By Daniele Polencic
During the last few years, the industry has experienced a shift towards developing smaller and more focused applications.
It doesn’t come as a surprise that more and more companies are breaking their massive and static monoliths into a set of decoupled and independent components.
And rightly so.
Services that are tiny in size are:
- quicker to deploy — because you create and release them in smaller chunks
- easier to iterate on — since adding features happens independently
- resilient — the overall service can still function despite one of the components not being available
Smaller services are excellent from a product and development perspective.
But how does that cultural shift impact the infrastructure?
Managing infrastructure at scale
It turns out that things are rather simple when you deal with a few sparse applications.
You can count them with your hands, and you have plenty of time to dedicate to support and release.
In a large organisation, managing hundreds of applications is demanding, but still doable. You have several teams dedicated to developing, packaging and releasing applications.
Developing services out of smaller components, on the other hand, introduces a different challenge.
When for every application, you can refactor the same apps in a collection of four components, you have at least four times more apps to develop, package and release.

It’s not uncommon for a small service to be made out of a dozen components such as a front-end app, a backend API, an authorisation server, an admin application, etc.
Indeed when you develop services that interact with each other, you see an explosion of components deployed on your infrastructure.

It gets harder, though.
You’re probably wasting your money on compute resources
Most of the services are deployed to virtual machines such as Amazon EC2, Digital Ocean Droplets or Azure Virtual Machines.
Each virtual machine comes with an operating system that consumes part of the memory and CPU resources allocated to it.
When you create a 1GB of memory and 1 vCPU droplet on Digital Ocean, you end up using 700MB in memory and 0.8 vCPU after you remove the overhead of the operating system.

Or in other words, for every fifth virtual machine, the overhead adds up to a full virtual machine.
You pay for five but can use only four.
You can’t escape from it, even if you’re on bare metal.
You still need to run your services from a base operating system.
It’s okay, everybody needs to run an operating system — you say.
And you’re right.
However, the cash wasted on operating systems is only the tip of the iceberg.
You’re also wasting A LOT of money on resource utilisation
You have probably realised that when you break your services into smaller components, each of them comes with different resource requirements.
Some components such as data processing and data mining applications are CPU intensive. Others, such as servers for real-time applications might use more memory than CPU.
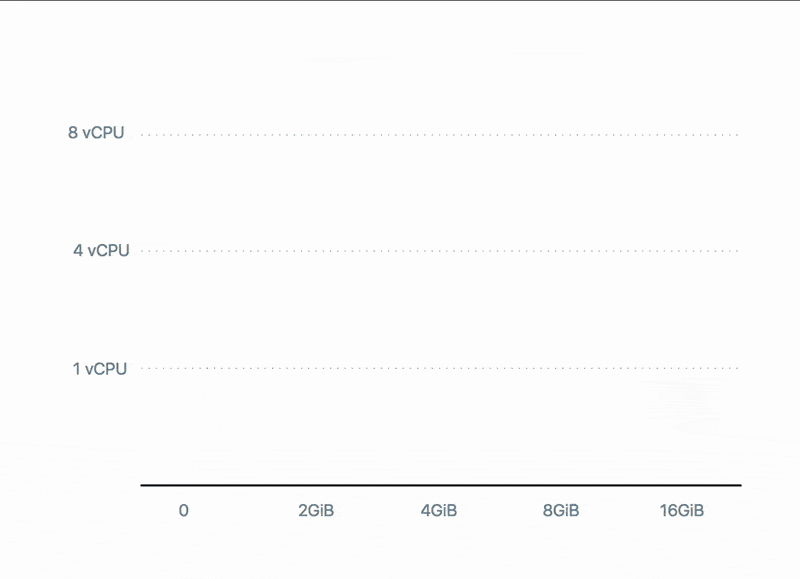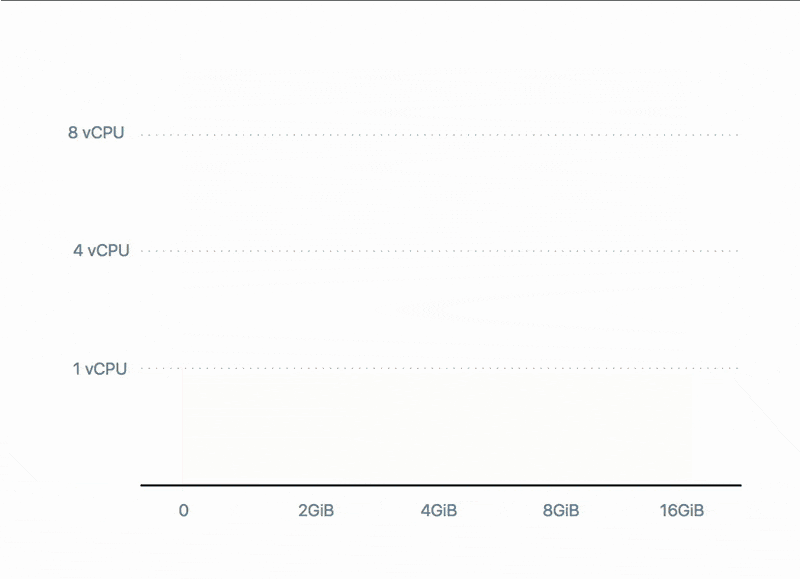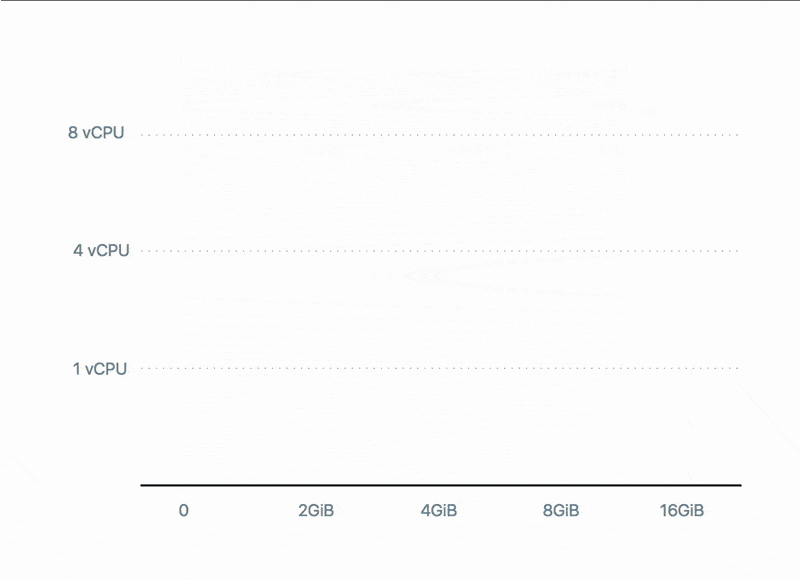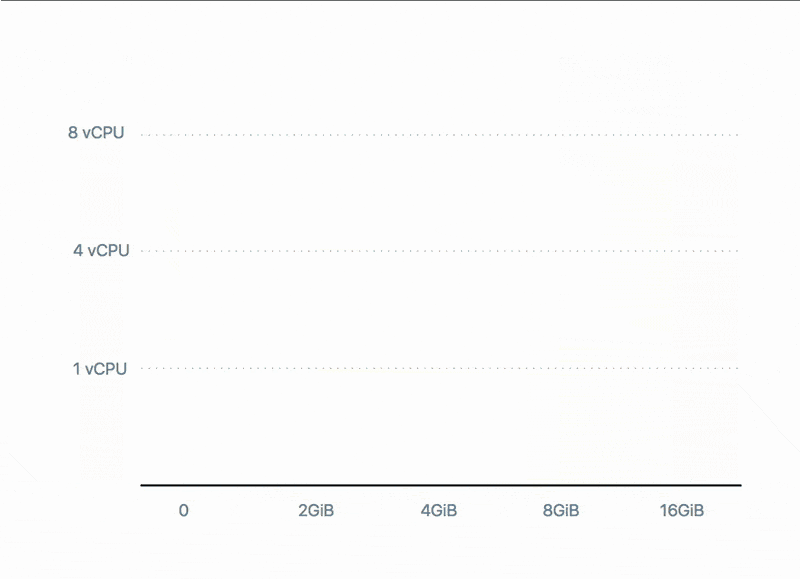
Amazon Web Services and the other cloud providers have indeed a long list of compute resources that fit every need: general purpose, CPU optimised, memory optimised, storage optimised and GPU computing.
