
By Sumeet Ninawe
Web applications are built to provide various online services to end-users. Developing and hosting these services involves hard work and talent. And it all begins with an idea.
But imagine, after putting in all that hard work, users cringe about the performance of the system – “It's too slow...”, “I wish I could get the response in this lifetime...”, “The product is good, but not really worth waiting for...” and they go on.
On the other hand, if you decide to provide your users with the best performance but you've got a poorly architected system, then your infrastructure costs can soar.
In this article, will see how making the right trade-offs matter.
Think of a music concert. Everyone's there, waiting to enjoy their favorite acts live. There are so many audio parameters associated with every line of input and output that runs across the stage, and those need to be set at an optimum level.
Blasting everything to its full level would make people leave the concert. Of course, this is not the artist’s fault – but the sound engineer who's job it is to make the artist sound good.
After all, this is a production system – similar to IT production environments. In IT, managing the system's performance essentially means managing the tradeoffs well. Of course, there are clear choices, but at times, making those straightforward choices is not so obvious.
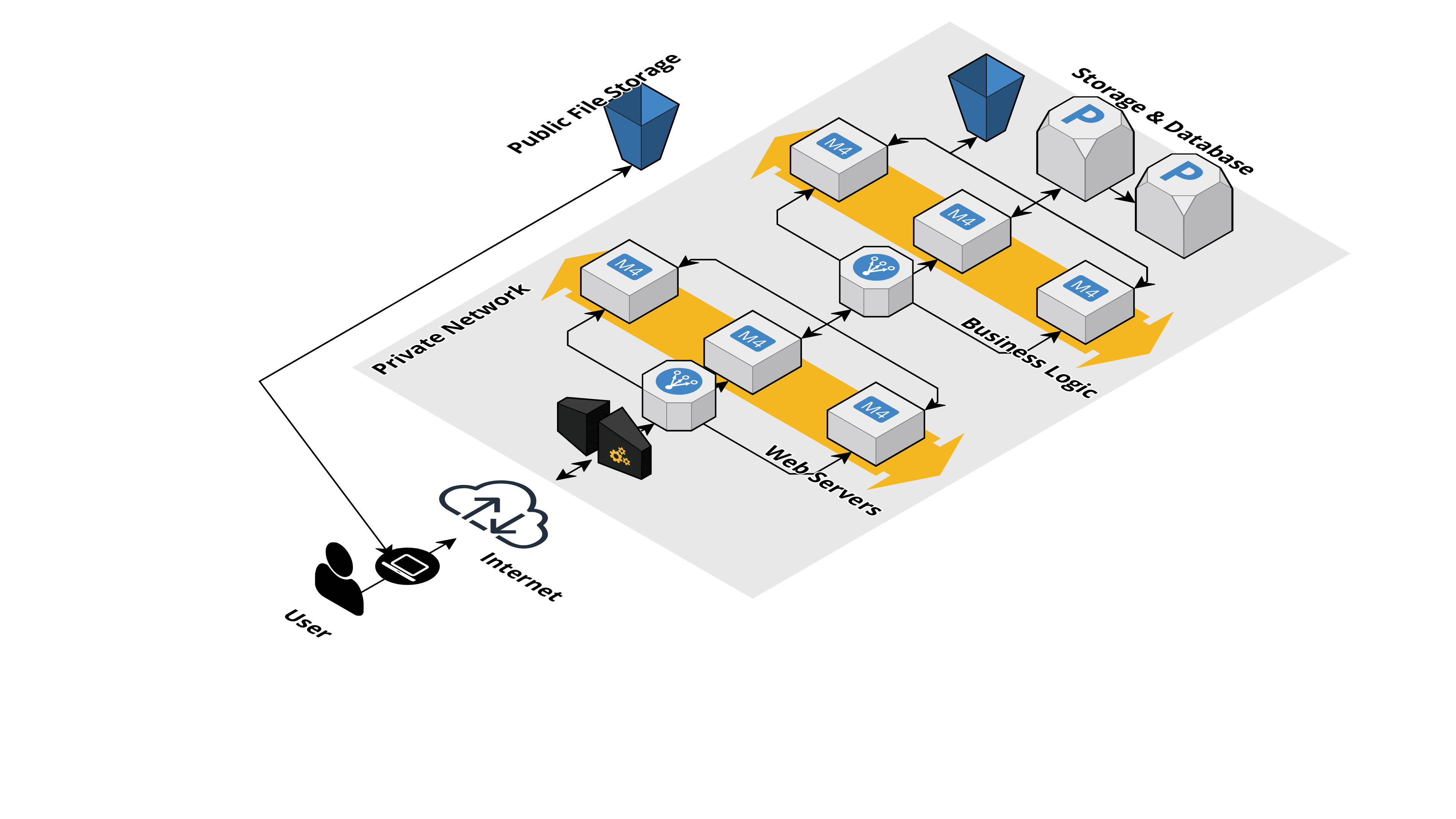 Basic Web Application Infra Design
Basic Web Application Infra Design
What is Cloud-Native?
