By Alireza Alidousti
In this article, we will build a scheduler in Reason. Along the way, we will see how some of the core features of Reason interact with each other and make it an excellent fit for this project. You can find everything we cover here in the repository.
Most articles about Reason show how it works in ReasonReact. This makes sense, since Facebook developed Reason. In this article, however, I wanted to show how Reason shines as a language outside of ReasonReact.
This article assumes you have a basic to intermediate understanding of JavaScript. Some familiarity with Functional Programming wouldn’t hurt either.
 _[pixelated background with Imagemagick](https://reasonml.github.io/img/reason.svg" rel="noopener" target="_blank" title="">reason.svg converted to png with Imagemagic, <a href="https://stackoverflow.com/a/506662" rel="noopener" target="blank" title=")
_[pixelated background with Imagemagick](https://reasonml.github.io/img/reason.svg" rel="noopener" target="_blank" title="">reason.svg converted to png with Imagemagic, <a href="https://stackoverflow.com/a/506662" rel="noopener" target="blank" title=")
Why choose Reason?
Reason is a functional language, that encourages immutability, provides an inferred static type system, and compiles down to JavaScript. Let’s take a closer look:
- Reason and OCaml share the same semantics. And so the functional programming constructs available in OCaml such as pattern matching and currying directly translate to Reason.
- In Reason, almost always you don’t have to write down the types — the compiler infers the types for you. For example, the compiler sees this
() => {1 +1} as a function that takesa unit (no argument) and returnsanint. - Most constructs in Reason are immutable.
Listis immutable.Arrayis mutable but has fixed size. Adding a new element to an array returns a copy of the array extended with the new element.Records (similar to JavaScript objects) are immutable. - BuckleScript compiles Reason down to JavaScript. You can work with JavaScript in your Reason code and use your Reason modules in JavaScript.
Reason brings the benefits of a strongly typed language to a JavaScript at a low cost. You should definitely read the What and Why section of the documentation, as it provides more context into the language and its features.
Some resources to help you get started
- Reason’s official docs are simple and to the point
- Exploring ReasonML, a book by Dr. Axel Rauschmayer, explores Reason in a more practical way
- BuckleScript docs talks in detail about interoperability with JavaScript and OCaml
In this article, we will explore how different concepts in Reason such as Modules, Statements, Variable Bindings and Immutability work together. Whenever I introduce a new concept or syntax, I will link to the related docs and articles.
The big picture
This tutorial was inspired by Node Schedule, a scheduler for Node.js that uses a single timer at all times. You can learn more about how Node Schedule works here.
Today we are going to create a scheduler in Reason that uses a single timer at all times. We will use our scheduler to execute recurring jobs. This project is just large enough to demonstrate some of the key concepts in Reason.
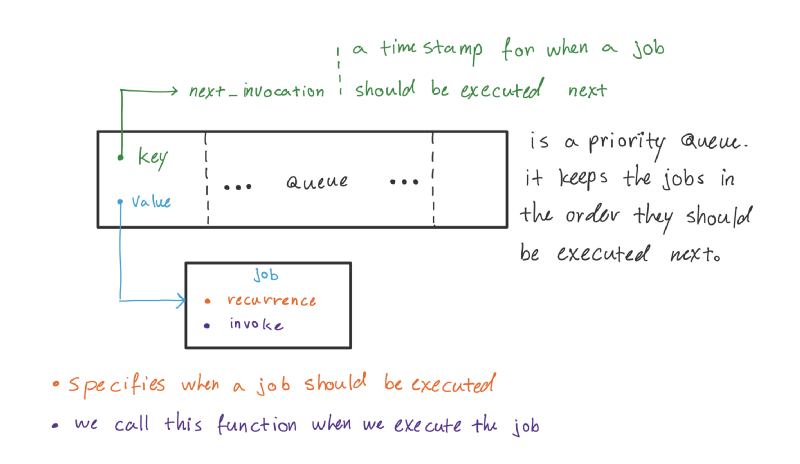 The Big Picture :P
The Big Picture :P
To achieve this, we will define two modules — a Heap and a Scheduler.
Heap is an implementation of a priority queue. It keeps the jobs in the order they should be executed next. The key of a heap element is the next invocation time of the job.
Scheduler is composed of a heap and is responsible for updating the timer and executing the jobs by the specified recurrence rules.
- When a job executes, the scheduler will remove the job from the queue, calculates its next invocation time, and inserts the job back to the queue with its updated invocation time.
- When a new job is added, the scheduler checks the next invocation time of the root (head / the job that will be executed next). If the new job should be executed before the head, the scheduler updates the timer.
Heap module
The API of a priority queue defines:
- Inserting a new element to the queue with a key representing its priority
- Extracting the element with the highest priority
- Size of the queue
Heap performs insert and extract operations in order O(log(n)) where n is the size of the queue.
Note: We will talk about algorithm complexity in the last section of the article. If you’re not comfortable with algorithm complexity, you can ignore the last section.
If you’re not comfortable with the Heap data structure or need a refresher, I recommend watching the following lecture from MIT OCW 6006 course. In the remaining of this section, we will implement the pseudocode outlined in the lecture notes of 6006.
