
By Kavita Ganesan
Back in 2006, when I had to use TF-IDF for keyword extraction in Java, I ended up writing all of the code from scratch. Neither Data Science nor GitHub were a thing back then and libraries were just limited.
The world is much different today. You have several libraries and open-source code repositories on Github that provide a decent implementation of TF-IDF. If you don’t need a lot of control over how the TF-IDF math is computed, I highly recommend re-using libraries from known packages such as Spark’s MLLib or Python’s scikit-learn.
The one problem that I noticed with these libraries is that they are meant as a pre-step for other tasks like clustering, topic modeling, and text classification. TF-IDF can actually be used to extract important keywords from a document to get a sense of what characterizes a document. For example, if you are dealing with Wikipedia articles, you can use tf-idf to extract words that are unique to a given article. These keywords can be used as a very simple summary of a document, and for text-analytics when we look at these keywords in aggregate.
In this article, I will show you how you can use scikit-learn to extract keywords from documents using TF-IDF. We will specifically do this on a stack overflow dataset. If you want access to the full Jupyter Notebook, please head over to my repo.
Important note: I’m assuming that folks following this tutorial are already familiar with the concept of TF-IDF. If you are not, please familiarize yourself with the concept before reading on. There are a couple of videos online that give an intuitive explanation of what it is. For a more academic explanation I would recommend my Ph.D advisor’s explanation.
Dataset
In this example, we will be using a Stack Overflow dataset which is a bit noisy and simulates what you could be dealing with in real life. You can find this dataset in my tutorial repo.
Notice that there are two files. The larger file, stackoverflow-data-idf.json with 20,000 posts, is used to compute the Inverse Document Frequency (IDF). The smaller file, stackoverflow-test.json with 500 posts, would be used as a test set for us to extract keywords from. This dataset is based on the publicly available Stack Overflow dump from Google’s Big Query.
Let’s take a peek at our dataset. The code below reads a one per line json string from data/stackoverflow-data-idf.json into a pandas data frame and prints out its schema and total number of posts.
Here, lines=True simply means we are treating each line in the text file as a separate json string.

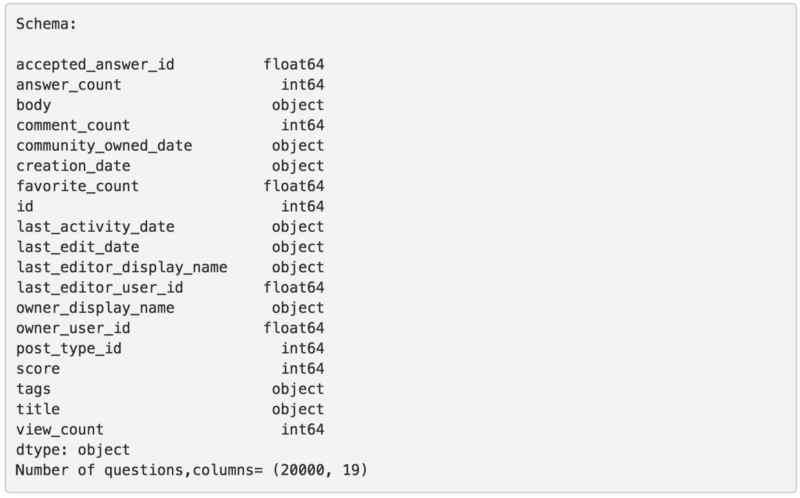
Notice that this Stack Overflow dataset contains 19 fields including post title, body, tags, dates, and other metadata which we don’t need for this tutorial. For this tutorial, we are mostly interested in the body and title. These will become our source of text for keyword extraction.
We will now create a field that combines both body and title so we have the two in one field. We will also print the second text entry in our new field just to see what the text looks like.

Uh oh, this doesn’t look very readable! Well, that’s because of all the cleaning that went on in pre_process(..). You can do a lot more stuff in pre_process(..), such as eliminate all code sections, and normalize the words to its root. For simplicity, we will perform only some mild pre-processing.
Creating vocabulary and word counts for the IDF
We now need to create the vocabulary and start the counting process. We can use the CountVectorizer to create a vocabulary from all the text in our df_idf['text'] , followed by the counts of words in the vocabulary:
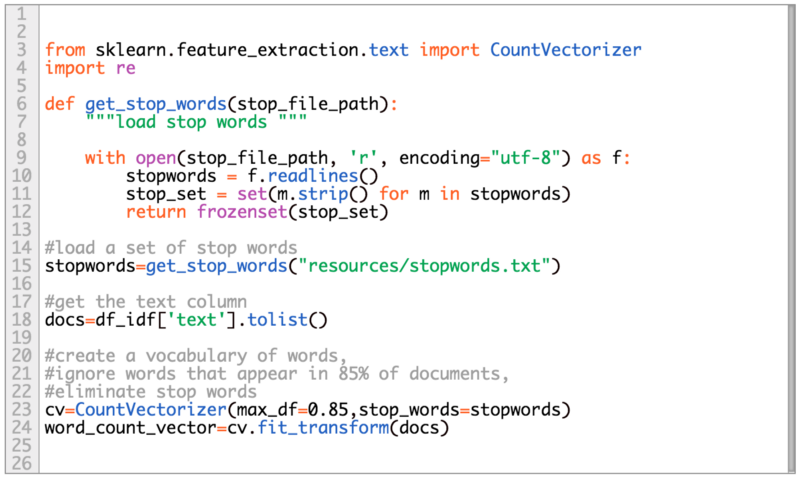
The result of the last two lines from the code above is a sparse matrix representation of the counts. Each column represents a word in the vocabulary. Each row represents the document in our dataset, where the values are the word counts.
Note that, with this representation, counts of some words could be 0 if the word did not appear in the corresponding document.
Here we are passing two parameters to CountVectorizer, max_df and stop_words. The first is just to ignore all words that have appeared in 85% of the documents, since those may be unimportant. The later is a custom stop words list. You can also use stop words that are native to sklearn by setting stop_words='english'. The stop word list used for this tutorial can be found here.
The resulting shape of word_count_vector is (20000,124901) since we have 20,000 documents in our dataset (the rows) and the vocabulary size is 124,901.
In some text mining applications, such as clustering and text classification, we typically limit the size of the vocabulary. It’s really easy to do this by setting max_features=vocab_size when instantiating CountVectorizer. For this tutorial let’s limit our vocabulary size to 10,000:

