
By Zhen Liu
When processing data using the Pandas library in Python, are you always confused when it comes to loc and iloc, or map, apply and applymap? Want to quickly select the subset you need and create some new features before creating your machine learning models? Use this tutorial to practice every morning for 10 mins, and repeating it for a week.
It’s like doing a few small crunches a day — not for your abs, but for your data science muscles. Gradually, you’ll notice the change.
Following my previous “Data Science Workout” on data preprocessing, in this tutorial we’ll focus on 1) subsetting data and 2) creating new features.
content:1) slicing and dicing data to create your feature matrix (loc, iloc and etc)
2)assign, map and transform data to the ideal scale or label for modeling(map, apply, applymap and more)
First, load the libraries and Zillow data for our exercise:
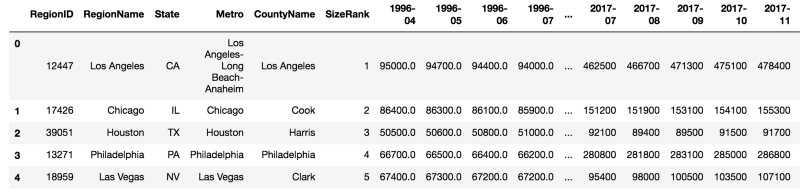
1. Slicing and dicing data
1.1 Slicing Columns
What is loc and iloc?
In pandas, loc and iloc are two ways you can select rows and columns by label(s) or a Boolean array.
.loc[]: you use row’s index (can be both integer and string. Depends on what the index is, for example index can be names, and can be a number), and column name for indexing (can’t use integer to index column location).
.iloc[] : you can only use integers to do position-based indexing.
Example: select columns by names using .loc[]:
The two expressions above give you the same result as below.

What if I want to select the first 5 columns?
Now we use .iloc[]: it slices columns or rows by location.

Confused with loc() already? Don’t worry — I’ll show you more examples! But keep in mind, .loc[] -> index based vs .iloc[] -> position based.
1.2 Slicing Rows
Select rows using index by .loc[] (the current index in the dataframe is the row number assigned automatically, it starts with 1).

Select rows using location by .iloc[]:
If you are selecting the 2nd, 3rd and 5th rows in order (remember Python counts from 0 when it works in location, so it’s [1,2,4])
1.3 Select both columns and rows
Using iloc to get 1–5 rows, and the first 6 columns by location, can be achieved using loc by using row index and column names. Remember that Python does not slice inclusive of the ending index, so .iloc[1:6, …] only select row 1–5 by position, while .loc[1:5, …]:

What’s the difference between iloc and loc?
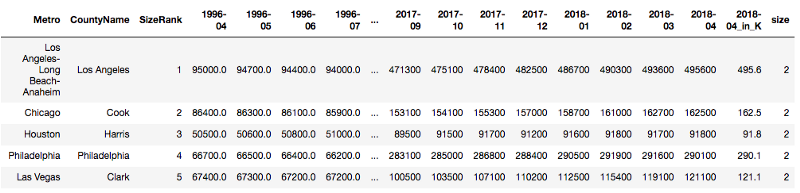
To demonstrate the difference better, we change the index from the default order to ‘SizeRank’ column, which is the rank of the size of the region.
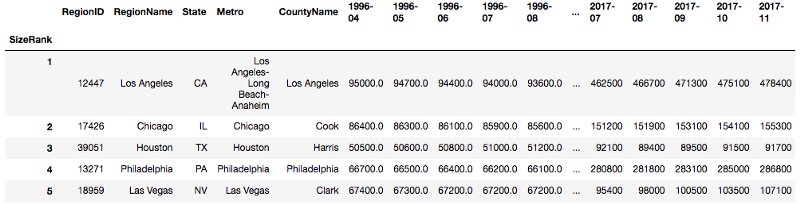
Select by index [1,2,4]: it gives you the rows with index (size rank) that is 1,2,4.
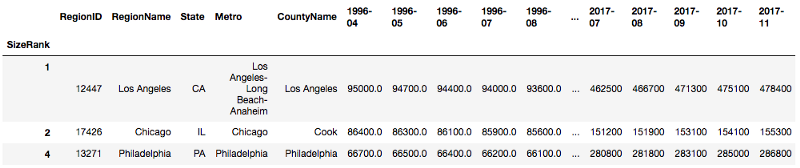
Select using location [1,2,4]:

1.4 Get one specific cell by location
1.5 Example in machine learning process: slicing data for features matrix (X), and response vector (y)
If you want to see whether monthly rent can be used as training data to identify which state it is, then your X is the monthly rent, and Y is state (just giving an example of slicing data for features and response variable, you can try to see whether this prediction will work).
dataframe.values give you the form of an array, which you can use directly in sklearn (like the new X and y in line 16–17 ).
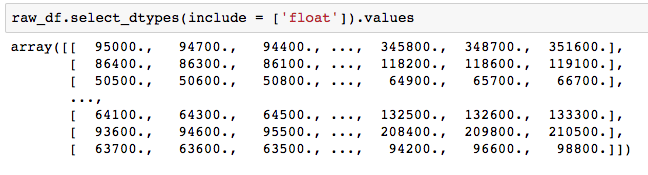
1.6 Subset based on conditions
If we want to select the top 10 biggest regions:
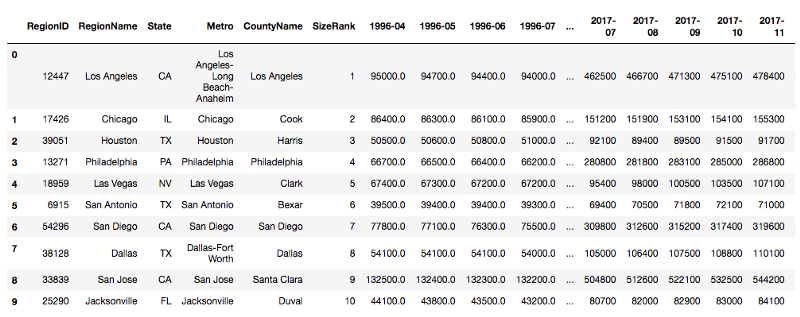
Other variations:
What happens if we apply a rule on the entire dataframe? It won’t filter out rows or columns but will show NA for the cells that don’t meet the requirements:
If we filter with a variation of a columns’s value:
What’s a lambda function?
Lambda functions can be used wherever function objects are required. It’s anonymous, but you can assign a variable to it, for example:
you can set f = lambda x: max(x)- min(x). Here we filter the regions when SizeRank is an even number.

Use lambda to apply a rule on more than one column:

Examples on filter both columns and rows
It gives an error if we run raw_df[raw_df.loc[0]>450000] because there are non-numeric columns like state or city. Using what we learned from my last article, we select numerical columns only.

If we want to select the data ranked top 5 in size, and only keep the months when the rent is greater than 450,000 for the first row [index==0]

Now we get back to use raw_df with all the columns, and select the data ranked top 5 in size, and only keep the string columns this time.

For this type of filtering to work, the 2 elements inside the [] have to each yield a series of Boolean results (true, false) on their own. Otherwise it won’t work.
For example:
num_df.loc[num_df['SizeRank']<=5, num_df.loc[0:3]>450000.0]
will fail, because num_df.loc[0:3]>450000.0 doesn’t give a series of Booleans, it’s an array of Booleans.
Format like df.loc[df.A>0, df.loc[‘index’]>0] will work because it only deals with one row and one column, so it’s selecting by 2 series of booleans.
Be careful of the syntax!
It gives an error because this format will assume it’s rows but the command is actually selecting columns. .loc[]needs a : on the left side, if the condition is about columns.
If the condition is about rows, you can ignore the : on the right side.
2. Assign, map and transform data to the ideal scale
2.1. Assign Values
Use .copy() if you want to copy the data for some transformation while still keeping the original data untouched.
We are going to use this copied dataframe to practice assigning values.
- Assign values to rows use
.loc[]or.iloc[]
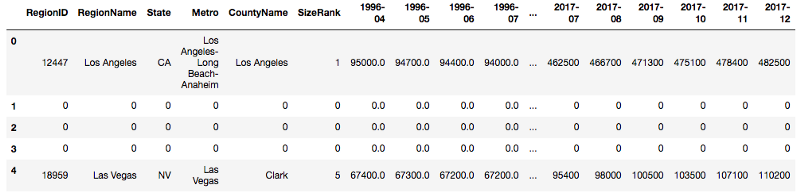
- Assign values to columns
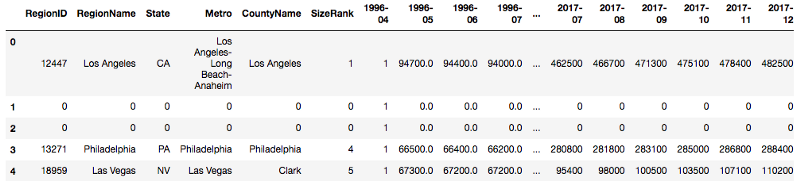
- Create a new column by assigning values by condition
Create a new column by using existing columns: Map or Apply
- Map: if too mange columns need to change values through creating a dictionary