Defining the types used by the heap module
 heapElement
heapElement
heapElement defines a record type. Similar to a JavaScript object, you can access record fields by name. { key: 1, value: "1" } creates a value of type heapElement(int, string).
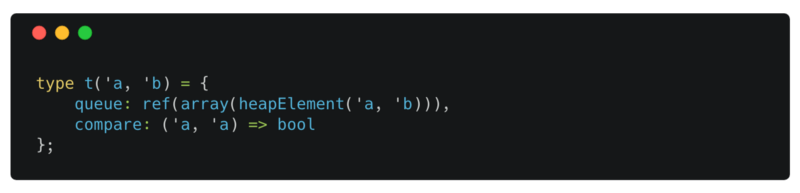 Heap.t
Heap.t
t('a, 'b) is another record type and represents the Heap. This is the return type of our create function and the last parameter passed to all the other functions in the public API of our heap module.
To maintain the max heap property, Heap only needs to compare the keys of the elements in the array. Hence, we can hide the type of key from the Heap by providing a comparison function compare that returns true when its first argument has a higher priority than the second one.
This is the first time we see ref. ref is Reason’s way for supporting mutations. You can have a ref to a value and update that ref to point to a new value by using the := operator.
Arrays in Reason are mutable — You can update a value at a specific index. However, they have a fixed length. To support addition and extraction our heap needs to hold onto a ref to an array of heap elements. If we don’t use a reference here, we will end up having to return a new heap after every addition and extraction. And the modules that depend on the heap need to keep track of the new heap.
 EmptyQueue exception
EmptyQueue exception
[exception](https://reasonml.github.io/docs/en/exception.html) can be extended with new constructors. We will raise EmptyQueue exception later in the extract and head functions in the heap module.
Exceptions are all of the same type,
exn. Theexntype is something of a special case in the OCaml type system. It is similar to the variant types we encountered in Chapter 6, Variants, except that it is open, meaning that it's not fully defined in any one place. — RealWorldOcaml
Signature
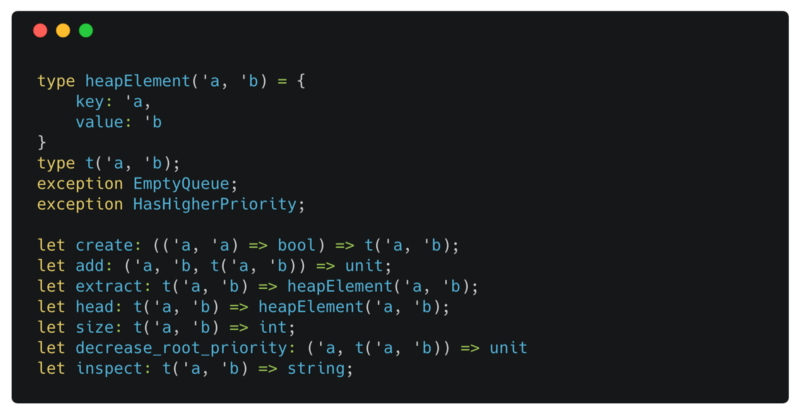 Heap signature
Heap signature
By default, all the bindings (variable assignments) in a module are accessible everywhere even outside the module where they are defined. signature is the mechanism by which you can hide the implementation specific logic and define an API for a module. You can define a signature in a file with the same name as the module ending with .rei suffix. For example you can define the signature for the Heap.re in the Heap.rei file.
Here, we are exposing the definition of heapElement so the users of the Heap module can use the value returned by head and extract. But we are not providing the definition for t our heap type. This makes t an abstract type which ensures that only functions within the Heap module can consume a heap and transform it.
 Heap initializer
Heap initializer
Every function except create takes as argument a heap. create takes a comparison function and creates an empty Heap.t that can be consumed by the other functions in the Heap module.
Helper functions
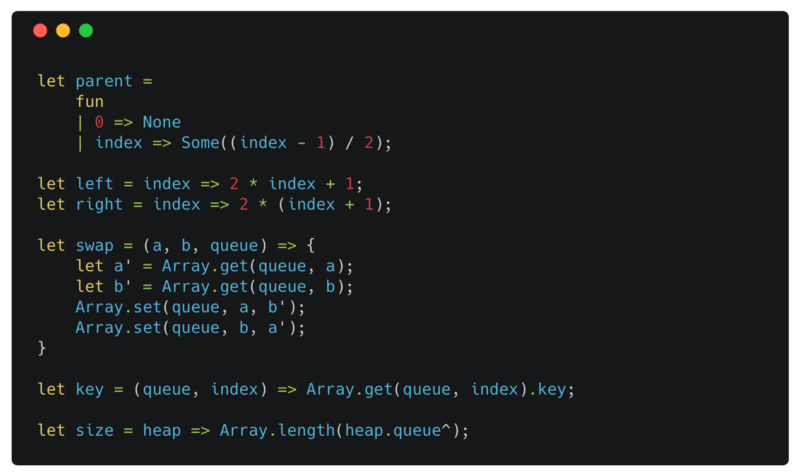 Helper functions
Helper functions
parent is a function that takes a single argument — index. It returns None when the index is 0. index 0 indicates the root of the tree, and the root of a tree doesn’t have a parent.
left and right return the index of the left and the right child of a node.
swap takes two indexes a and b and an array queue. It then swaps the values in the index a and b of the queue.
key simply returns the key field of a heapElement at the specified index in the queue.
size returns the length of the queue
Add
add is one of the primary functions we exposed in the heap signature. It takes a value and a key representing the priority of the value to insert into the queue. We will use this function later in the Scheduler module to add new jobs to our execution queue.