Now, let’s look at 10 words from our vocabulary:

['serializing', 'private', 'struct', 'public', 'class', 'contains', 'properties', 'string', 'serialize', 'attempt']
Sweet, these are mostly programming-related.
TfidfTransformer to compute the IDF
It’s now time to compute the IDF values.
In the code below, we are essentially taking the sparse matrix from CountVectorizer (word_count_vector) to generate the IDF when you invoke fit(...) :

Extremely important point: the IDF should always be based on a large corpora, and should be representative of texts you would be using to extract keywords. I’ve seen several articles on the Web that compute the IDF using a handful of documents. You will defeat the whole purpose of IDF weighting if its not based on a large corpora as:
- your vocabulary becomes too small, and
- you have limited ability to observe the behavior of words that you do know about.
Computing TF-IDF and extracting keywords
Once we have our IDF computed, we are ready to compute TF-IDF and then extract top keywords from the TF-IDF vectors.
In this example, we will extract the top keywords for the questions in data/stackoverflow-test.json. This data file has 500 questions with fields identical to that of data/stackoverflow-data-idf.json as we saw above. We will start by reading our test file, extracting the necessary fields — title and body — and getting the texts into a list.

The next step is to compute the tf-idf value for a given document in our test set by invoking tfidf_transformer.transform(...). This generates a vector of tf-idf scores.
Next, we sort the words in the vector in descending order of tf-idf values and then iterate over to extract the top-n keywords. In the example below, we are extracting keywords for the first document in our test set.
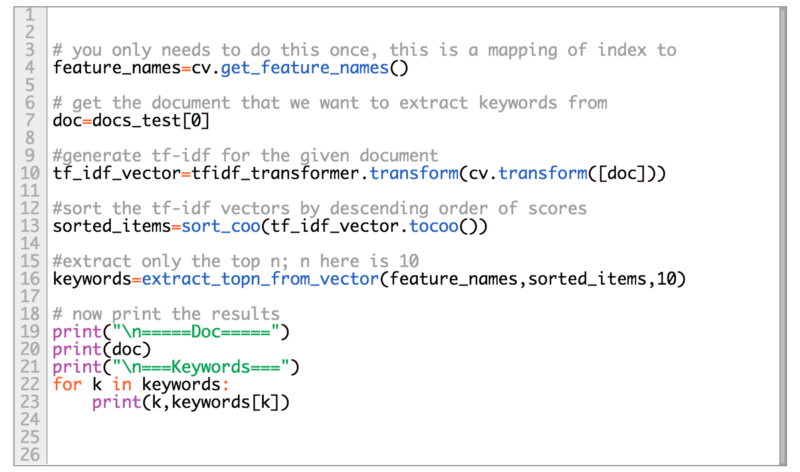

The sort_coo(...) method essentially sorts the values in the vector while preserving the column index. Once you have the column index then it’s really easy to look-up the corresponding word value as you would see in extract_topn_from_vector(...) where we do feature_vals.append(feature_names[idx]).
Some results!
In this section, you will see the stack overflow question followed by the corresponding extracted keywords.
Question about Eclipse Plugin integration

From the keywords above, the top keywords actually make sense, it talks about eclipse, maven, integrate, war, and tomcat, which are all unique to this specific question.
There are a couple of keywords that could have been eliminated such as possibility and perhaps even project. You can do this by adding more common words to your stop list. You can even create your own set of stop list, very specific to your domain.
Now let’s look at another example.
Question about SQL import

Even with all the html tags, because of the pre-processing, we are able to extract some pretty nice keywords here. The last word appropriately would qualify as a stop word. You can keep running different examples to get ideas of how to fine-tune the results.
Voilà! Now you can extract important keywords from any type of text!
Resources
- Full source code and dataset for this tutorial
- Stack overflow data on Google’s BigQuery
Follow my blog to learn more Text Mining, NLP and Machine Learning from an applied perspective.
This article was originally published at kavita-ganesan.com.