
By Nikita Kozlov
Whenever we need to display a lot of content that is stored on the backend, we split it in chunks and then load them subsequently one piece at a time. This is a common approach, and there are multiple reasons why it is so great:
- It improves user experience. Loading a small single page takes less time, so the user can start consuming content faster.
- It reduces load on the network. A single page is small and light in terms of bandwidth. Plus, we can optimize battery and network consumption for mobile devices by adjusting the size of a single page.
- It reduces load on the back end. Processing smaller pieces is faster then bigger ones. Users usually don’t need all the content at once, so average load-per-user is lower.
Everybody wins. In most of the cases. But not all of them. As it often happens with generic solutions, the more domain-specific it gets, the better the solution that can be found. In this article, I want to share an interesting solution for one such case.
Defining the task
Let’s imagine a collection that changes frequently over time. For example, we could look at a list of articles a user clapped for on Medium, or a wish list in a shopping application, or a history of any other users’ actions in general. Users can “add” as many items to that collection as they want.
Our task is to display this collection in a convenient way, while doing our best to avoid abusing the network and therefore abusing battery and bandwidth.
Problems with pagination
One of the ways to minimize network usage is to cache responses. Most mobile and web applications heavily rely on the HTTP cache. It saves responses for a period of time specified in the response’s header. Every time an application makes a request, the HTTP client tries to get a corresponding response from the cache. Only if it is not available does it make an actual call to the backend.
Sometimes this kind of caching does not work well for paginated content. If the collection is changed frequently and the content needs to be up-to-date, then it simply doesn’t make sense to cache the response at all. As an example, let’s imagine the following scenario:
- The user opens the list of articles they clapped for here, on Medium. The first page is fetched from the backend.
- After that, the user searched for something new, found another interesting article, and decided to recommend it.
- Now they want to check the list of articles they recommended again.
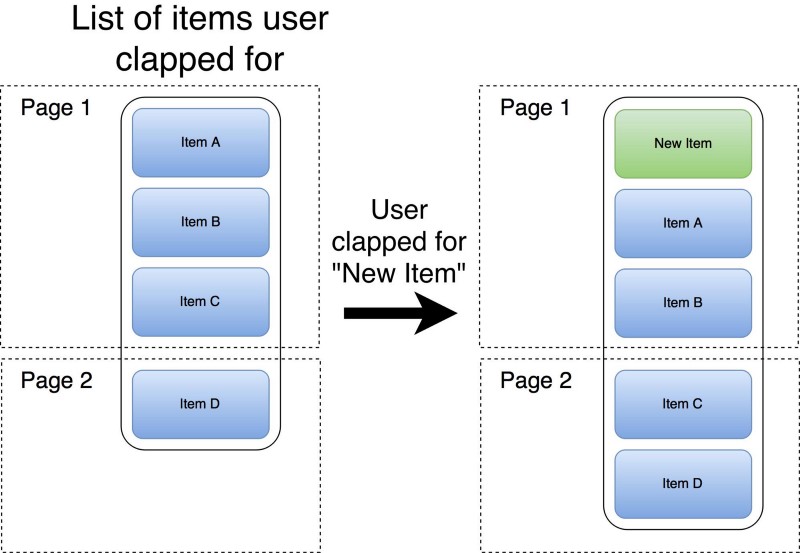
The application needs to perform the very same request for the first page, but the result is different. The response can’t be cached.
If your domain-specific task allows you to rearrange items in this collection, then your problem is even worse. Because of the very same reason: the response is changing constantly.
Another approach
Let’s take a closer look at the first page of data fetched from the backend. The response itself is a list of items in a particular order. Each item is unlikely to change. What changes is the order of elements and what items are on this list.