Deploying business applications and services on managed data centers, also known as the cloud, is a long-running trend in the IT industry. This is mainly because the cloud offers numerous benefits and expertise while offering data-centers as a service.
Security, regulatory, and operational challenges still exist, so organizations are still lagging as far as moving 100% of their workloads to the cloud. On the other hand, startups go pro-cloud deployment as it is much easier to get your infrastructure managed by the cloud platforms from day one.
But what do we mean by cloud-native? You may think that merely shifting your workloads to the cloud will help you reap maximum benefits. That is partly true, since there are stages of cloud adoption. Cloud providers offer many rich infrastructure services, and when leveraged properly, they can drastically reduce your IT infrastructure costs.
The term "cloud-native" indicates the degree of cloud adoption in an organization. You might have come across cloud migration projects executed by organizations where they shift their workloads from on-prem hardware servers to VMs in the cloud. This is useful, as they benefit from getting rid of the effort required to maintain data centers themselves – but the situation could still be better.
Mere lifting and shifting of workloads is not very intelligent and is not cloud-native. Cloud platforms offer many more services like container registries, cluster management solutions, DevOps services, Serverless/Function-as-a-Service, and so on. All together, these give better results – in terms of everything, like cost, performance, maintenance, flexibility, reliability, security, and so on.
The notion of going cloud-native means adopting as many services provided by cloud providers as you're able, and aligning or refactoring your workloads to be deployed on the cloud in the most beneficial manner.
With that in mind, let's see how cloud-native adoption can help you improve the performance of your systems.
How to Improve Your System's Performance
When it comes to architecting any IT system, performance is one of the key aspects. We can classify the performance topics discussed below into three broad categories – compute, storage and memory, and network. Such categorization helps us look at the system from various lenses, and isolate the issues.
1. Workload Partitioning
Category: Compute
You might be aware that monolithic architectures represent the single point of failure. The probability of the entire system going down is high, even due to trivial issues.
The emergence of microservice architecture has helped solve this problem, but it also depends on how those microservices are designed.
While refactoring a monolith into microservices, you should follow the single responsibility principle. Build one microservice for one purpose only, and deploy multiple instances of critical microservices in auto-scaling mode to avoid the drop in performance.
This kind of workload partitioning helps tackle issues in an isolated way, reducing the risk of failures.
One of the first services offered by cloud providers was perhaps the ability to spin up virtual machines as needed. We can choose the flavor of the OS, size, networking, and various other aspects. Leverage this flexibility to deploy partitioned workloads.
Going a step ahead, you can isolate the runtime requirements for the services using containerization. This could be OS resources, CPU, network bandwidth, memory, and so on, where the quota can be predefined. This allows shared but dedicated resource allocation, thus breaking the one application, one server rule.
When workloads are containerized, it provides a firm base system that ensures its performance on any system that supports running container workloads – independent of hardware or OS.
Cloud providers also provide container orchestration services (for example Kubernetes), making it easier to deploy, debug and release newer versions of applications without downtime. Using these services and a wise deployment strategy can help roll out new features without any lag or glitch in the user experience.
I want to highlight that you should break your applications into microservices and host each service on isolated infrastructure. This avoids a lot of inter-process interference and resource contentions, thus optimizing the resource consumption for performance.
2. Compute Optimization
Category: Compute
Every application has different needs. Standard VMs offer everything that is required in a general-purpose server – CPU, Memory, and Networking capabilities.
However, not every application running on these VMs follows a standard as far as resource consumption is concerned. Applications or microservice components are purpose-driven, in a way that they have different computing needs.
A frontend server may rely more on networking capabilities as compared to its compute or memory requirements. A microservice dealing with large data transformation activities may need a better memory management solution for accessing the memory and performing transactions.
Major cloud providers offer features to optimize the virtual resources – especially VMs and databases – to align them with the application’s needs. In general, these optimizations can be categorized into three groups:
- Compute-optimized
- Memory-optimized
- Storage-optimized
Depending on the criticality of the applications, there are options that help you optimize costs. You just need to choose the appropriate pricing plan and then trade off the availability of critically low applications with cost benefits.