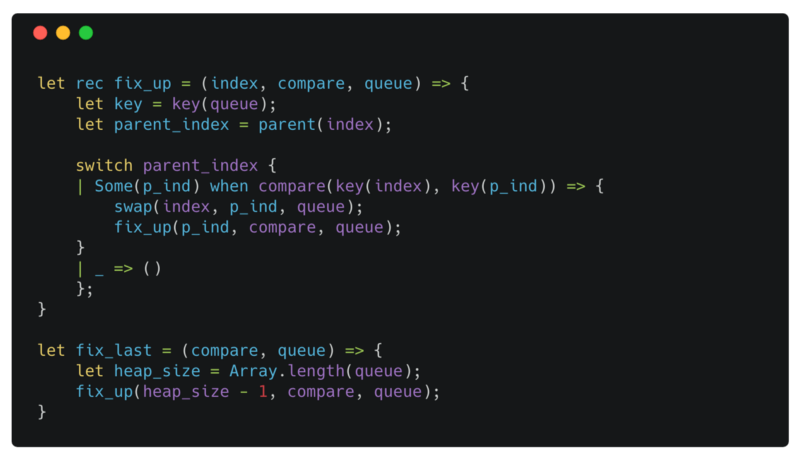 fix up
fix up
let rec lets us define recursive functions. With rec you can refer to the function name inside the function body.
We defined key as a function that takes a queue and index as arguments. With the declaration let key = key(queue) we are shadowing key by partially applying the helper function key we defined previously.
When you provide a subset of the arguments to a function, it returns a new function that takes the remaining arguments as input — this is known as currying.
The arguments you provided are available to the returned function. Since queue is fixed in fix_up, we partially apply it to the key function to make our code more DRY.
You can use <cas[e>](https://reasonml.github.io/docs/en/pattern-matching.html#when-clauses); when <condition> to specify additional conditions in pattern matching. The value bindings in the case are available to the expression following when (in our example p_ind is available in compare(key(index), key(p_ind)). Only when the condition is satisfied we execute the associated statement after the =>.
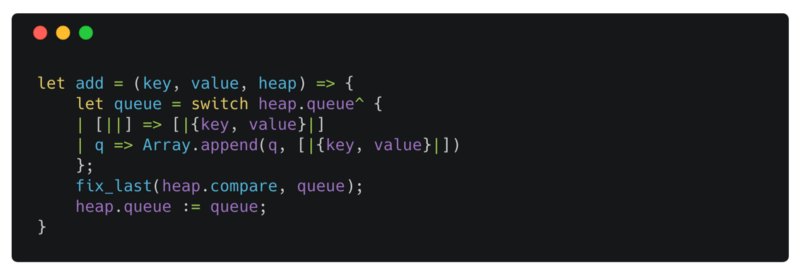 add
add
add concatenates a new element to the end of the queue. If the new element has higher priority than its parent, it is violating the max heap property. fix_up is a recursive function that restores the max heap property by moving the new element up in the tree (pairwise swapping with its parent) until it reaches the root of the tree or its priority is lower than its parent.
fix_last is just wrapper around fix_up and calls it with the index of the last element in the queue.
heap.queue^ is how we access the value ref references.
[||] is the array literal syntax for an empty array.
Extract
extract removes the element with the highest priority (in our case, the element with the smallest key) from the queue and returns it. extract removes the head of the queue by first swapping it with the last element in the array. This introduces a single violation of the max heap property at the root/head of the queue.
As described in the lecture, heapify — also known as sift-down— fixes a single violation. Assuming the left and right subtrees of node n satisfy the max heap property, calling heapify on n fixes the violation.
Each time heapify is called, it finds the max_priority_index index of the highest priority element between the heapElements at the index, left(index), and the right(index). If the max_priority_index is not equal to the index, we know there is still a violation of the max heap property. We swap the elements at the index and max_priority_index to fix the violation at index. We recursively call heapify with the max_priority_index to fix the possible violation we might create by swapping the two elements.
