
By Tom
Take a step into program architecture, and learn how to make a practical solution for a real business problem with NodeJS Streams with this article.

A Detour: Fluid Mechanics
One of the greatest strengths of software is that we can develop abstractions which let us reason about code, and manipulate data, in ways we can understand. Streams are one such class of abstraction.
In simple fluid mechanics, the concept of a streamline is useful for reasoning about the way fluid particles will move, and the constraints applied to them at various points in a system.
For example, say you’ve got some water flowing through a pipe uniformly. Halfway down the pipe, it branches. Generally, the water flow will split evenly into each branch. Engineers use the abstract concept of a streamline to reason about the water’s properties, such as its flow rate, for any number of branches or complex pipeline configurations. If you asked an engineer what he assumed the flow rate through each branch would be, he would rightly reply with “one half”, intuitively. This expands out to an arbitrary number of streamlines mathematically.
Streams, conceptually, are to code what streamlines are too fluid mechanics. We can reason about data at any given point by considering it as part of a flow. Rather than worrying about implementation details between how it’s stored. Arguably you could generalize this to some universal concept of a pipeline that we can use between disciplines. A sales funnel comes to mind but that’s tangential and we’ll cover it later. The best example of streams, and one you absolutely must familiarise yourself with if you haven’t already are UNIX pipes:
cat server.log | grep 400 | less
We affectionately call the | character a pipe. Based on its function we’re piping the output of one program as the input of another program. Effectively setting up a pipeline.
(Also, it looks like a pipe.)
If you’re like me and wonder at this point why this is necessary, ask yourself why we use pipelines in real life. Fundamentally, it’s a structure that eliminates storage between processing points. We don’t need to worry about storing barrels of oil if it’s pumped.
Go figure that in software. The clever developers and engineers who wrote the code for piping data set it up such that it never occupies too much memory on a machine. No matter how big the logfile is above, it won’t hang the terminal. The entire program is a process handling infinitesimal data points in a stream, rather than containers of those points. The logfile never gets loaded into memory all at once, but rather in manageable parts.
I don’t want to reinvent the wheel here. So now that I’ve covered a metaphor for streams and the rationale for using them, Flavio Copes has a great blog post covering how they’re implemented in Node. Take as long as you need to cover the basics there, and when you’re ready come back and we’ll go over a use case.
The Situation
So, now that you’ve got this tool in your toolbelt, picture this:
You’re on the job and your manager / legal / HR / your client / (insert stakeholder here) has approached you with a problem. They spend way too long poring over structured PDFs. Of course, normally people won’t tell you such a thing. You’ll hear, “I spend 4 hours doing data entry.” Or “I look through price tables.” Or, “I fill out the right forms so we get our company branded pencils every quarter”.
Whatever it is, if their work happens to involve both (a) the reading of structured PDF documents and (b) the bulk usage of that structured information. Then you can step in and say, “Hey, we might be able to automate that and free up your time to work on other things”.

So for the sake of this article, let’s come up with a dummy company. Where I come from, the term “dummy” refers to either an idiot or a baby’s pacifier. So let’s imagine up this fake company that manufactures pacifiers. While we’re at it let’s jump the shark and say they’re 3D printed. The company operates as an ethical supplier of pacifiers to the needy who can’t afford the premium stuff themselves.
(I know how dumb it sounds, suspend your disbelief please.)
Todd sources the printing materials that go into DummEth’s products, and has to ensure that they meet three key criteria:
- they’re food-grade plastic, to preserve babies’ health,
- they’re cheap, for economical production, and
- they’re sourced as close as possible, to support the company’s marketing copy stating that their supply chain is also ethical and pollutes as little as possible.
The Project
So it’s easier to follow along, I’ve set up a GitLab repo you can clone and use. Make sure your installations of Node and NPM are up to date too.
Basic Architecture: Constraints
Now, what are we trying to do? Let’s assume that Todd works well in spreadsheets, like a lot of office workers. For Todd to sort the proverbial 3D printing wheat from the chaff, it’s easier for him to gauge materials by food grade, price per kilogram, and location. It’s time to set some project constraints.