You should strive to use the right virtual machine for your component. Ideally, it should match the memory consumption and CPU utilisation.
Are you working on a critical web component written in Java?
Perhaps you should use a c5.4xlarge optimised for compute-intensive workloads.
The closer you match the requirements, the better you’re utilising your resources.
In practice, this is somewhat uncommon, though.
Should you use a c5.2xlarge or a c5.4xlarge?
Does the next tier (8 vCPU and 16GB memory) make a difference?
It’s much easier to select a couple of computing profiles that are good enough in 80% of the cases and use those for all components.
In fact, what’s wrong with using mostly the same virtual machine for every workload?
Nothing at all, if you’re happy to wrap every component into a 2GB of memory and vCPU compute capacity.
Even if your component can run with only 1GB of memory.
Yes, you could optimise in the future.
But let’s be honest: it’s like changing tires while driving.
You put a lot of effort into tuning the system only to realise that the application changed again and you have to start from scratch.
So you end up taking the only sensible choice: selecting a small, medium and large profile for virtual machines and using them for all workloads.
You know you have to live with wasting hundreds of megabytes of RAM and plenty of CPU cycles.

If it makes you feel any better, there are plenty of companies suffering from similar inefficiencies.
Some utilise as little as 10% of the allocated resources.
You pay $1000 in EC2 instances on Amazon, you only actually use $100 of it.
That doesn’t sound like the best way to spend your budget.
You should get your money back on the resources you don’t use.
But why are those requirements so different anyway?!
When choosing the right tool does more harm than good
When developers have the freedom to use the right tool for the job they usually go wild.
Node.js for the front-end, Spring Boot for the backend API, Flask and Celery for the processing background jobs, React.js for the client-side, you name it.
The infrastructure becomes a theme park, hundreds of applications running on entirely different runtimes.
Having the right technology for the job enables greater iteration speed, but it usually comes with the extra burden of managing one more programming language.
While you could mitigate the proliferation of tools and languages, in practice, it’s more complicated than that.
Two applications sharing the same JVM runtime might rely on a different set of dependencies and libraries.
Perhaps one relies on ImageMagick to resize images.
The other relies on a binary such as PhantomJS or ZeroMQ to be available in its path.
You should package those dependencies alongside its application.
And so you end up dealing with dozens of configurations that are the same, but different in their unique way.
You shouldn’t treat the infrastructure as an afterthought. You should look after your dependencies and package them as you develop the application, right from the beginning.
Ideally, you should archive all of the parts necessary to run your component as a single bundle.
No more getting lost in chasing dependencies just before a release.
Yes, easier said than done.
Or maybe not.
Borrowing containers from the shipping industry
Information technology is not the only industry with the same problem.
Shipping goods in cargo around the globe is hard when you need to store items individually.
Imagine having thousands of boxes of all shapes and sizes to store in the hold. You should pay extra attention to how you pack the items because you don’t want to miss one when it’s time to unload.
The cargo industry came up with a solution: containers.
The cargo company doesn’t carry goods; it ships containers.
Do you want to ship all your goods safely? Place them in a container. When the container is unloaded, you’re guaranteed to have everything there.
You can apply the same principle to your applications.
