By Déborah Mesquita
Increase users’ trust and find bugs faster
 _With LIME we can have discussions like this about our models with everyone (thanks [Štefan](https://unsplash.com/@cikstefan" rel="noopener" target="blank" title=") for the pic!)
_With LIME we can have discussions like this about our models with everyone (thanks [Štefan](https://unsplash.com/@cikstefan" rel="noopener" target="blank" title=") for the pic!)
Even though we like the idea that we never make mistakes, every software can contain bugs. Assuming that we may use Machine Learning models to make decisions in the real world, a bug in our code can be very dangerous. Relying only on the prediction accuracy might not be a good idea, because if we get a good accuracy score we might not even consider that there is a bug in our data pipeline.
Most Machine Learning algorithms are black boxes, but LIME has a bold value proposition: explain the results of any predictive model. The tool can explain models trained with text, categorical, or continuous data. Today we are going to explain the predictions of a model trained to classify sentences of scientific articles.
First let's understand how LIME works. Then I'll show you how to build a deep learning model to classify the sentences (using AllenNLP) and explain the predictions with LIME.
Local Interpretable Model-agnostic Explanations (LIME)
Model-agnostic predictions are used when the algorithm doesn't try to work with the decision function of the models. LIME uses the local fidelity criterion:
[…] For an explanation to be meaningful it must at least be locally faithful, i.e. it must correspond to how the model behaves in the vicinity of the instance being predicted. — Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin
To create this vicinity of the instance, LIME perturbs the instance it will explain. The authors also note that local fidelity does not imply global fidelity:
[…] Features that are globally important may not be important in the local context, and vice versa. While global fidelity would imply local fidelity, identifying globally faithful explanations that are interpretable remains a challenge for complex models. — Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin
The image below presents a toy example of how LIME works. This is taken from the paper that presents the algorithm.
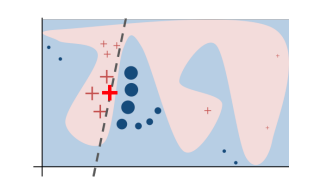 The red and blue areas represent the model complex decision function, which is unknown to LIME. The bold red cross is the data instance we want to explain.
The red and blue areas represent the model complex decision function, which is unknown to LIME. The bold red cross is the data instance we want to explain.
The red crosses and blue circles are sample instances that LIME creates uniformly at random. LIME gets the prediction for these instances and weights them by the proximity to the instance being explained — the bold red cross. In the image, proximity is represented by the size of each cross and each circle. The dashed line represents the explanation that is locally — but not globally — faithful.
Here is mushroom categorization produced with LIME:
 Explanation for categorical data
Explanation for categorical data
The model predicts if a mushroom is poisonous or not. We can see that odor=foul is indicative of a poisonous mushroom.
Since we perturb each categorical feature drawing samples according to the original training distribution, the way to interpret this is: if odor was not foul, on average, this prediction would be 0.26 less ‘poisonous’ — Tabular data tutorial
Now let's see how to use the tool.
Explaining predictions with LIME
There are three types of explainers:
- LimeTabularExplainer: explains predictions on tabular, or matrix, data
- LimeImageExplainer: explains predictions on image data
- LimeTextExplainer: explains text classifiers
In this article we are going to use the LimeTextExplainer. There are tutorials for all the other explainers here.
Currently the tool is restricting explanations to words that are present in documents, as explained here.
To build the LimeTextExplainer we only need to provide the class names, aka labels. Explaining an instance means we need to pass the instance data and a function that will provide the predictions. To do that we need a trained model. Let's build one using AllenNLP.
AllenNLP
AllenNLP is a framework to build Deep Learning models for Natural Language Processing. It's a fantastic tool. I'm still in love with how it makes the task of building Deep Learning models so easy.
The model we are going to build uses word embeddings to encode the input and the network has LSTM cells.
If you need to learn a little more about LSTM and RNN cells, check out this other article I wrote. I also explain how AllenNLP works in more detail there.
With the framework, we define the model architecture in a JSON file. This is the architecture of our model:
{
"dataset_reader": {
"type": "az_papers"
},
"train_data_path": "../../data/AZ_distribution/train/",
"model": {
"type": "sentence_classifier",
"text_field_embedder": {
"tokens": {
"type": "embedding",
"pretrained_file": "https://s3-us-west-2.amazonaws.com/allennlp/datasets/glove/glove.6B.100d.txt.gz",
"embedding_dim": 100,
"trainable": false
}
},
"title_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"sentence_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"classifier_feedforward": {
"input_dim": 400,
"num_layers": 2,
"hidden_dims": [200, 7],
"activations": ["relu", "linear"],
"dropout": [0.2, 0.0]
}
},
"iterator": {
"type": "bucket",
"sorting_keys": [["sentence", "num_tokens"], ["title", "num_tokens"]],
"batch_size": 64
},
"trainer": {
"num_epochs": 40,
"patience": 10,
"cuda_device": -1,
"grad_clipping": 5.0,
"validation_metric": "+accuracy",
"optimizer": {
"type": "adagrad"
}
}
}
This probably doesn't make any sense if you're new to AllenNLP. The goal of this article is to show how to use LIME, so we'll not dive deep into it. I try to explain more about AllenNLP on this other article. And, of course, the whole code to train the model is here.