Let’s assume that a material’s food grade is rated on a scale from zero to three. With zero meaning banned-in-California BPA-rich plastics. Three meaning commonly used non-contaminating materials, like low density polyethylene. This is purely to simplify our code. In reality we’d have to somehow map textual descriptions of these materials (e.g.: “LDPE”) to a food grade.
Price per kilogram we can assume to be a property of the material given by its manufacturer.
Location, we’re going to simplify and assume to be a simple relative distance, as the crow flies. At the opposite end of the spectrum there’s the overengineered solution: using some API (e.g.: Google Maps) to discern the rough travel distance a given material would travel to reach Todd’s distribution center(s). Either way, let’s say we’re given it as a value (kilometres-to-Todd) in Todd’s PDFs.
Also, let’s consider the context we’re working in. Todd effectively operates as an information gatherer in a dynamic market. Products come in and out, and their details can change. This means we’ve got an arbitrary number of PDFs that can change — or more aptly, be updated — at any time.
So based on these constraints, we can finally figure out what we want our code to accomplish. If you’d like to test your design ability, pause here and consider how you’d structure your solution. It might not look the same as what I’m about to describe. That’s fine, as long as you’re providing a sane workable solution for Todd, and something you wouldn’t tear your hair out later trying to maintain.
Basic Architecture: Solutions
So we’ve got an arbitrary number of PDFs, and some rules for how to parse them. Here’s how we can do it:
- Set up a Stream object that can read from some input. Like a HTTP client requesting PDF downloads. Or a module we’ve written that reads PDF files from a directory in the file system.
- Set up an intermediary Buffer. This is like the waiter in a restaurant delivering a finished dish to its intended customer. Every time a full PDF gets passed into the stream, we flush those chunks into the buffer so it can be transported.
- The waiter (Buffer) delivers the food (PDF data) to the customer (our Parsing function). The customer does what they please (convert to some spreadsheet format) with it.
- When the customer (Parser) is done, let the waiter (Buffer) know that they’re free and can work on new orders (PDFs).
You’ll notice that there’s no clear end to this process. As a restaurant, our Stream-Buffer-Parser combo never finishes, until of course there’s no more data — no more orders — coming in.
Now I know there’s not a lick of code just yet. This is crucial. It’s important to be able to reason about our systems prior to writing them. Now, we won’t get everything right the first time even with a priori reasoning. Things always break in the wild. Bugs need to be fixed.
That said, it’s a powerful exercise in restraint and foresight to plan out your code prior to writing it. If you can simplify systems of increasing complexity into manageable parts and analogies, you’ll be able to increase your productivity exponentially, as the cognitive stress from those complexities fades into well-designed abstractions.
So in the grand scheme of things, it looks something like this:
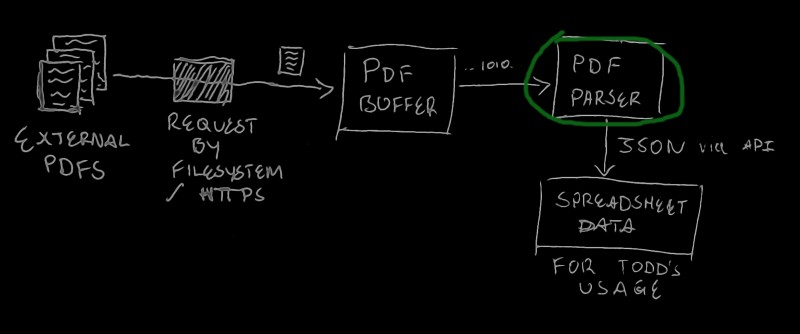
Introducing Dependencies
Now as a disclaimer, I should add that there is a whole world of thought around introducing dependencies into your code. I’d love to cover this concept in another post. In the meantime let me just say that one of the fundamental conflicts at play is the one between our desire to get our work done quickly (i.e.: to avoid NIH syndrome), and our desire to avoid third-party risk.