Do you want to deploy your application and all its dependency safely?
Wrap them into a Linux container.
A Linux container is a like a cargo container, but it encapsulates all files, binaries, and libraries necessary to run your process.
Doesn’t that sound a lot like virtual machines?
Virtual machines on a diet
Indeed, if you squint and look from afar at virtual machines, they resemble containers.
They encapsulate the application and its dependencies like containers.
However, virtual machines are slow to start, usually larger and — as you learnt — a waste of resources.
In fact, you have to allocate a fixed number of CPU and memory to run your application.
They also have to emulate hardware and come with the extra baggage of an operating system.
Linux containers, on the other hand, are merely processes running on your host.
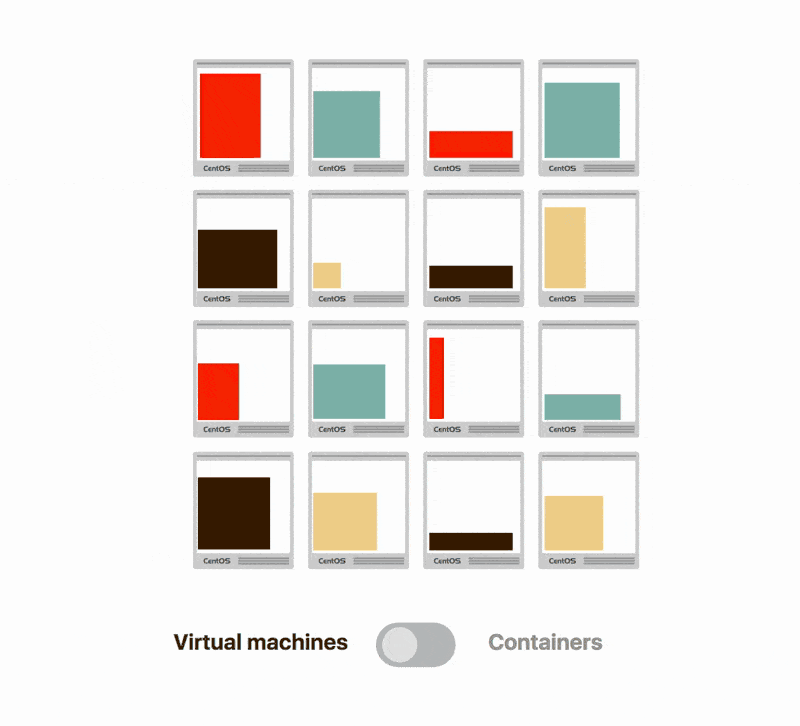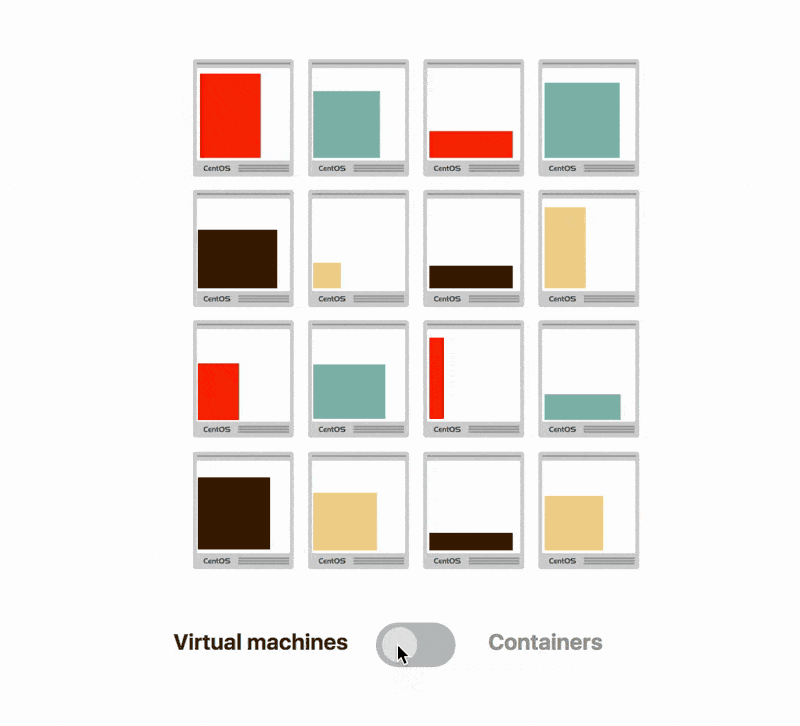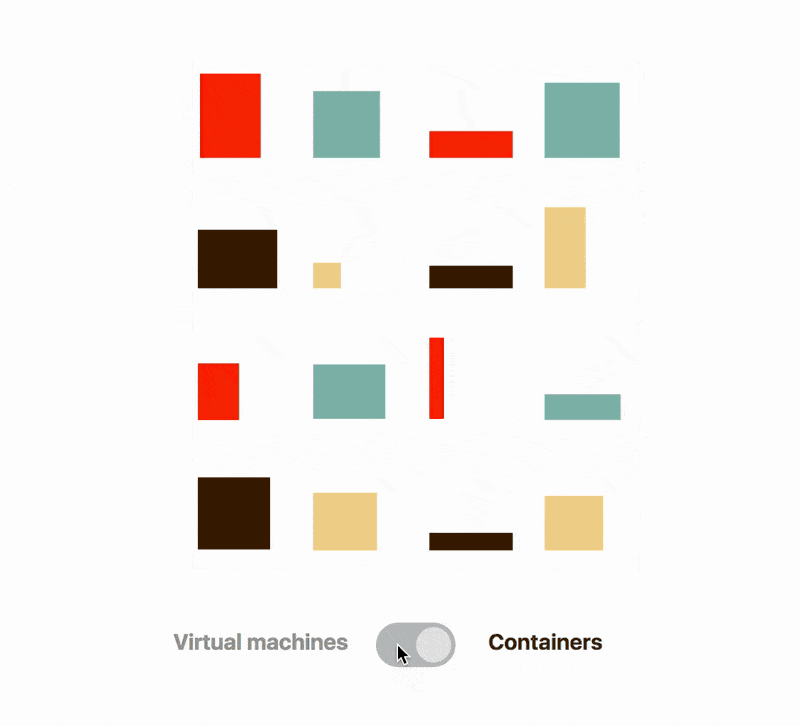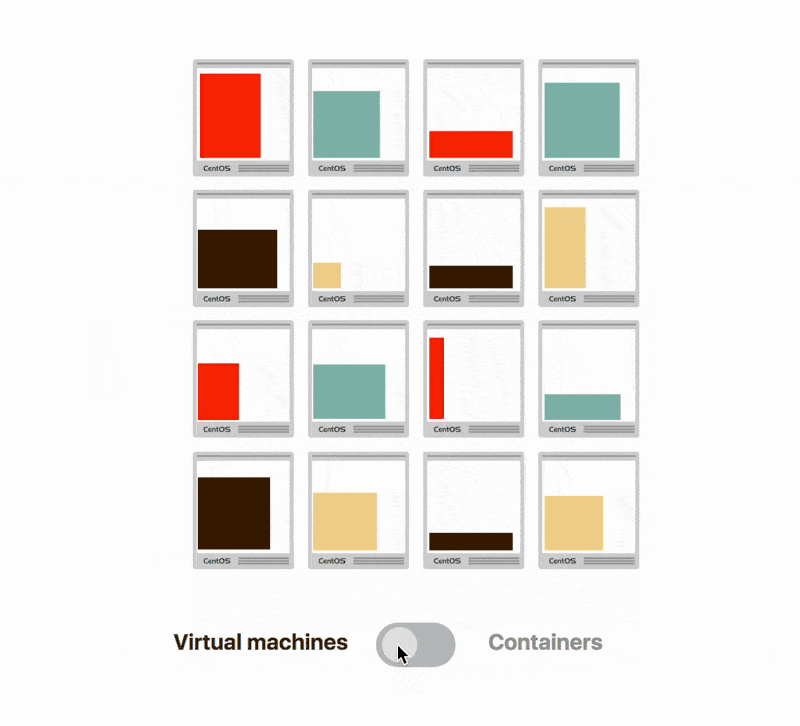
Indeed, for the same operating system and server, you could have dozens of containers running on that host.
