By Yan Cui
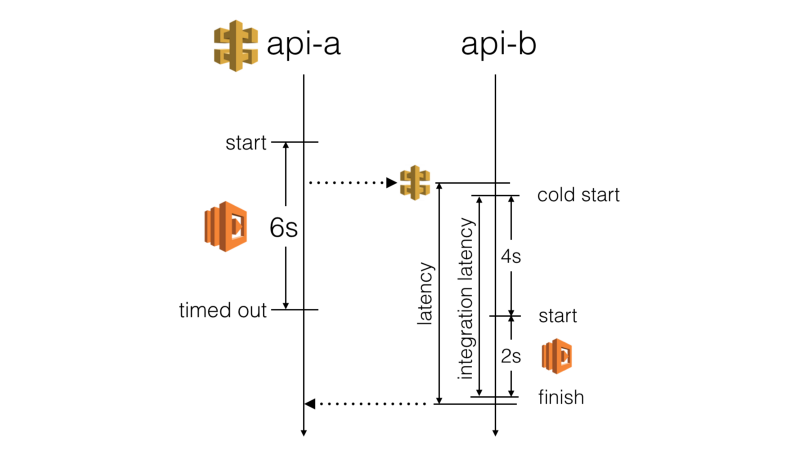
With API Gateway and Lambda, you’re forced to use short timeouts on the server-side:
- API Gateway has a 29s max timeout on all integration points
- The Serverless framework uses a default of 6s for AWS Lambda functions
However, you have limited influence over a Lambda function’s cold start time. And you have no control over how much overhead API Gateway adds. So the actual latency you’d experience from a calling function is far less predictable than you might think.
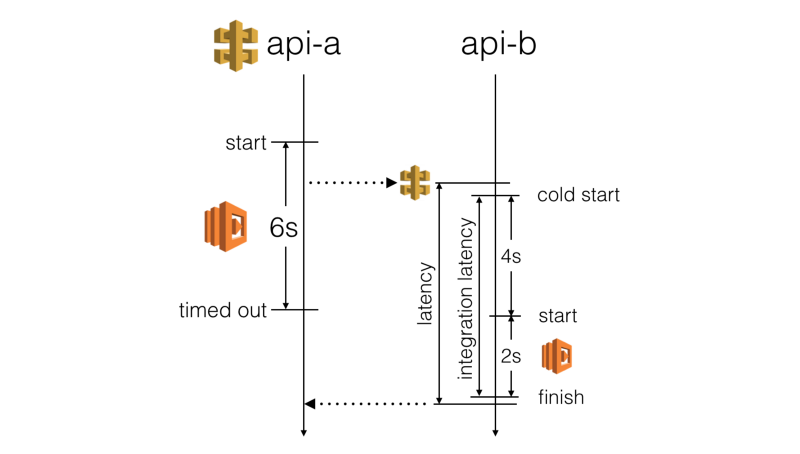

We don’t want a slow HTTP response to cause the calling function to timeout. This has a negative impact on the user experience. Instead, we should stop waiting for a response before the calling function times out.
“The goal of the timeout strategy is to give HTTP requests the best chance to succeed, provided that doing so does not cause the calling function itself to err.”
- Me
Most of the time, I see folks use fixed timeout values — but it’s often tricky to decide:
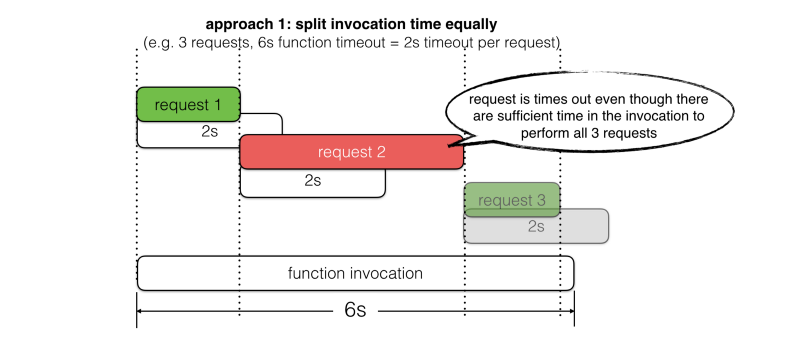
- Too short, and you won’t give the request the best chance to succeed. For example, there’s 5s left in the invocation, but the timeout is set to 3s.