The dataset is the original Argumentative Zoning corpus [AZ corpus]. It consists of 80 AZ-annotated conference articles in computational linguistics, originally drawn from arXiv. Each sentence has one of these labels:
- BKG: General scientific background
- OTH: Neutral descriptions of other people’s work
- OWN: Neutral descriptions of the own, new work
- AIM: Statements of the particular aim of the current paper
- TXT: Statements of textual organization of the current paper (in chapter 1, we introduce…)
- CTR: Contrastive or comparative statements about other work; explicit mention of weaknesses of other work
- BAS: Statements that own work is based on other work
To train the model we use this command:
python3 run.py train experiments/the_file_presented_before.json
--include-package newsgroups.dataset_readers
--include-package newsgroups.models
-s /tmp/our_model
Explaining the model predictions
To predict the class for each sentence, we use the title of the paper and the sentence itself. With AllenNLP this is how we do it:
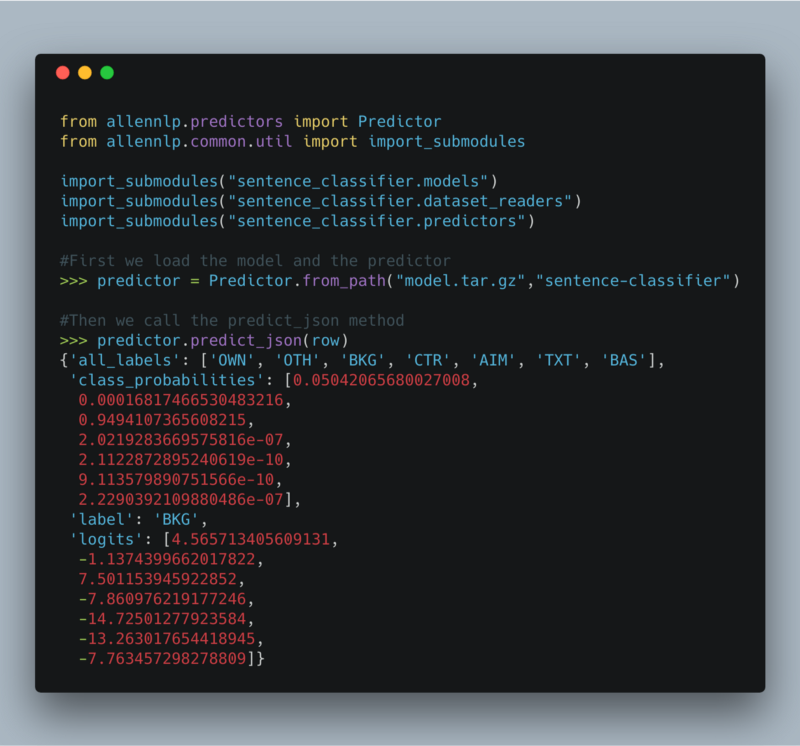 Making predictions with AllenNLP
Making predictions with AllenNLP
As I was saying earlier, the two key parameters of LimeTextExplainer.explain_instance() are the instance itself and a function that returns the prediction probability for each class — like the predict_proba function of scikit-learn. Here this function takes a list of d strings and outputs a (d, n_classes) NumPy array with the prediction probabilities.
The algorithm perturbs the input data by removing all occurrences of individual words and getting the predict probabilities for the new instances. I'm only interested in perturbing the words for the sentence part of the input, so this is how I defined the function:
#For each perturbed sentence we get the predict_proba from AllenNLP
predict_function = lambda x: np.array([predictor.predict_json(json.loads('{"title": "Incremental Interpretation of Categorial Grammar","sentence":"'+s+'"}'))['class_probabilities'] for s in x])
Then we import LIME, set the class_names, and call the explain_instance method:
from lime.lime_text import LimeTextExplainer
explainer = LimeTextExplainer(class_names=['OWN', 'OTH', 'BKG', 'CTR', 'AIM', 'TXT', 'BAS'])
row = json.loads('{"title": "Incremental Interpretation of Categorial Grammar", "sentence": "In processing a sentence using a lexicalised formalism we do not have to look at the grammar as a whole , but only at the grammatical information indexed by each of the words ."}')
exp = explainer.explain_instance(row["sentence"], predict_fn, num_features=10,top_labels=2)
#Show the results in notebook
exp.show_in_notebook(text=False)
And here is the result:

The sentence is classified as OWN — description of the work of the author. We can see why: the words “indexed”, “grammatical”, and “we”.
It looks like the word “the” has high relevance for OWN. This may only be because of the local fidelity and maybe it is a good idea to remove the stop-words.
Let's take a look at other examples:
 This one was easy to classify
This one was easy to classify
 Explanation for a general scientific background sentence
Explanation for a general scientific background sentence
Takeaways
Seeing what LIME is capable of, I think that being able to understand the reasons behind a prediction is a must for every Machine Learning project. Especially when our interests go beyond considering only the accuracy of the results.
The explanations can help users trust the predictions but it can also help us — data scientists — in identifying bugs or things that are not working as expected.
I'm working on a project that uses categorical data. Because I was using LIME to explain the predictions, I was able to find a bug early on in the process. The reasons for the predictions were not making sense, which made me dig deep into the code and find the bug. If I was only relying on the accuracy of the model, it would’ve taken me a long time to find the bug because the model had reasonably good accuracy scores.
So if you're building Machine Learning models please give LIME a try! For more information you can read the paper and check the repo on GitHub.
If you're working with NLP and Deep Learning also check AllenNLP.
All the code from this article can be found here. And thanks for reading! ?
If you found this article helpful, it would mean a lot if you click the ?? and share it on the web.
Follow me for more articles about Data Science and Machine Learning.