Applying this to our project, I opted to offload the bulk of our PDF processing to the pdfreader module. Here are a few reasons why:
- It was published recently, which is a good sign that the repo is up-to-date.
- It has one dependency — that is, it’s just an abstraction over another module — which is regularly maintained on GitHub. This alone is a great sign. Moreover, the dependency, a module called pdf2json, has hundreds of stars, 22 contributors, and plenty of eyeballs keeping a close eye on it.
- The maintainer, Adrian Joly, does good bookkeeping in GitHub’s issue tracker and actively tends to users and developers’ questions.
- When auditing via NPM (6.4.1), no vulnerabilities are found.
So all in all, it seems like a safe dependency to include.
Now, the module works in a fairly straightforward way, although its README doesn’t explicitly describe the structure of its output. The cliff notes:
- It exposes the
PdfReaderclass to be instantiated - This instance has two methods for parsing a PDF. They return the same output and only differ in the input:
PdfReader.parseFileItemsfor a filename, andPdfReader.parseBufferfrom data that we don’t want to reference from the filesystem. - The methods ask for a callback, which gets called each time the
PdfReaderfinds what it denotes as a PDF item. There are three kinds. First, the file metadata, which is always the first item. Second is page metadata. It acts as a carriage return for the coordinates of text items to be processed. Last is text items which we can think of as simple objects / structs with a text property, and floating-point 2D AABB coordinates on the page. - It’s up to our callback to process these items into a data structure of our choice and also to handle any errors thrown to it.
Here’s a code snippet as an example:
const { PdfReader } = require('pdfreader');
// Initialise the readerconst reader = new PdfReader();
// Read some arbitrarily defined bufferreader.parseBuffer(buffer, (err, item) =>; {
if (err) console.error(err);
else if (!item) /* pdfreader queues up the items in the PDF and passes them to * the callback. When no item is passed, it's indicating that * we're done reading the PDF. */ console.log('Done.');
else if (item.file) // File items only reference the PDF's file path. console.log(`Parsing ${item.file && item.file.path || 'a buffer'}`)
else if (item.page) // Page items simply contain their page number. console.log(`Reached page ${item.page}`);
else if (item.text) {
// Text items have a few more properties: const itemAsString = [ item.text, 'x: ' + item.x, 'y: ' + item.y, 'w: ' + item.width, 'h: ' + item.height, ].join('\n\t');
console.log('Text Item: ', itemAsString);
}
});
Todd’s PDFs
Let’s return to the Todd situation, just to provide some context. We want to store the data pacifiers based on three key criteria:
- their food-grade, to preserve babies’ health,
- their cost, for economical production, and
- their distance to Todd, to support the company’s marketing copy stating that their supply chain is also ethical and pollutes as little as possible.
I’ve hardcoded a simple script that randomizes some dummy products, and you can find it in the /data directory of the companion repo for this project. That script writes that randomized data to JSON files.
There’s also a template document in there. If you’re familiar with templating engines like Handlebars, then you’ll understand this. There are online services — or if you’re feeling adventurous, you can roll your own — that take JSON data and fill in the template, and give it back to you as a PDF. Maybe for completeness’ sake, we can try that out in another project. Anyway: I’ve used such a service to generate the dummy PDFs we’ll be parsing.
Here’s what one looks like (extra whitespace has been cropped out):

We’d like to yield from this PDF some JSON that gives us:
- the requisition ID and date, for bookkeeping purposes,
- the SKU of the pacifier, for unique identification, and
- the pacifier’s properties (name, food grade, unit price, and distance), so Todd can actually use them in his work.
How do we do this?
