a timer to measure the runtime and define some parameters. I’ll talk about them later when we’re actually using them. Then we load the CIFAR-10 dataset. Since reading the data is not part of the core of what we’re doing, I put these functions into the separate data_helpers.py file, which basically just reads the files containing the dataset and puts the data in a data structure which is easy to handle for us.
One thing is important to mention though. load_data() is splitting the 60000 images into two parts. The bigger part contains 50000 images. This training set is what we use for training our model. The other 10000 images are called test set. Our model never gets to see those until the training is finished. Only then, when the model’s parameters can’t be changed anymore, we use the test set as input to our model and measure the model’s performance on the test set.
This separation of training and testing data is very important. We wouldn’t know how well our model is able to make generalizations if it was exposed to the same dataset for training and for testing. In the worst case, imagine a model which exactly memorizes all the training data it sees. If we were to use the same data for testing it, the model would perform perfectly by just looking up the correct solution in its memory. But it would have no idea what to do with inputs which it hasn’t seen before.
This concept of a model learning the specific features of the training data and possibly neglecting the general features, which we would have preferred for it to learn is called overfitting. Overfitting and how to avoid it is a big issue in machine learning. More information about overfitting and why it is generally advisable to split the data into not only 2 but 3 different datasets can be found in this video (youtube mirror) (the video is part of Andrew Ng’s great free machine learning course on Coursera).
To get back to our code, load_data() returns a dictionary containing
images_train: the training dataset as an array of 50,000 by 3,072 (= 32 pixels x 32 pixels x 3 color channels) values.labels_train: 50000 labels for the training set (each a number between 0 nad 9 representing which of the 10 classes the training image belongs to)images_test: test set (10,000 by 3,072)labels_test: 10,000 labels for the test setclasses: 10 text labels for translating the numerical class value into a word (0 for ‘plane’, 1 for ‘car’, etc.)
Now we can start building our model. The actual numerical computations are being handled by TensorFlow, which uses a fast and efficient C++ backend to do this. TensorFlow wants to avoid repeatedly switching between Python and C++ because that would slow down our calculations.
The common workflow is therefore to first define all the calculations we want to perform by building a so-called TensorFlow graph. During this stage no calculations are actually being performed, we are merely setting the stage. Only afterwards we run the calculations by providing input data and recording the results.
So let’s start defining our graph. We first describe the way our input data for the TensorFlow graph looks like by creating placeholders. These placeholders do not contain any actual data, they just specify the input data’s type and shape.
For our model, we’re first defining a placeholder for the image data, which consists of floating point values (tf.float32). The shape argument defines the input dimensions. We will provide multiple images at the same time (we will talk about those batches later), but we want to stay flexible about how many images we actually provide. The first dimension of shape is therefore None, which means the dimension can be of any length. The second dimension is 3,072, the number of floating point values per image.
The placeholder for the class label information contains integer values (tf.int64), one value in the range from 0 to 9 per image. Since we’re not specifying how many images we’ll input, the shape argument is [None].
weights and biases are the variables we want to optimize. But let’s talk about our model first.
Our input consists of 3,072 floating point numbers and the desired output is one of 10 different integer values. How do we get from 3,072 values to a single one? Let’s start at the back. Instead of a single integer value between 0 and 9, we could also look at 10 score values — one for each class — and then pick the class with the highest score. So our original question now turns into: How do we get from 3,072 values to 10?
The simple approach which we are taking is to look at each pixel individually. For each pixel (or more accurately each color channel for each pixel) and each possible class, we’re asking whether the pixel’s color increases or decreases the probability of that class.
Let’s say the first pixel is red. If images of cars often have a red first pixel, we want the score for car to increase. We achieve this by multiplying the pixel’s red color channel value with a positive number and adding that to the car-score. Accordingly, if horse images never or rarely have a red pixel at position 1, we want the horse-score to stay low or decrease. This means multiplying with a small or negative number and adding the result to the horse-score.
For each of the 10 classes we repeat this step for each pixel and sum up all 3,072 values to get a single overall score, a sum of our 3,072 pixel values weighted by the 3,072 parameter weights for that class. In the end we have 10 scores, one for each class. Then we just look at which score is the highest, and that’s our class label.