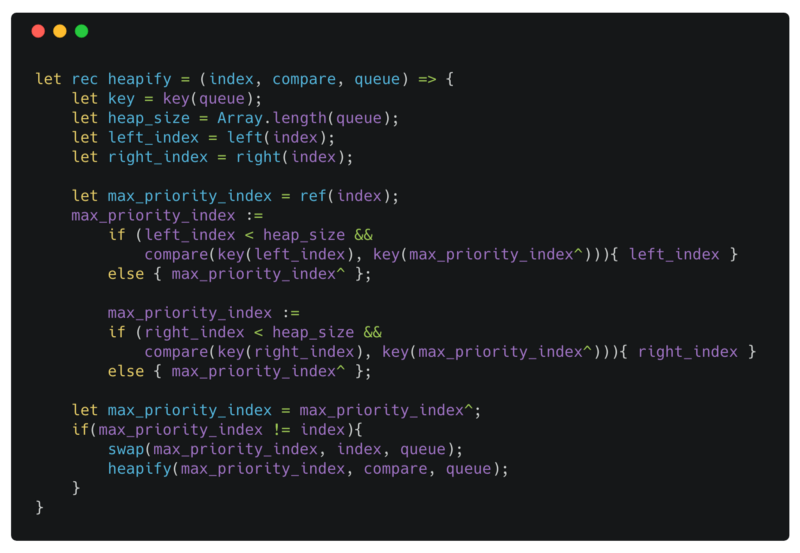 heapify
heapify
index is an int representing the root of a subtree that violates the max heap property, but its subtrees satisfy the property. compare is the comparison function defined with the heap. queue is an array that holds the heap elements.
[if](https://reasonml.github.io/docs/en/if-else.html) statements in Reason like the other expressions evaluate to a value. Here the if statements evaluate to an int that represents which index was smaller in the comparison.
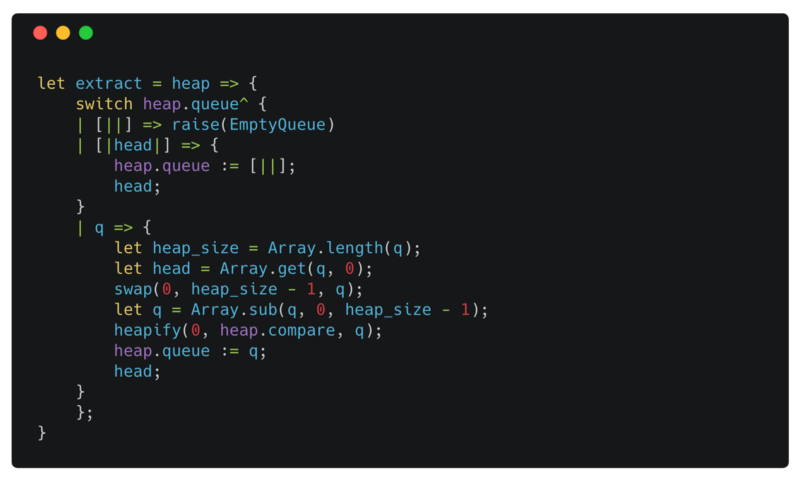 extract
extract
extract pattern matches against queue (the array not the reference).
[|head|] only matches an array with a single element.
When the queue is empty [||] we raise the EmptyQueue exception we defined previously. But why? Why don’t we return None instead? Well this is a matter of preference. I prefer to raise an exception, because when I use this function, I will get a heapElement and not a option(heapElement). This saves me pattern matching against the returned value of the extract. The caveat is that you need to be careful when you use this function, making sure the queue is never empty.
When we have more than one element, we swap the first and the last element of the queue, remove the last element and call heapify on the first element (the root of the tree).
Testing
We use bs-jest — BuckleScript bindings for Jest — to write tests. Jest is a testing framework created by Facebook that comes with Built-in mocking library and code coverage reports.
Follow the instructions in bs-jest to set up Jest.
Make sure to add @glennsl/bs-jest to bs-dev-dependencies in your bsconfig.json. Otherwise BuckleScript won’t find the Jest module and your build will fail.
If you’re writing your test cases in a directory other than src you have to specify it in the sources in the bsconfig.json for the BuckleScript compiler to pick them up.
Testing synchronous functions
With the Heap module in place and Jest installed, we are ready to write our first test case.
To test our Heap module, we will do a heap sort.
- create a heap
- insert elements into the heap
- use the
extractoperation to remove the elements in the ascending order
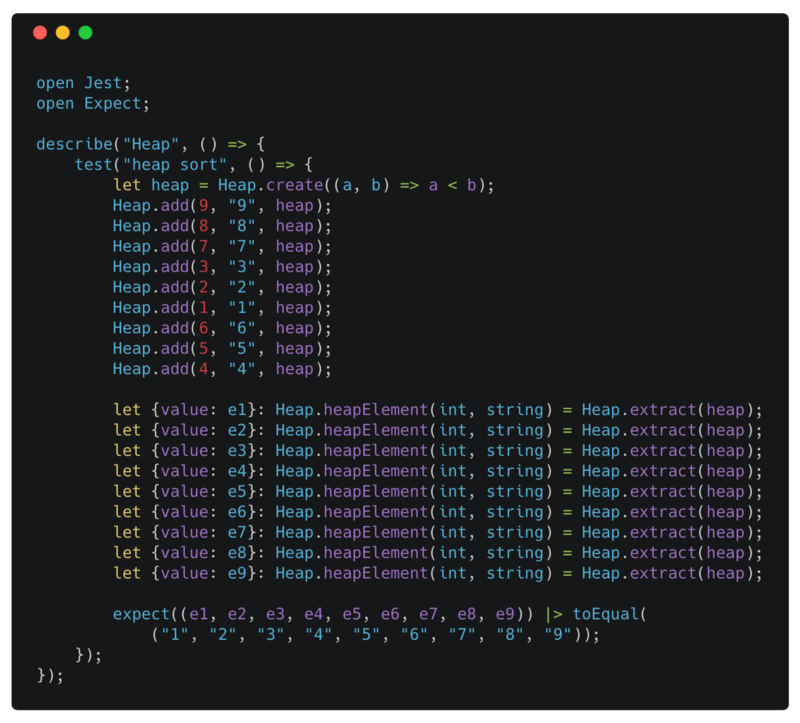 Heap sort test
Heap sort test
open Jest opens the module so we can refer to the bindings available in the Jest module without prepending them with Jest.. For example, instead of writing Jest.expect we can just write expect.