This means that if we can fetch separately the order of the item IDs and the item details, then the second call can potentially be cached. As a matter of fact, even caching the second call is not straightforward — but we’ll get to it. For now, let’s make a separate request for each item:
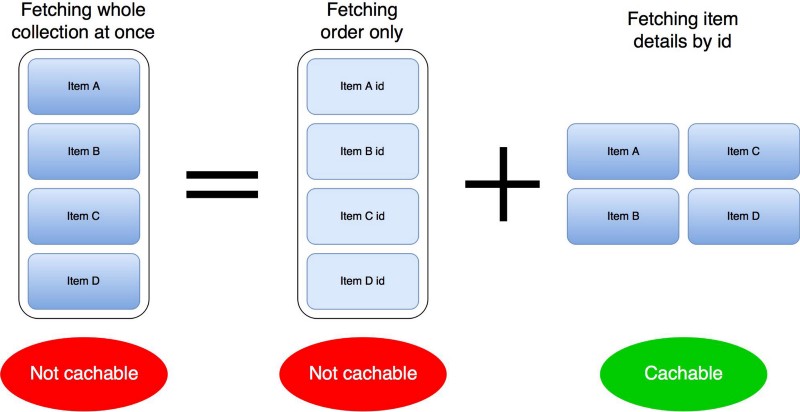
As you can see on the diagram above, because items are unlikely to change, we can cache item detail calls. Unfortunately, such a split will multiply the amount of network calls by an order of magnitude. But there is something we can do about it.
What do we actually want?
If we just request a bunch of items, we will encounter the same problem as the generic pagination approach. The HTTP cache won’t act as we want, so let’s write our own using similar but more deliberate logic.
This cache is not going to store batches, but single items for a particular amount of time. We will take the response, access its HTTP headers, and retrieve information about caching time. Then, we will put each item individually into the cache. Next time we need to display items, we can easily access cached ones and request the rest. In code it looks easier than it sounds:
Let’s go quickly through the code. Method getOrderedItemsIds() returns the order of elements and is paginated. The most important part is method getItemsByIds(). This is a place where we first check what items are in the cache, and then request the rest from the backend. Please note that for the sake of simplicity, the code above is synchronous and probably won’t compile.
After implementing this approach, the addition of a new item to the head of the list will cause a request for the order one of the item IDs and details for the new item. The rest comes from the cache.
A similar pair of calls will happen for each consecutive page. The main idea is that we can retrieve most item details from the cache. But unfortunately we have to request the order of item IDs for every page.
Do it better
The item IDs is usually a small object like a String or Universally Unique Identifier (UUID). Therefore, we can send bigger pages. Increasing the amount of item IDs returned by an order call decreases the number of calls, without abusing network bandwidth.
For example, instead of requesting 20–40 item IDs we can request 100-200. Later, the UI layer can moderate the number of item details that need to be displayed and request them accordingly. Then a sequence of calls will look something like this:
- Request first 100 item IDs and keep them in memory.
- Request details for first 20 items (cache them of course) and display them to the user.
- After the user scrolls through the first 20 items, request the second batch of 20 item details.
- Repeat the previous step three more times and do similar steps for the next page of item IDs.
Now adding a new item to the top still results in two requests (one for IDs and the other one for details of this new item). But we won’t have to request the next page for a while, because the pages are bigger. We also won’t need to request item details because they are cached!
Small disclaimer: the way UI moderates the requesting of item details can be more interesting. For example, it can skip requests for some items if the user scrolls too fast, because they’re not interested in them. But this deserves a whole other article.
Conclusion
General solutions are usually not optimized for particular cases. Knowing specifics can help us write faster, more optimized applications. For this case, the knowledge was crucial that content changes frequently and that it is a collection of items with IDs. Let’s review all the improvements the new approach brought:
- Requesting the order of items separately enables us to cache details, even though we had to write a modified HTTP cache.
- Caching item details results in reduced usage of bandwidth.
- Increased size of pages for the order request reduces the number of calls.
One last thing: optimizations are awesome, and I found it exciting to write efficient code — but don’t forget to profile it first. Premature optimization could cause problems and we all should avoid it.
Nikita Kozlov (@Nikita_E_Kozlov) | Twitter
_The latest Tweets from Nikita Kozlov (@Nikita_E_Kozlov): “https://t.co/wmGSJ7snW1"_twitter.com
Thank you for you time reading this article. If you like it, don’t forget to click the ? below.