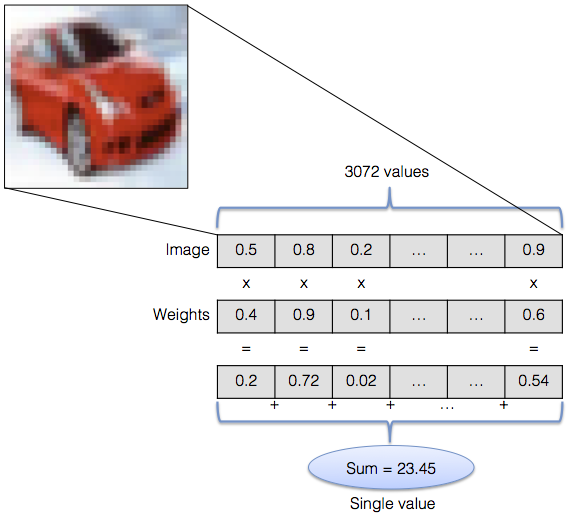 An image is represented by a linear array of 3,072 values. Each value is multiplied by a weight parameter and the results are summed up to arrive at a single result — the image’s score for a specific class.
An image is represented by a linear array of 3,072 values. Each value is multiplied by a weight parameter and the results are summed up to arrive at a single result — the image’s score for a specific class.
The notation for multiplying the pixel values with weight values and summing up the results can be drastically simplified by using matrix notation. Our image is represented by a 3,072-dimensional vector. If we multiply this vector with a 3,072 x 10 matrix of weights, the result is a 10-dimensional vector containing exactly the weighted sums we are interested in.
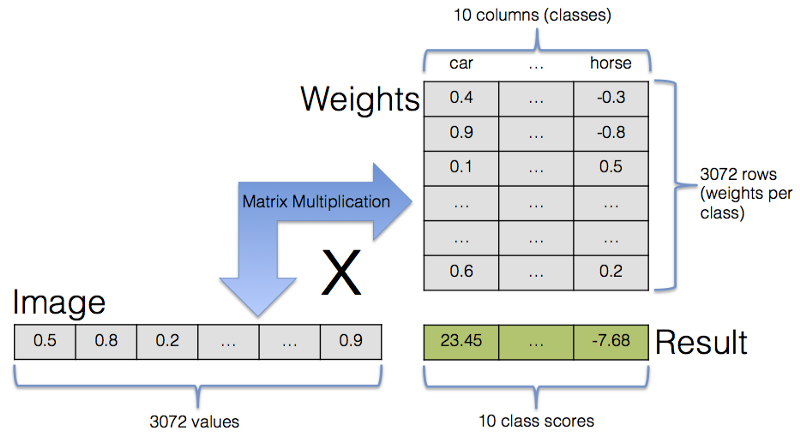 Calculating an image’s class values for all 10 classes in a single step via matrix multiplication.
Calculating an image’s class values for all 10 classes in a single step via matrix multiplication.
The actual values in the 3,072 x 10 matrix are our model parameters. If they are random/garbage our output will be random/garbage. That’s where the training data comes into play. By looking at the training data we want the model to figure out the parameter values by itself.
All we’re telling TensorFlow in the two lines of code shown above is that there is a 3,072 x 10 matrix of weight parameters, which are all set to 0 in the beginning. In addition, we’re defining a second parameter, a 10-dimensional vector containing the bias. The bias does not directly interact with the image data and is added to the weighted sums. The bias can be seen as a kind of starting point for our scores.
Think of an image which is totally black. All its pixel values would be 0, therefore all class scores would be 0 too, no matter how the weights matrix looks like. Having biases allows us to start with non-zero class scores.
This is where the prediction takes place. We’ve arranged the dimensions of our vectors and matrices in such a way that we can evaluate multiple images in a single step. The result of this operation is a 10-dimensional vector for each input image.