We use let {value: e1} = to destructure the value returned by extract and create an alias e1 for value — e1 is now bound to the value field of the value returned by extract.
With the|> pipe operator we can create a composite function and apply the resulting function immediately on an input. Here we simply pass the result of calling expect with (e1, ..., e9) to the toEqual function.
Scheduler module
Scheduler uses the Heap module to maintain a list of recurrent jobs sorted by their next invocation time.
Let’s define the types used in the Scheduler module
 recurrence
recurrence
recurrence is a Variant type. Any value of the recurrence type can either be a Second, Minute, or an Hour. Second, Minute and Hour are the constructors for the recurrence. You can invoke a constructor like a normal function and get back a value of the Variant type. In our case, if you call Second with an int you get back a value of type recurrence. You can pattern match this value with Second(number_of_seconds) to access the argument that was passed to the Second constructor.
 job
job
job is a record type. period is of type recurrence and indicates the delay between each execution of a job. invoke is a function that takes unit (no argument) and returns unit (no result). invoke is the function that gets executed when the job runs.
 Scheduler.t
Scheduler.t
t is a record type representing the scheduler. A scheduler holds onto a queue of jobs sorted by their next invocation time. timer_id references the timerId for the first job in the queue — the job that will be invoked first.
Interop
You can invoke JavaScript functions from within Reason. There are different ways of doing this:
- you can use BuckleScript bindings if available, such as
Js.log, and[Js.Global.setTimeout](https://bucklescript.github.io/bucklescript/api/Js.Global.html) - declare an
externalsuch as[@bs.val] external setTimeout - execute raw JavaScript code with
[%raw ...]
Bindings for most JavaScript functions is provided by the BuckleScript. For example, [Js.Date.getTime](https://bucklescript.github.io/bucklescript/api/Js.Date.html#VALgetTime) takes a Js.Date.t — a date value — and returns the number of milliseconds since epoch. Js.Date.getTime is the binding for the getTime method of the the JavaScript Date object. Js.Date.getTime returns a float value.
Using bucklescript bindings is exactly the same as using user-defined modules. You can read more about the available bindings here. For the rest of this section we will focus on external and [%raw ...].
external
With [external](https://bucklescript.github.io/docs/en/intro-to-external.html) you can bind a variable to a JavaScript function. Here for example we are binding setTimeout variable to JavaScript’s setTimeout global function.
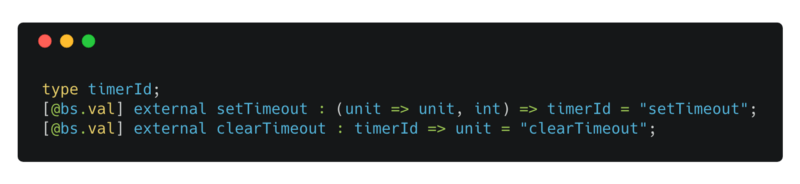 _setTimeout and clearTimeout definition in [BuckleScript docs](https://bucklescript.github.io/docs/en/bind-to-global-values.html#abstract-type" rel="noopener" target="blank" title=")
_setTimeout and clearTimeout definition in [BuckleScript docs](https://bucklescript.github.io/docs/en/bind-to-global-values.html#abstract-type" rel="noopener" target="blank" title=")
setTimeout returns a float, an identifier that we can pass to clearTimeout to cancel the timer. The only function that uses the value returned by the setTimeout is clearTimeout. So we can define the value returned by setTimeout to have an abstract type. This ensures that only a value returned by setTimeout can be passed to clearTimeout.
[%raw …]
new Date.getTime() in JavaScript returns an integer Number. Numbers in JavaScript are 64bit long. [int](https://reasonml.github.io/docs/en/integer-and-float.html#integers) in Reason are only 32bit long. This is a problem!
In Reason, we can work with the returned value of new Date.getTime() by expecting it to be Float. This is actually the expected return type of [Js.Date.getTime](https://bucklescript.github.io/bucklescript/api/Js.Date.html#VALgetTime) provided by BuckleScript.
Instead, let’s use [%raw ...] and create an abstract type long similar to what we did for setTimeout. In doing this, we are hiding the implementation of long. Our Reason code can pass values of type long around, but it can’t really operate on them. For this we are defining a set of helper bindings that take values of type long and delegate the computation to raw JavaScript expressions.