Reading the Data
First let’s set up the function for reading data out of one of these PDFs, and extracting pdfreader’s PDF items into a usable data structure. For now, let’s have an array representing the document. Each item in the array is an object representing a collection of all text elements on the page at that object’s index. Each property in the page object has a y-value for its key, and an array of the text items found at that y-value for its value. Here’s the diagram, so it’s simpler to understand:
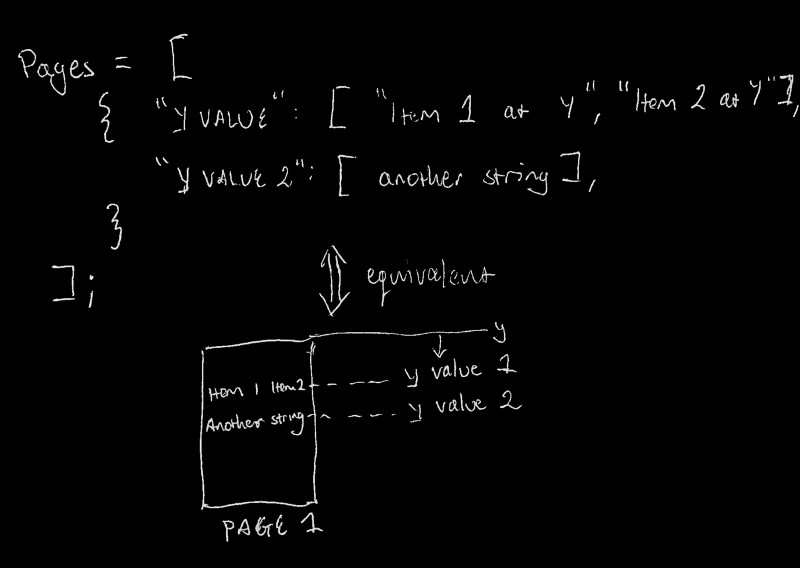
The readPDFPages function in /parser/index.js handles this, similarly to the example code written above:
/* Accepts a buffer (e.g.: from fs.readFile), and parses * it as a PDF, giving back a usable data structure for * application-specific, second-level parsing. */function readPDFPages (buffer) { const reader = new PdfReader();
// We're returning a Promise here, as the PDF reading // operation is asynchronous. return new Promise((resolve, reject) =>; {
// Each item in this array represents a page in the PDF let pages = [];
reader.parseBuffer(buffer, (err, item) =>; {
if (err) // If we've got a problem, eject! reject(err)
else if (!item) // If we're out of items, resolve with the data structure resolve(pages);
else if (item.page) // If the parser's reached a new page, it's time to // work on the next page object in our pages array. pages.push({});
else if (item.text) {
// If we have NOT got a new page item, then we need // to either retrieve or create a new "row" array // to represent the collection of text items at our // current Y position, which will be this item's Y // position.
// Hence, this line reads as, // "Either retrieve the row array for our current page, // at our current Y position, or make a new one" const row = pages[pages.length-1][item.y] || [];
// Add the item to the reference container (i.e.: the row) row.push(item.text);
// Include the container in the current page pages[pages.length-1][item.y] = row;
}
}); });
}
So now passing a PDF buffer into that function, we’ll get some organized data. Here’s what I got from a test run, and printing it to JSON:
[ { '3.473': [ 'PRODUCT DETAILS REQUISITION' ], '4.329': [ 'Date: 23/05/2019' ], '5.185': [ 'Requsition ID: 298831' ], '6.898': [ 'Pacifier Tech', 'Todd Lerr' ], '7.754': [ '123 Example Blvd', 'DummEth Pty. Ltd.' ], '8.61': [ 'Timbuktu', '1337 Leet St' ], '12.235': [ 'SKU', '6308005' ], '13.466': [ 'Product Name', 'Square Lemon Qartz Pacifier' ], '14.698': [ 'Food Grade', '3' ], '15.928999999999998': [ '$ / kg', '1.29' ], '17.16': [ 'Location', '55' ] } ]
If you look carefully you’ll notice that there’s a spelling error in the original PDF. “Requisition” is misspelled as “Requsition”. The beauty of our parser is that we don’t particularly care for errors like these in our input documents. As long as they’re structured correctly, we can extract data from them accurately.