And despite living on the same computer, processes running in containers can’t see each other.
Applications running inside containers are entirely isolated and can’t tell the difference between a virtual machine and a container.
That’s great news!
Linux containers are like virtual machines, but more efficient.
But what are those Linux containers made of, anyway?
Linux containers are isolated processes with benefits
The magic of containers comes from two features in the Linux kernel: control groups and namespaces.
Control groups are a convenient way to limit the CPU or memory that a particular process can use.
As an example, you could say that your component should use only 2GB of memory and one of your four CPU cores.
Namespaces, on the other hand, are in charge of isolating the process and limiting what it can see.
The component can only see the network packets that are directly related to it. It won’t be able to see all of the network packets flowing through the network adapter. Control groups and namespaces are low-level primitives.
With time, developers created more and more layers of abstractions to make it easier to control those kernel features.
One of the first abstractions was LXC, but the real deal was Docker that was released in 2013.
Docker not only abstracts the above kernel features but it is pleasant to work with.
Running a Docker container is as simple as:
docker run <my-container>
And since all containers implement a standard interface, you can run any other container with the same command:
docker run mysql
And you have a MySQL database.
Portability of the application and a standard interface to create and run processes is what makes containers so popular.
Containers are great!
- You saved money on running dozens of operating systems ✅
- You packaged applications as portable units ✅
- You have a proliferation of containers ❌
It sounds like containers haven’t solved all problems after all.
You need a way to manage containers.
Managing containers at scale
When you have hundreds if not thousands of containers, you should find a way to run multiple containers on the same server. And you should plan for containers to be spread on multiple servers too.
So you can distribute the load across several nodes and prevent that a single failure could take down the entire service.
Keeping track of where every container is deployed in your infrastructure doesn’t sound like the best use of your time.
Perhaps there’s a way to automate it?
And what if you could have an algorithm deciding where to place those containers too?
Perhaps it could be so smart to pack containers efficiently so to maximise server density. Maybe even keep a list of deployed containers and their host.
It turns out that someone had precisely that idea and came up with a solution.
Kubernetes, the mighty container orchestrator
Kubernetes was initially a Google creation.
Google was running a technology similar to containers and had to find an efficient way to schedule workloads.
They didn’t want to keep and manually update a long list of containers and servers. So they decided to write a platform that could automatically analyse resource utilisation, schedule and deploy containers.
But it was closed source.
A few Googlers decided to rewrite the platform as an open source effort. And the rest is history.
So what’s Kubernetes?
You can think of Kubernetes as a scheduler.
Kubernetes inspects your infrastructure (bare metal or cloud, public or private) and measures CPU and memory for each computer.
When you request to deploy a container, Kubernetes identifies the memory requirements for your container and finds the best server that satisfies your request.
You don’t decide where the application is deployed. The data centre is abstracted away from you.
In other words, Kubernetes will play Tetris with your infrastructure.
Docker containers are the blocks, servers are the boards, and Kubernetes is the player.

Having Kubernetes efficiently packing your infrastructure means that you get more computing for your money. You can do a lot more with a lot less.
And your overall bill usage should decrease as a result of that.
Remember the companies using only 10% of their allocated resource?
Well, Kubernetes just saved your day.
But there’s more.
Kubernetes has a killer feature that’s usually forgotten or dismissed.
Kubernetes as an API layer over your data centre
Everything you do in Kubernetes is one API call away from you.