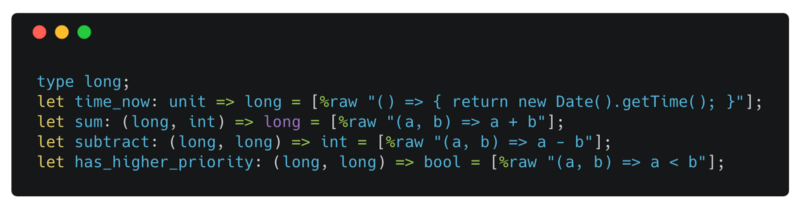 working with JavaScript values
working with JavaScript values
We can define a JavaScript expression with [[%raw ...]](https://bucklescript.github.io/docs/en/embed-raw-javascript.html). Here we are defining an abstract type long and a set of functions that consume and return values of type long. The type of all the expressions is specified in the let bindings.
time_now returns the number of milliseconds since epoch.
We use sum to calculate the next invocation time of a job, by passing in the result of time_now and an int representing how many milliseconds from now the job should be executed.
We can compute how long from now a job will be invoked by subtracting the invocation time of a job from time_now. The result of subtract is passed to the setTimeout.
has_higher_priority compares two invocation times. This is the comparison function we use to initialize our Heap.
Invocation
At any point in time, we only have a single timer that expires when the first job in the queue should run. When the timer expires, we need to do some cleanup. When the timer expires, we should
- extract the first job from the queue
- calculate its next invocation time (a new key for the job)
- insert the job back into the queue with its updated key
- look at the head of the queue to find the job that should be executed next and
- create a new timer for this job
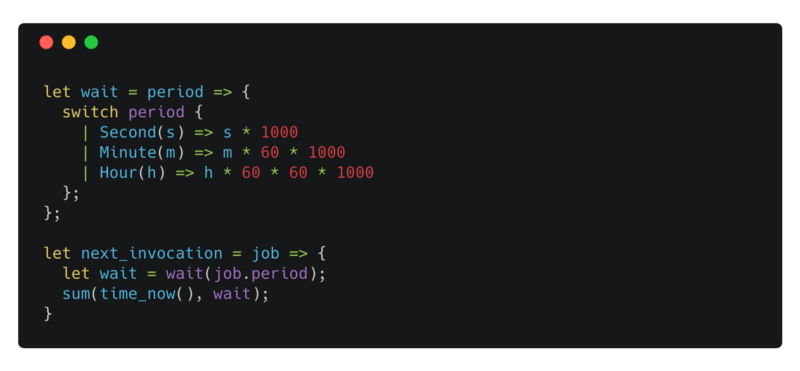 helpers
helpers
wait takes a period — a value of type recurrence — and returns an int representing how many milli-seconds a job has to wait before getting executed again. We pass the value returned by wait to the setTimeout.
next_invocation calculates the next invocation time of a job. time_now returns a long value. sum takes in a long and an int value and returns a long value. sum adds the two number by calling the JavaScript + operator on its arguments.
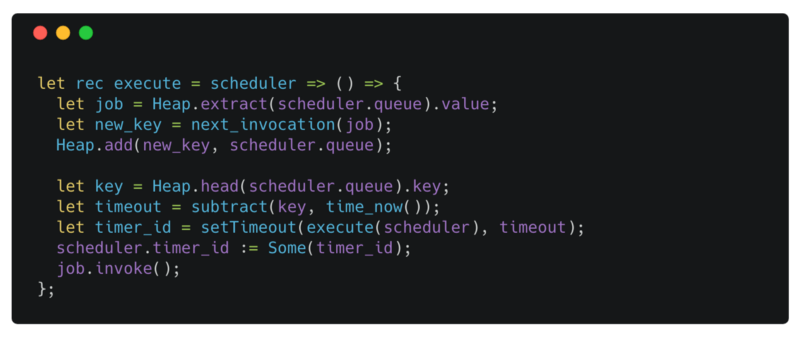 Invoking a job
Invoking a job
execute is a recursive function that is responsible for executing the job and doing the cleanup. It captures the scheduler in a closure and returns a function that can be invoked when the timer expires.
In the first three lines, we remove the job with the highest priority (lowest key or closest invocation time) and insert it back into the queue with its next invocation time.
We then go on to create a new timer for the job at the head of the queue (the next job that should be executed after this invocation). We update the timer_id reference to point to the new timerId.
Finally, we call the invoke field of the job to perform the specified task.