Now we just need to organize this into something a bit more usable (as if we’d expose it via API). The structure we’re looking for is something along the lines of this:
{ reqID: '000000', date: 'DD/MM/YYYY', // Or something else based on geography sku: '000000', name: 'Some String We Have Trimmed', foodGrade: 'X', unitPrice: 'D.CC', // D for Dollars, C for Cents location: 'XX',}
An Aside: Data Integrity
Why are we including the numbers as strings? It’s based on the risk of parsing. Let’s just say that we coerced all of our numbers to strings:
The unit price and location would be fine — they are supposed to be countable numbers after all.
The food grade, for this very limited project, technically is safe. No data gets lost when we coerce it — but if it’s effectively a classifier, like an Enum, so it’s better off kept as a string.
The requisition ID and SKU however, if coerced to strings, could lose important data. If the ID for a given requisition starts with three zeros and we coerce that to a number, well, we’ve just lost those zeros and we’ve garbled the data.
So because we want data integrity when reading the PDFs, we just leave everything as a String. If the application code wants to convert some fields to numbers to make them usable for arithmetic or statistical operations, then we’ll let the coercion occur at that layer. Here we just want something that parses PDFs consistently and accurately.
Restructuring the Data
So now we’ve got Todd’s information, we just need to organize it in a usable way. We can use a variety of array and object manipulation functions, and here MDN is your friend.
This is the step where everyone has their own preferences. Some prefer the method that just gets the job done and minimizes dev time. Others prefer to scout for the best algorithm for the job (e.g.: cutting down iteration time). It’s a good exercise to see if you can come up with a way to do this and compare it to what I got. I’d love to see better, simpler, faster, or even just different ways to accomplish the same goal.
Anyway, here’s how I did it: the parseToddPDF function in /parser/index.js.
function parseToddPDF (pages) {
const page = pages[0]; // We know there's only going to be one page
// Declarative map of PDF data that we expect, based on Todd's structure const fields = { // "We expect the reqID field to be on the row at 5.185, and the // first item in that array" reqID: { row: '5.185', index: 0 }, date: { row: '4.329', index: 0 }, sku: { row: '12.235', index: 1 }, name: { row: '13.466', index: 1 }, foodGrade: { row: '14.698', index: 1 }, unitPrice: { row: '15.928999999999998', index: 1 }, location: { row: '17.16', index: 1 }, };
const data = {};
// Assign the page data to an object we can return, as per // our fields specification Object.keys(fields) .forEach((key) =>; {
const field = fields[key]; const val = page[field.row][field.index];
// We don't want to lose leading zeros here, and can trust // any application / data handling to worry about that. This is // why we don't coerce to Number. data[key] = val;
});
// Manually fixing up some text fields so they're usable data.reqID = data.reqID.slice('Requsition ID: '.length); data.date = data.date.slice('Date: '.length);
return data;
}
The meat and potatoes here is in the forEach loop, and how we’re using it. After retrieving the Y positions of each text item previously, it’s simple to specify each field we want as a position in our pages object. Effectively providing a map to follow.
All we have to do then is declare a data object to output, iterate over each field we specified, follow the route as per our spec, and assign the value we find at the end to our data object.