Optimized virtual servers are selected depending on their purposes:
- Batch processing, heavy data transform workloads, and ML algorithms usually need high-performance processors given their compute-intensive tasks. Choose to provision memory optimized instances for this purpose. Compute optimized instances are provisioned with enhanced block and file storage, along with widened network bandwidth. This helps churn out the best performance to process data oriented workloads.
- If your app needs to deliver high network performance to transfer high volumes of data and serve a high volume of requests, then it is important to choose the right networking hardware associated with a provisioned VM. In this case, you can choose to optimize the network performance by opting for a high performance network interface card.
- SSD-based volumes are used to assist CPU performance if the processing needs multiple transactions on the memory. A storage optimized VM helps with faster IO operations, and it's tuned for high throughput. Compared to using a general purpose VM, storage optimized VMs deliver greater performance.
It is important to analyze the system requirements for a given workload. A balanced configuration offered by general purpose VMs may just result in higher costs without significant improvement in the performance. You can make a wise choice by taking a look at types of VMs which can be provisioned.
3. Scaling
Category: Compute
There are 2 types of scaling:
- Scaling up – where the virtual compute resources scale by their size.
- Scaling out – where they scale in numbers.
In the cloud-native world, both options are available. Given the nature of templated size selection – the scaling up of resources is not always the best case since applications may experience bottlenecks in one of the aspects. Increasing the size of everything in a VM to address a single bottleneck creates under-utilized resources. This simply adds to the costs.
Besides, scaling up also means we are scaling a single point of failure. The better option would be to scale out in numbers. That way, even if a node fails, there are still others to serve the users and avoid potential losses.
Cloud providers offer an auto-scaling feature which lets you be sure that as many instances as you need are always up and running even if some of them fail in the meanwhile. This is done automatically.
But that does not mean there is no reason to worry about node failures. Ideally, the nodes should not fail at all, and autoscaling only provides a fallback mechanism as an attempt to recover from the loss. This in itself is a virtue.
Going a step ahead, Kubernetes capabilities provided by cloud-native platforms add an additional level of customization of resource allocation. From compute’s perspective, this means we have better ways to manage bottlenecks.
4. Serverless
Category: Compute
Going beyond containers – if you don’t want to worry about the vulnerability scans in images used, cluster management, OS, and orchestration, and you only want to write the code and let it run, then serverless is a great option.
In the serverless services offered by cloud providers, you are only expected to write “functions'' that define the logic for your hosted application. All the infrastructure required to run these functions is abstracted by the cloud provider platforms.
Apart from the huge cost benefits offered by serverless (topic for another day), developing applications on the serverless framework is the closest thing to cloud-native. The more cloud-native you are, the more services you can leverage.
It should be noted that serverless does not just mean writing code. The cloud providers may only provide a place to execute the incoming request. The way that request is processed and routed to appropriate queues and APIs requires leveraging additional services.
However, refactoring existing applications requires huge efforts, which is where containerization is an easier option to begin with. Applications, especially web services to be developed from scratch, are often good candidates for serverless.
5. Database Partitioning
Category: Memory & Database
Partitioning a database offers a clear advantage on performance. Think of it as a high level classification of the data itself that is stored in large volumes.
When a query is run against these volumes, chances are that the entire database or the storage volume is scanned to fetch the requested data. Partitioning reduces the scope of this scan, thus improving the response time. A good partitioning strategy is defined based on the stored data itself.
For example, an archive of all the newspapers from the year 2000 can be partitioned based on year, and further partitioned based on month and so on. So if you know the name and date of the newspaper you would like to read, it would be easier to find it in the archives.
Cloud platforms provide various services as far as the partitioning of the data is concerned. As opposed to the traditional ways, all the partitioning needs are handled by the platform itself once configured. So consider partitioning the data.
6. Dynamic Data Caching
Category: Memory & Database
Web applications serve multiple requests in parallel. These requests may require reading the data from the database. If the data is read frequently, each request would need to connect to the database, read it and make it available for the business layer.
If the data being read is the same, then it would make sense to store it in a cache for faster access. This avoids unnecessary, expensive, and frequent round trips to the database layer.
In a multi-node environment, every node may cache its own copy of data. Although it improves performance, it also creates multiple copies of the same data on multiple nodes so it is still very inefficient.
One of the workarounds is to enforce client affinity which makes sure that a particular request is always served by the same node in the cluster. If the node is busy, it introduces additional latency and having multiple nodes in the cluster does not serve the purpose.