Add a new job
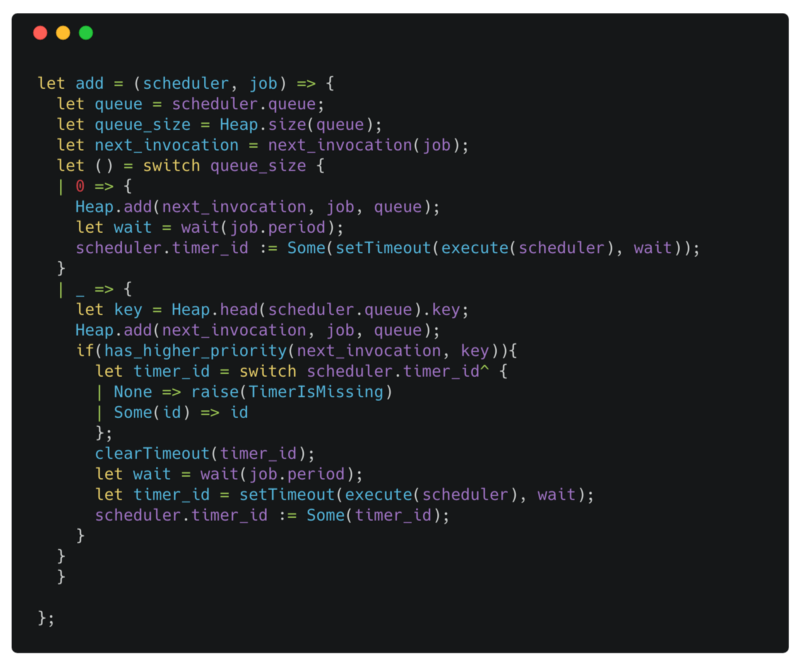 adding a new job
adding a new job
When the queue is empty, adding a new job is simple. We create a timer that expires at the next invocation time of the job.
The more interesting case is when the queue is not empty! We can have two situations here. Either the head of the queue has a key greater than the next invocation time of the job or not.
The first case is when the head of the queue has a key less than or equal to the next invocation time of the job. This is the case when the new job needs to be executed before the current timer. In this case, we need to cancel the timer by calling clearTimeout with the timer_id and create a new timer that will expire at the next invocation time of the new job.
In the other case, because the new job needs to be executed after the current timer expires, we can just insert the new job in the queue.
Testing asynchronous functions
All the functions in the heap module are synchronous. For example, when you call add, you are blocked until a new heapElement has been added to the queue. When add returns, you know that the heap has been extended with the new element.
The functions in the scheduler, on the other hand, have asynchronous side effects. When you add a new job to the scheduler, the scheduler adds the job to its queue and returns. Later, according to the recurrence rule the job gets invoked. Your code doesn’t wait for the job to get invoked, and continues executing.
Now, lets write a test case to ensure that when a job is added to the scheduler, it gets invoked according to its recurrence rule.
To do this we will
adda job to the scheduler to be executed every second. This job increments aref(int)counter.- create a
Promisethat gets resolved after 4s - return a
Jest.assertionpromise that expects the counter to have been incremented 4 times.
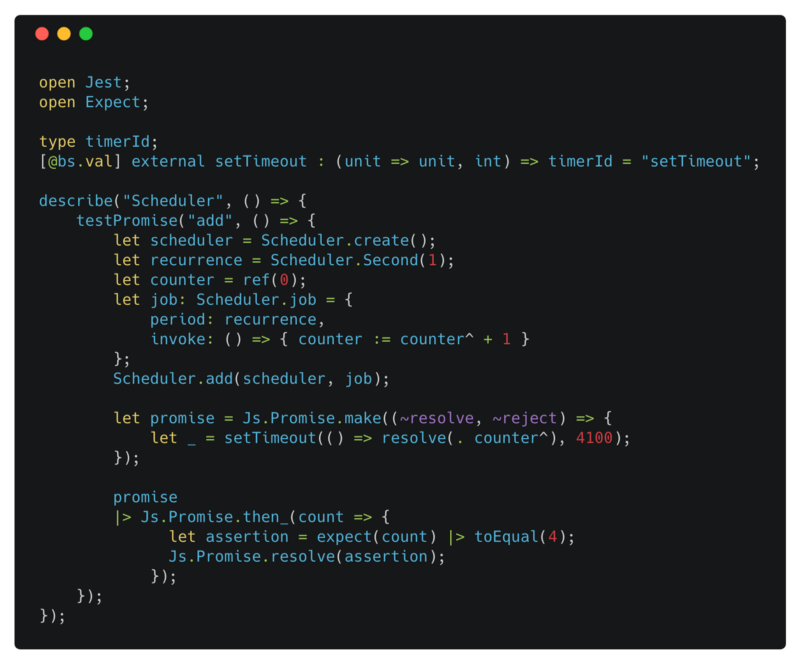 Test Scheduler add
Test Scheduler add
We can use testPromise to test promises. testPromise expects a Js.Promise.t(Jest.assertion). Look at the last line of the test case.
Scheduler.Second(1) indicates we want our job to execute every second.
counter is a ref and everytime invoke is called, it gets incremented.
promise is a [Js.Promise.t](https://reasonml.github.io/docs/en/promise.html) that will get resolved after 4s. Notice that we are waiting for 4.1s to make sure the last call to the invoke has finished executing. Otherwise, we might resolve the promise when we have only incremented the counter three times.
You can use |> to chain promises. In our example, promise will resolve with the value of the counter after 4s. This value is provided as the count to the function passed to the Js.Promise.then_.
Optimize
We implemented our Heap and Scheduler modules similar to what we would have done in JavaScript. In doing so, we have reduced the performance of the functions operating on the heap such as add and extract to O(n).
We know Array in Reason has a fixed length. Everytime we add a new job or delete one, the size of our Array will change and therefore a new copy will be created. We can fix this by creating a dynamic array module that implements table doubling.