After a few one-liners to tidy up some string fields, we can return the data object and we’re off to the races. Here’s what it looks like:
{ reqID: '298831', date: '23/05/2019', sku: '6308005', name: 'Square Lemon Qartz Pacifier', foodGrade: '3', unitPrice: '1.29', location: '55' }
Putting it all together
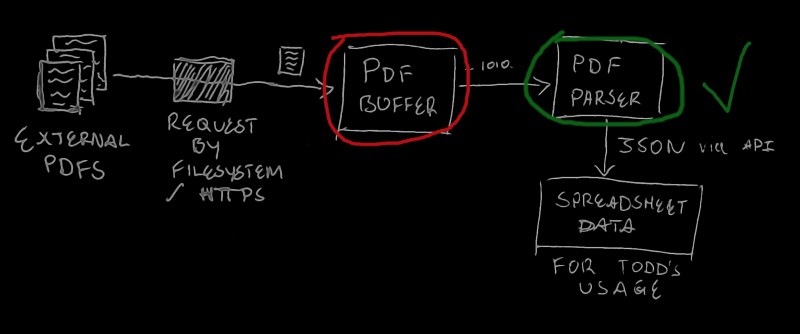
Now we’ll move on to building out some concurrency for this parsing module so we can operate at scale, and recognize some important barriers to doing so. The diagram above is great for understanding the context of the parsing logic. It doesn’t do much for understanding how we’re going to parallelize it. We can do better:
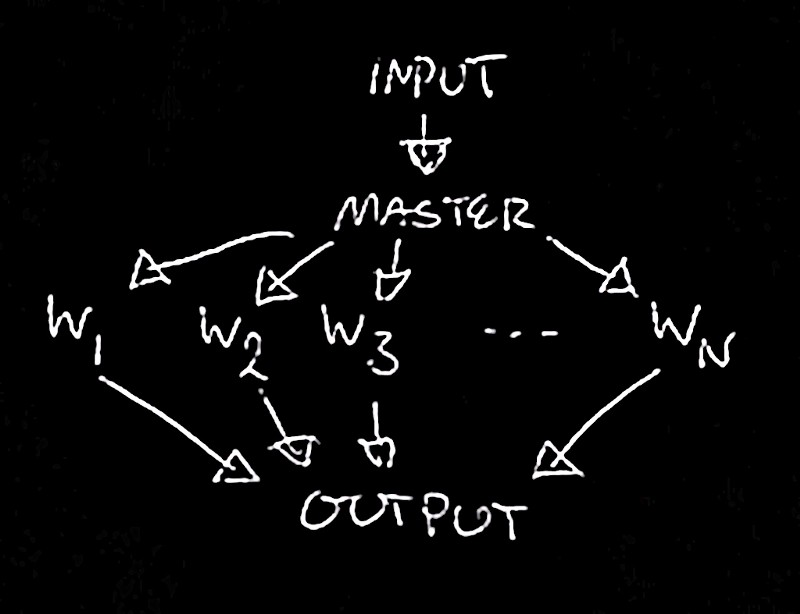
Trivial, I know, and arguably way too textbook-y generalized for us to practically use, but hey, it’s a fundamental concept to formalize.
Now first and foremost we need to think about how we’re going to handle the input and output of our program, which will essentially be wrapping the parsing logic and then distributing it amongst parser worker processes. There are many questions we can ask here and many solutions:
- is it going to be a command line application?
- Is it going to be a consistent server, with a set of API endpoints? This has its own host of questions — REST or GraphQL, for example?
- Maybe it’s just a skeleton module in a broader codebase — for example, what if we generalized our parsing across a suite of binary documents and wanted to separate the concurrency model from the particular source file type and parsing implementation?
For simplicity’s sake, I’m going to wrap the parsing logic in a command-line utility. This means it’s time to make a bunch of assumptions:
- does it expect file paths as input, and are they relative or absolute?
- Or instead, does it expect concatenated PDF data, to be piped in?
- Is it going to output data to a file? Because if it is, then we’re going to have to provide that option as an argument for the user to specify…
Handling Command Line Input
Again, keeping things as simple as possible: I’ve opted for the program to expect a list of file paths, either as individual command line arguments:
node index file-1.pdf file-2.pdf … file-n.pdf
Or piped to standard input as a newline-separated list of file paths:
# read lines from a text file with all our pathscat files-to-parse.txt | node index# or perhaps just list them from a directoryfind ./data -name “*.pdf” | node index
This allows the Node process to manipulate the order of those paths in any way it sees fit, which allows us to scale the processing code later. To do this, we’re going to read the list of file paths, whichever way they were provided, and divvy them up by some arbitrary number into sub-lists. Here’s the code, the getTerminalInput method in ./input/index.js:
function getTerminalInput (subArrays) {
return new Promise((resolve, reject) =>; {
const output = []; if (process.stdin.isTTY) {
const input = process.argv.slice(2);
const len = Math.min(subArrays, Math.ceil(input.length / subArrays));
while (input.length) { output.push(input.splice(0, len)); }
resolve(output);
} else { let input = ''; process.stdin.setEncoding('utf-8');
process.stdin.on('readable', () => { let chunk; while (chunk = process.stdin.read()) input += chunk; });
process.stdin.on('end', () => { input = input.trim().split('\n');
const len = Math.min(input.length, Math.ceil(input.length / subArrays));
while (input.length) { output.push(input.splice(0, len)); }
resolve(output); }) } });
}
Why divvy up the list? Let’s say that you have an 8-core CPU on consumer-grade hardware, and 500 PDFs to parse.