This is where shared cache databases come into the picture. Redis and memcached are the most used shared cache databases, which are used in backend architecture of many web applications.
Shared cache databases are not the replacement for databases – they help in storing data for fast retrieval of temporary data. They are usually hosted between the business logic nodes and database.
Shared cache databases help consolidate database transactions and keep the database state consistent. Once installed and configured, you can use them to set and get values. So instead of maintaining the node-specific copy of data, using shared cache database helps keep the data, once stored, available for all the nodes.
Cloud providers offer support, solutions, and services to host Redis and memcached to enhance performance of the systems.
7. Consider Eventual Consistency
Category: Memory & Database
In terms of databases, consistency defines if the immediate reads are up-to-date with the latest written information. Applications that perform many IO tasks to the databases have the tendency to use locking mechanisms to make sure multiple intended writes happen in a consistent way.
However, when such frequently changing data is being read, especially where multiple reads are allowed, the data can either be consistent with the latest write or not.
When multiple readers are enabled, in some cases the database is also replicated to have a real-time or near real-time copy of the primary database (the purpose of which is to serve all the read requests).
In such cases if you need consistency, then that adds to the performance lag as all the read operations have to be suspended until the write operations are replicated on all the copies of the database.
When you're developing business critical services, distributed relational databases that have ACID compliance/guarantees can result in a rather slower system.
Eventual consistency is a feature mostly offered by NoSQL and Document databases. Eventual consistency is a guarantee that the data that is being read and displayed to the user is up-to-date with latest write and will be updated in the database.
Cloud providers offer NoSQL and Document database services which also offer eventual consistency. Improving system performance by enabling eventual consistency and simultaneously protecting data integrity is a challenge that needs an overarching solution.
Identify the cases where you can take advantage of eventual consistency and develop routines and transactions to support end-to-end data integrity. This will help improve performance. Cloud native solutions provide this ability, and eventual consistency also helps with cost optimizations.
8. Leverage The Backbone Network
Category: Network
As far as networking is concerned, well established Cloud-Native platforms have data centers and server farms in various locations spread across the globe. It doesn’t matter where the traffic is coming from – it's likely that these cloud providers have a datacenter available in their vicinity.
These data centers are connected with a backbone network which is also developed by the cloud providers that are dedicated for their inter-regional communication. This is a great advantage. If the application users live on multiple continents, deploying applications on the cloud inherently accelerates the delivery of your services thanks to these backbone networks.
Since this is a global network supporting all the services, hosting cloud-native applications can be served closer to the users regardless of their continent or country.
Direct and dedicated connections and VPNs are also used to connect on-prem or private data centers securely to the cloud infrastructure in the form of access points. In a way, establishing these connections helps onboard the organizations network on this backbone network, helping them reach their employees across the globe.
9. API Gateway Caching
Category: Network
Like other services, cloud providers provide services for hosting and configuring API gateways for your applications. Today, APIs are the first choice of interface for any web application.
API Gateways not only help develop these API paths, they are also seamlessly integrated with other services related to compute, storage, databases, functions, containers, orchestrations, queues, and so on. The rich Web UI makes it easy to configure API Gateways and maintain versions of the same.
Since APIs deal with sending and receiving payload data, there are several pre-built features which assist in formatting, encoding, and security of payloads. Since these advanced features are pre-built in these API Gateway services, the efforts required to configure these for optimum delivery are low.
You can leverage these features for automatic compression, decompression, classify and route requests to target service, enable cache to improve latency of application response.
10. CDNs
Category: Network
Considering the fact that cloud providers offer their own backbone network that carries dedicated traffic between their data centers, it becomes very convenient for them to provide CDN services as well.
Major cloud platforms offer CDN services that give really good results as far as content delivery of static data is concerned. Web applications being served to users via Web Browser typically use HTML, CSS, JS files to build the interactive user interface. These files are fairly static and do not change very frequently.
While applications are being deployed on cloud platforms, it makes sense to take advantage of CDN services to improve the network performance of these applications.
Conclusion
When we talk about optimizing the performance of the cloud-native system, there are many more factors involved. It is important to think about the system using various lenses – compute, storage, databases, and networking – and identify the bottlenecks by performing various load and stress tests.
Monitoring is an important feature which many major cloud companies provide, and is well-integrated with other services. Leverage these monitoring capabilities to analyse the performance bottlenecks and identify effective action items for change.
I have covered challenges and approaches with deeper insights in my FREE eBook published on my website Let's Do Tech. If you are interested in following more of the architectural stuff, do keep an eye on me. Social: Instagram, Twitter, LinkedIn, FB.