I have created a version of Heap and Dynamic Array if you’re interested in the implementation, however, I think this would be outside the scope of this article. So for now we focus on optimizing the Scheduler by calling operations that cost O(n) less frequently.
There are two places in the Scheduler where we call Heap.add and Heap.extract — when adding a new job and when executing a job.
We can’t help Scheduler.add but we can fix the performance of Scheduler.execute. The execute function doesn’t need to call extract or add since the size of our queue before and after execute should be the same.
Let’s introduce a new function to our Heap Signature. decrease_root_priority reduces the priority of the root of the Heap. We can use this new function to update the root key to its next invocation time without first extracting the head of the queue and adding it back with its updated invocation time.
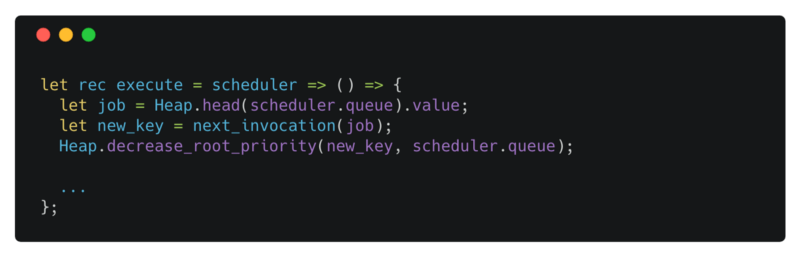 execute optimized
execute optimized
decrease_root_priority takes the new priority for the root, checks to make sure the new priority is less than the current priority of the root, and delegates the actual work to a helper function update_priority.
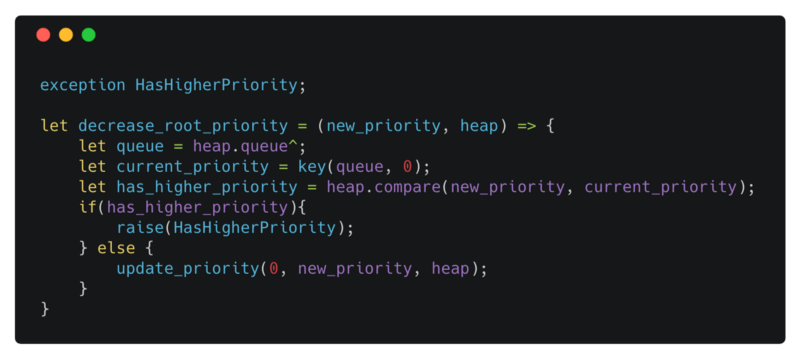 decrease root priority
decrease root priority
update_priority can decrease or increase the priority of any element in a Heap in O(log(n)). It checks whether the new priority violates the max heap property with respect to the children of a node or its parent. When we increase the priority of a node, we might be violating the max heap property of the node with respect to its parent and so we fix_up. When we decrease the priority of a node, we might be violating the max heap property with respect to its children and so we call heapify to fix the possible violation.
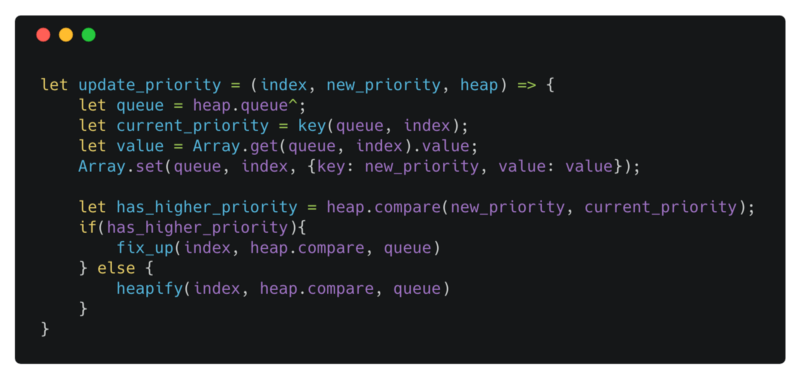 decrease priority
decrease priority
Next steps
This article is by far not a complete overview of the features of Reason. We have seen many of the language constructs, but haven’t explored them in detail. There are also features that have been left out, such as functors and objects. I strongly recommend you to read the documentation or Exploring ReasonML and functional programming to know what’s available to you before jumping to coding.
The complete source code for what we covered today is available in the master branch of the https://github.com/Artris/reason-scheduler
If you want to practice, I encourage you to add remove functionality to the scheduler. In specific, extend the signature of the Scheduler with
type jobIdandlet remove = (t, jobId) => unit
I also encourage you to add test cases for the functions exposed in the signature of the Heap and Scheduler modules.
The test cases for all the functions in the Heap and Scheduler module as well as an implementation for the remove functionality is available in the solutions branch.
Attribution
I would like to thank the Reason/BuckleScript community for providing detailed documentation. And Dr. Axel Rauschmayer for Exploring ReasonML book and many interesting articles on Reason.
Code snippets were generated using carbon.now.sh.
I’d also like to thank Grace, Sami, Freeman, and Preetpal who helped review this article.