Do you need to deploy a container? There’s a REST endpoint for that.
Perhaps you wish to provision a load balancer? Not a problem. Just call this API.
Do you wish to provision storage? Please send a POST request to this URL.
Everything you do in Kubernetes is calling APIs.
And there are plenty of good reasons to be excited about that:
- You can create scripts and daemons that interact with the API programmatically
- The API is versioned; when you upgrade your cluster you can keep using the old API and gradually migrate
- You can install Kubernetes in any cloud provider or data centre, and you can leverage the same API
You can think of Kubernetes as a layer on top of your infrastructure.
And since this layer is generic and it can be installed anywhere, you can always take it with you.
Amazon Web Services is too expensive?
No problemo.
You can install Kubernetes on Google Cloud Platform and move your workloads there.
Or perhaps you can keep both because having a strategy for high availability always comes in handy.
But maybe you don’t believe me.
It’s too good to be true, and I’m selling smoke and mirrors.
Let me show you.
Saving on your cloud bill with Kubernetes
Netlify is a platform for building, deploying, and managing static websites.
It has its own CI pipeline, so every time you push a change to a repository, your website is rebuilt.
Netlify managed to migrate to Kubernetes, double their user base, but still maintained the costs unchanged.
That’s great news!
Imagine saving 50% of your Google Cloud Platform bill!
But Netlify isn’t the only one.
Qbox — a company that focuses on hosted Elastic Search — managed to save again 50% per month on AWS bills!
In the process, they also open sourced their efforts in multi-cloud operations.
If you’re still not impressed, you should check out the press made by OpenAI.
OpenAI is a non-profit research company that focuses on artificial intelligence and machine learning. They wrote an algorithm to play the multi player online game Dota as any human player would.
But they went the extra step and trained a team of machines to play together.
And they used Kubernetes to scale their machine learning model in the cloud.
Wondering the details of their cluster?
128000 vCPUs
That’s about 16000 MacBook Pros.
256 Nvidia Tesla P100
That’s 2100 Teraflops 16-bit floating-point performance.
The same as you’d run 525 PlayStation 4s.
Can you guess the cost per hour?
No?
Only $1280/hr for 128000 vCPU and $400 for the 256 Nvidia P100.
That’s not a lot considering that winning Dota tournaments could net you prizes in the order of millions of dollars.
So, what are you waiting for?
Get ready to adopt Kubernetes and save on your cloud bill!
Final notes
Kubernetes and containers are here to stay.
With backing from companies such as Google, Microsoft, Red Hat, Pivotal, Oracle, IBM, and many more it’s hard to believe that it won’t catch on.
Many companies are getting a head start on Kubernetes and joining the revolution.
Not just startups and SMEs, but big corporations such as banks, financial institutions and insurance companies are betting on containers and Kubernetes to be the future.
Even companies invested in the Internet of Things and embedded systems.
It’s still early days and the community has time to mature, but you should keep a close eye on the innovation in this space.
That’s all folks!
Many thanks to Andy Griffiths, John Topley and Walter Miani for reading a draft of this post and offering some invaluable suggestions.
If you enjoyed this article, you might find interesting reading:
- Getting started with Docker and Kubernetes on Windows 10 where you’ll get your hands dirty and install Docker and Kubernetes in your Windows environment.
- 3 simple tricks for smaller Docker images. Docker images don’t have to be large. Learn how to put your Docker images on a diet!
Become an expert at deploying and scaling applications in Kubernetes
Get a head start with our hands-on courses and learn how to master scalability in the cloud.
Learn how to:
- Handle the busiest traffic websites without breaking a sweat
- Scale your jobs to thousands of servers and reduce the waiting time from days to minutes
- Enjoy peace of mind knowing that your apps are highly available with a multi-cloud setup
- Save ton of cash on your cloud bill by using only the resources your need
- Supercharge your delivery pipeline and deploy application around the clock
Become an expert in Kubernetes →
The article was originally published at learnk8s.io