Unfortunately for Node, even though it handles asynchronous code fantastically thanks to its event loop, it only runs on one thread. To process those 500 PDFs, if you’re not running multithreaded (i.e.: multiple process) code, you’re only using an eighth of your processing capacity. Assuming that memory efficiency isn’t a problem, you could process the data up to eight times faster by taking advantage of Node’s built-in parallelism modules.
Splitting up our input into chunks allows us to do that.
As an aside, this is essentially a primitive load balancer and clearly assumes that the workloads presented by parsing each PDF are interchangeable. That is, that the PDFs are the same size and hold the same structure.
This is obviously a trivial case, especially since we’re not taking into account error handling in worker processes and which worker is currently available to handle new loads. In the case where we would have set up an API server to handle incoming parsing requests, we would have to consider these extra needs.
Clustering our code
Now that we have our input split into manageable workloads, admittedly in a contrived way — I’d love to refactor this later — let’s go over how we can cluster it. So it turns out Node has two separate modules for setting up parallel code.
The one we’re going to use, the cluster module, basically allows a Node process to spawn copies of itself and balance processing between them as it sees fit.
This is built on top of the child_process module, which is less tightly coupled with parallelizing Node programs themselves and allows you to spawn other processes, like shell programs or another executable binary, and interface with them using standard input, output, et cetera.
I highly recommend reading through the API docs for each module, since they’re fantastically written, and even if you’re like me and find purposeless manual reading boring and total busy-work, at least familiarise yourself with the introductions to each module will help you ground yourself in the topic and expand your knowledge of the Node ecosystem.
So let’s walk through the code. Here it is in bulk:
const cluster = require('cluster');const numCPUs = require('os').cpus().length;
const { getTerminalInput } = require('./input');
(async function main () {
if (cluster.isMaster) {
const workerData = await getTerminalInput(numCPUs);
for (let i = 0; i < workerData.length; i++) {
const worker = cluster.fork(); const params = { filenames: workerData[i] };
worker.send(params);
}
} else {
require('./worker');
}
})();
So our dependencies are pretty simple. First, there’s the cluster module as described above. Second, we’re requiring the os module for the express purpose of figuring out how many CPU cores there are on our machine — which is a fundamental parameter of splitting up our workload. Finally, there’s our input handling function which I’ve outsourced to another file for completeness’ sake.
Now the main method is actually rather simple. In fact, we could break it down into steps:
- If we’re the main process, split up the input sent to us evenly per the number of CPU cores for this machine
- For each worker-to-be’s load, spawn a worker by
cluster.forkand set up an object which we can send to it by the [cluster] module’s inter-process RPC message channel, and send the damn thing to it. - If we’re not in fact the main module, then we must be a worker — just run the code in our worker file and call it a day.
Nothing crazy is going on here, and it allows us to focus on the real lifting, which is figuring out how the worker is going to use the list of filenames we give to it.