- Too long, and you run the risk of letting the request timeout the calling function. For example, there’s 5s left in the invocation but the timeout is set to 6s.
Things are further complicated by the fact that we often perform more than one HTTP request during a function invocation. For example,
- read from DynamoDB
- perform business logic on the data
- save the update to DynamoDB
- publish an event to Kinesis
Let’s look at two common approaches for picking timeout values, and where they fall short.
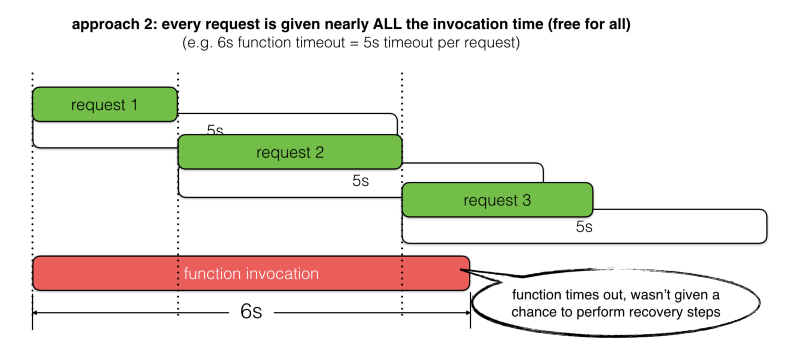
Instead of following these approaches, I propose we should set the request timeout based on the amount of invocation time left. We should also reserve some time to perform recovery steps in the event of failures.
You can find out how much time is left in the current invocation through the context object.
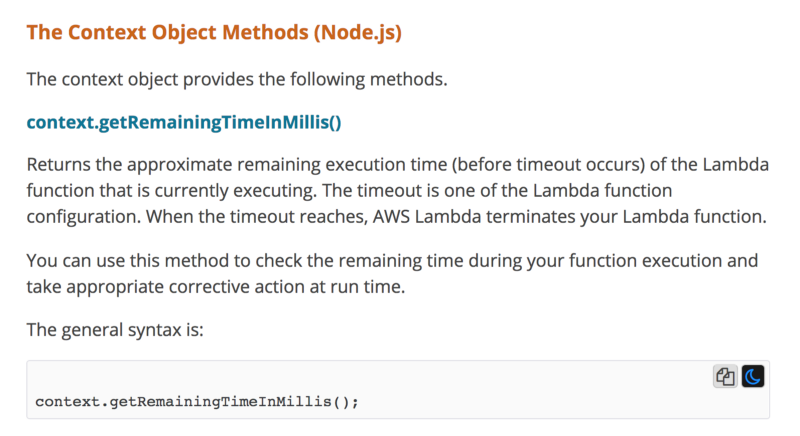
For example, if a function’s timeout is 6s, and we’re 1s into the invocation. If we reserve 500ms for recovery, then that leaves us with 4.5s to wait for a HTTP response.