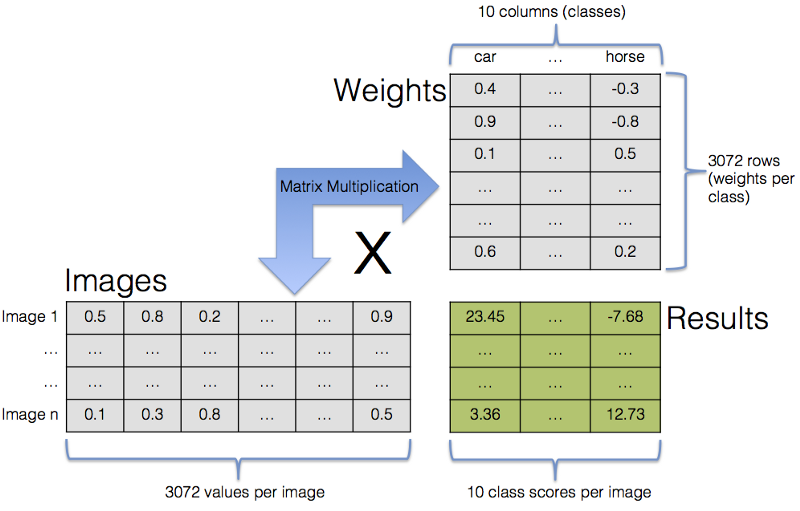 Calculating class values for all 10 classes for multiple images in a single step via matrix multiplication.
Calculating class values for all 10 classes for multiple images in a single step via matrix multiplication.
The process of arriving at good values for the weights and bias parameters is called training and works as follows: First, we input training data and let the model make a prediction using its current parameter values. This prediction is then compared to the correct class labels. The numerical result of this comparison is called loss. The smaller the loss value, the closer the predicted labels are to the correct labels and vice versa.
We want to model to minimize the loss, so that its predictions are close to the true labels. But before we look at the loss minimization, let’s take a look at how the loss is calculated.
The scores calculated in the previous step, stored in the logits variable, contains arbitrary real numbers. We can transform these values into probabilities (real values between 0 and 1 which sum to 1) by applying the softmax function, which basically squeezes its input into an output with the desired attributes. The relative order of its inputs stays the same, so the class with the highest score stays the class with the highest probability. The softmax function’s output probability distribution is then compared to the true probability distribution, which has a probability of 1 for the correct class and 0 for all other classes.
We use a measure called cross-entropy to compare the two distributions (a more technical explanation can be found here). The smaller the cross-entropy, the smaller the difference between the predicted probability distribution and the correct probability distribution. This value represents the loss in our model.
Luckily TensorFlow handles all the details for us by providing a function that does exactly what we want. We compare logits, the model’s predictions, with labels_placeholder, the correct class labels. The output of sparse_softmax_cross_entropy_with_logits() is the loss value for each input image. We then calculate the average loss value over the input images.
But how can we change our parameter values to minimize the loss? This is where TensorFlow works its magic. Via a technique called auto-differentiation it can calculate the gradient of the loss with respect to the parameter values. This means that it knows each parameter’s influence on the overall loss and whether decreasing or increasing it by a small amount would reduce the loss. It then adjusts all parameter values accordingly, which should improve the model’s accuracy. After this parameter adjustment step the process restarts and the next group of images are fed to the model.
TensorFlow knows different optimization techniques to translate the gradient information into actual parameter updates. Here we use a simple option called gradient descent which only looks at the model’s current state when determining the parameter updates and does not take past parameter values into account.
Gradient descent only needs a single parameter, the learning rate, which is a scaling factor for the size of the parameter updates. The bigger the learning rate, the more the parameter values change after each step. If the learning rate is too big, the parameters might overshoot their correct values and the model might not converge. If it is too small, the model learns very slowly and takes too long to arrive at good parameter values.
The process of categorizing input images, comparing the predicted results to the true results, calculating the loss and adjusting the parameter values is repeated many times. For bigger, more complex models the computational costs can quickly escalate, but for our simple model we need neither a lot of patience nor specialized hardware to see results.
These two lines measure the model’s accuracy. argmax of logits along dimension 1 returns the indices of the class with the highest score, which are the predicted class labels. The labels are then compared to the correct class labels by tf.equal(), which returns a vector of boolean values. The booleans are cast into float values (each being either 0 or 1), whose average is the fraction of correctly predicted images.
We’re finally done defining the TensorFlow graph and are ready to start running it. The graph is launched in a session which we can access via the sess variable. The first thing we do after launching the session is initializing the variables we created earlier. In the variable definitions we specified initial values, which are now being assigned to the variables.