Messaging, Async, and Streams, all the elements of a nutritious diet
First, as above let me dump the code for you to refer to. Trust me, looking through it first will let you skip through any explanation you’d consider trivial.
const Bufferer = require('../bufferer');const Parser = require('../parser');const { createReadStream } = require('fs');
process.on('message', async (options) =>; {
const { filenames } = options; const parser = new Parser();
const parseAndLog = async (buf) => console.log(await parser.parse(buf) + ',');
const parsingQueue = filenames.reduce(async (result, filename) =>; {
await result;
return new Promise((resolve, reject) =>; {
const reader = createReadStream(filename); const bufferer = new Bufferer({ onEnd: parseAndLog });
reader .pipe(bufferer) .once('finish', resolve) .once('error', reject) }); }, true);
try { await parsingQueue; process.exit(0); } catch (err) { console.error(err); process.exit(1); }
});
Now there are some dirty hacks in here so be careful if you’re one of the uninitiated (only joking). Let’s look at what happens first:
Step one is to require all the necessary ingredients. Mind you, this is based on what the code itself does. So let me just say we’re going to use a custom-rolled Writable stream I’ve endearingly termed Bufferer, a wrapper for our parsing logic from last time, also intricately named, Parser, and good old reliable createReadStream from the fs module.
Now here’s where the magic happens. You’ll notice that nothing’s actually wrapped in a function. The entire worker code is just waiting for a message to come to the process — the message from its master with the work it has to do for the day. Excuse the medieval language.
So we can see first of all that it’s asynchronous. First, we extract the filenames from the message itself — if this were production code I’d be validating them here. Actually, hell, I’d be validating them in our input processing code earlier. Then we instantiate our parsing object — only one for the whole process — this is so we can parse multiple buffers with one set of methods. A concern of mine is that it’s managing memory internally, and on reflection, this is a good thing to review later.
Then there’s a simple wrapper, parseAndLog around parsing that logs the JSON-ified PDF buffer with a comma appended to it, just to make life easier for concatenating the results of parsing multiple PDFs.

Finally the meat of the matter, the asynchronous queue. Let me explain:
This worker’s received its list of filenames. For each filename (or path, really), we need to open a readable stream through the filesystem so we can get the PDF data. Then, we need to spawn our Bufferer, (our waiter, following along from the restaurant analogy earlier), so we can transport the data to our Parser.
The Bufferer is custom-rolled. All it really does is accept a function to call when it’s received all the data it needs — here we’re just asking it to parse and log that data.
So, now we have all the pieces, we just pipe them together:
- The readable stream — the PDF file, pipes to the Bufferer
- The Bufferer finishes and calls our worker-wide
parseAndLogmethod
This entire process is wrapped in a Promise, which itself is returned to the reduce function it sits inside. When it resolves, the reduce operation continues.
This asynchronous queue is actually a really useful pattern, so I’ll cover it in more detail in my next post, which will probably be more bite-sized than the last few.
Anyway, the rest of the code just ends the process based on error-handling. Again, if this were production code, you can bet there’d be more robust logging and error handling here, but as a proof of concept, this seems alright.
So it works, but is it useful?
So there you have it. It was a bit of a journey, and it certainly works, but like any code, it’s important to review what its strengths and weaknesses are. Off the top of my head:
- Streams have to be piled up in buffers. This, unfortunately, defeats the purpose of using streams, and memory efficiency suffer accordingly. This is a necessary duct-tape-fit to work with the pdfreader module. I’d love to see if there’s a way to stream PDF data and parse it on a finer-grained level. Especially if modular, functional parsing logic can still be applied to it.
- In this baby stage, the parsing logic is also annoyingly brittle. Just think, what if I have a document that’s longer than a page? A bunch of assumptions fly out the window and make the need for streaming PDF data even stronger.
- Finally, it would be great to see how we could build out this functionality with logging and API endpoints to provide to the public — for a price, or pro bono, depending on the contexts in which it’s used.
If you’ve got any specific criticisms or concerns I’d love to hear them too, since spotting weaknesses in the code are the first step to fixing them. And, if you’re aware of any better method to streaming and parsing PDFs concurrently, let me know so I can leave it here for anyone reading through this post for an answer. Either way — or for any other purpose — send me an email or get in touch on Reddit.