With this approach, we get the best of both worlds:
- Allow requests the best chance to succeed based on the actual amount of invocation time we have left
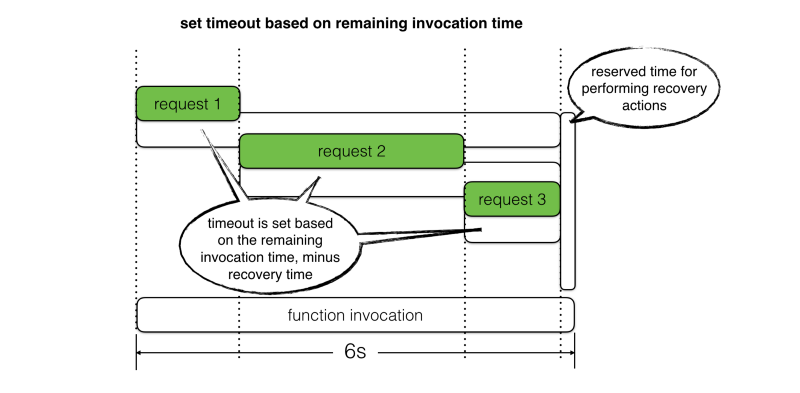
- Prevent slow responses from timing out the function, which gives us a window of opportunity to perform recovery actions.
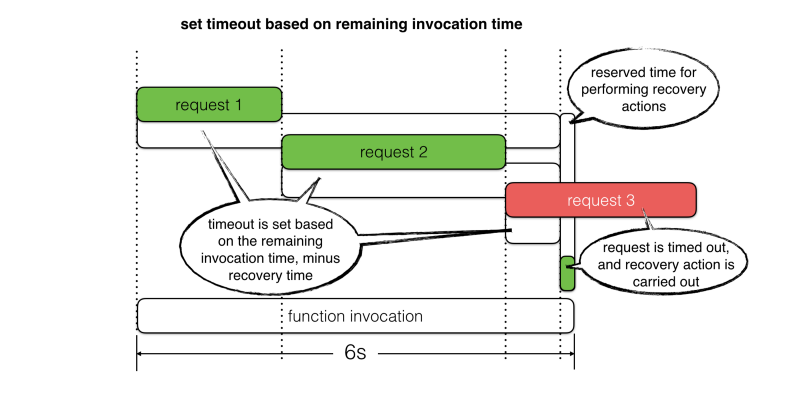
But what are you going to do after you time out these requests? Aren’t you still going to have to respond with a HTTP error, since you couldn’t finish whatever operations you needed to perform?
At the minimum, the recovery actions should include:
- Log the timeout incident with as much context as possible. For example, request target, timeout value, correlation IDs, and the request object.
- Track custom metrics for
serviceX.timedoutso it can be monitored and the team can be alerted if the situation escalates - Return an application error code and the original request ID in the response body. The client app can then display a user-friendly message like
_“Oops, looks like this feature is currently unavailable, please try again later. If this is urgent, please contact us at xxx@domain.com and quote the request ID f19a7dca. Thank you for your cooperation :-)”_
{ "errorCode": 10021, "requestId": "f19a7dca", "message": "service X timed out" }
In some cases, you can also recover even more gracefully using fallbacks.
Netflix’s Hystrix library supports several flavors of fallbacks via the Command pattern it employs heavily. I recommend reading its wiki page, as there is tons of useful information and ideas there.

Every Hystrix command lets you specify a fallback action.

You can also chain the fallback together by chaining commands via their respective getFallback methods.
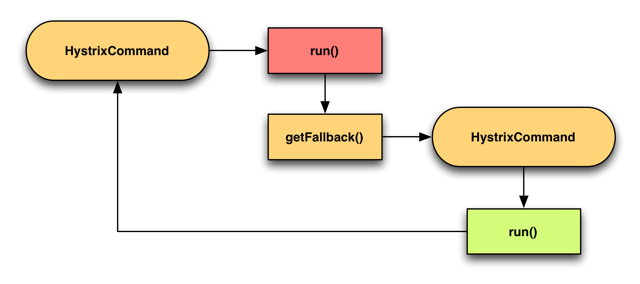
For example,
- execute a DynamoDB read inside
CommandA - In the
getFallbackmethod, executeCommandBwhich would return a previously cached response if available - If there is no cached response, then
CommandBwould fail and trigger its owngetFallbackmethod - Execute
CommandC, which returns a stubbed response
You should check out Hystrix if you haven’t already. Most of the patterns that are baked into Hystrix can be easily adopted in our serverless applications to help make them more resilient to failures.