Then we start the iterative training process which is to be repeated max_steps times.
These lines randomly pick a certain number of images from the training data. The resulting chunks of images and labels from the training data are called batches. The batch size (number of images in a single batch) tells us how frequent the parameter update step is performed. We first average the loss over all images in a batch, and then update the parameters via gradient descent.
If instead of stopping after a batch, we first classified all images in the training set, we would be able to calculate the true average loss and the true gradient instead of the estimations when working with batches. But it would take a lot more calculations for each parameter update step. At the other extreme, we could set the batch size to 1 and perform a parameter update after every single image. This would result in more frequent updates, but the updates would be a lot more erratic and would quite often not be headed in the right direction.
Usually an approach somewhere in the middle between those two extremes delivers the fastest improvement of results. For bigger models memory considerations are very relevant too. It’s often best to pick a batch size that is as big as possible, while still being able to fit all variables and intermediate results into memory.
Here the first line of code picks batch_size random indices between 0 and the size of the training set. Then the batches are built by picking the images and labels at these indices.
Every 100 iterations we check the model’s current accuracy on the training data batch. To do this, we just need to call the accuracy-operation we defined earlier.
This is the most important line in the training loop. We tell the model to perform a single training step. We don’t need to restate what the model needs to do in order to be able to make a parameter update. All the info has been provided in the definition of the TensorFlow graph already. TensorFlow knows that the gradient descent update depends on knowing the loss, which depends on the logits which depend on weights, biases and the actual input batch.
We therefore only need to feed the batch of training data to the model. This is done by providing a feed dictionary in which the batch of training data is assigned to the placeholders we defined earlier.
After the training is completed, we evaluate the model on the test set. This is the first time the model ever sees the test set, so the images in the test set are completely new to the model. We’re evaluating how well the trained model can handle unknown data.
The final lines print out how long it took to train and run the model.
Results
Let’s run the model with with the command “python softmax.py”. Here is how my output looks like:
Step 0: training accuracy 0.14 Step 100: training accuracy 0.32 Step 200: training accuracy 0.3 Step 300: training accuracy 0.23 Step 400: training accuracy 0.26 Step 500: training accuracy 0.31 Step 600: training accuracy 0.44 Step 700: training accuracy 0.33 Step 800: training accuracy 0.23 Step 900: training accuracy 0.31 Test accuracy 0.3066 Total time: 12.42s
What does this mean? The accuracy of evaluating the trained model on the test set is about 31%. If you run the code yourself, your result will probably be around 25–30%. So our model is able to pick the correct label for an image it has never seen before around 25–30% of the time. That’s not bad!
There are 10 different labels, so random guessing would result in an accuracy of 10%. Our very simple method is already way better than guessing randomly. If you think that 25% still sounds pretty low, don’t forget that the model is still pretty dumb. It has no notion of actual image features like lines or even shapes. It looks strictly at the color of each pixel individually, completely independent from other pixels. An image shifted by a single pixel would represent a completely different input to this model. Considering this, 25% doesn’t look too shabby anymore.
What would happen if we trained for more iterations? That would probably not improve the model’s accuracy. If you look at results, you can see that the training accuracy is not steadily increasing, but instead fluctuating between 0.23 and 0.44. It seems to be the case that we have reached this model’s limit and seeing more training data would not help. This model is not able to deliver better results. In fact, instead of training for 1000 iterations, we would have gotten a similar accuracy after significantly fewer iterations.
One last thing you probably noticed: the test accuracy is quite a lot lower than the training accuracy. If this gap is quite big, this is often a sign of overfitting. The model is then more finely tuned to the training data it has seen, and it is not able to generalize as well to previously unseen data.
This post has turned out to be quite long already. I’d like to thank you for reading it all (or for skipping right to the bottom)! I hope you found something of interest to you, whether it’s how a machine learning classifier works or how to build and run a simple graph with TensorFlow. Of course, there is still a lot of material that I would like to add. So far, we have only talked about the softmax classifier, which isn’t even using any neural nets.
My next blog post changes that: Find out how much using a small neural network model can improve the results! Read it here.
Thanks for reading. You can also check out other articles I’ve written on my blog.