2.2 Map: it iterates over each element of a series, but only one series. We can use map to change values in one column.
For example: when we index a column like this: raw_df[‘2018–04’], it is a series; so we can use map to change the value’s unit in 2018–04 to ‘thousand’ by multiplying 0.001 in this series:
If we want to change more than one column to thousands, use applymap.
2.3 ApplyMap: This helps to apply a function to each ELEMENT of the dataframe.
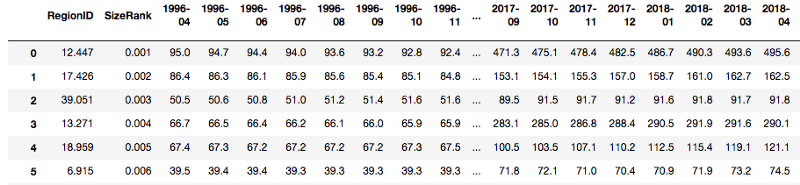
2.4 Apply: use if we need to apply for one or more columns more specifically.
As the name suggests, it applies a function ALONG any axis of the DataFrame.

Review: what’s the difference between map, appymap and apply?
map: operation on every element in one series, or one column of a df
applymap: every element in a df (same operation for elements in all the columns and rows)
apply: an operation that takes multiple columns from a df
Special form of apply:df[['col1','col2']].apply(sum) : it will return the sum of all the values of column1 and column2.
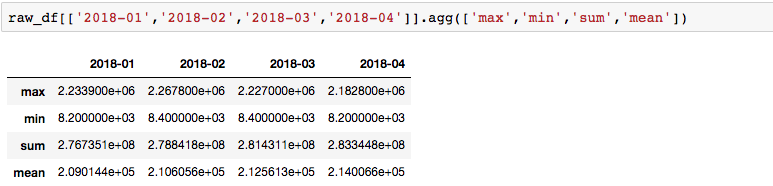
- Special form of apply in pandas to get aggregated value:

Or use agg to get more types of descriptive statistics:
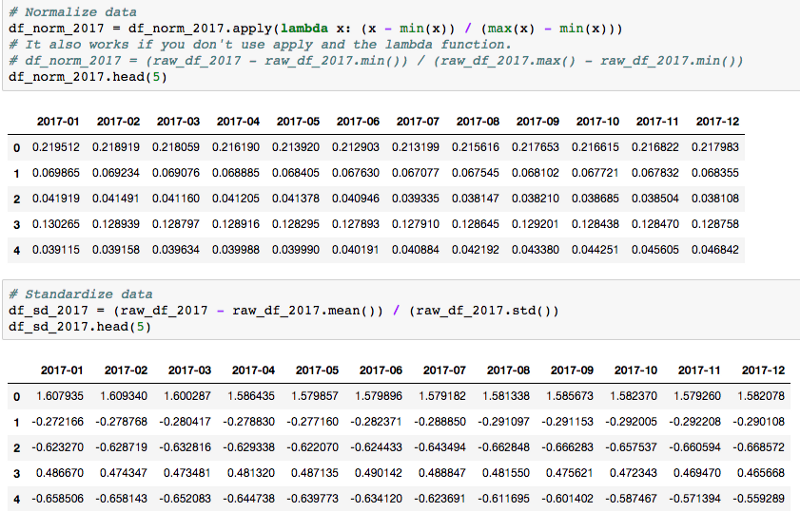
2.4 Use apply to rescale data for machine learning:
Normalize and Standardize data in Python (you can use standard scaler from sklearn, but this is the concept).
That’s it for the second part of my series on building muscle memory for data science in Python. The first part is linked at the end.
Stay tuned! My next tutorial will show you how to ‘curl the data science muscles’ for joining and pivoting data.
Follow me and give me a few claps if you find this helpful :)
You might also be interested in my analysis on rental seasonality:
How to Analyze Rental Seasonality and Trend to Save Money on Your Lease
_When I was looking for a new apartment to rent, I started to wonder: is there any seasonality impact? Is there a month…_medium.freecodecamp.org