
By Praveen Dubey
A while back I had to crawl a site for links, and further use those page links to crawl data using selenium or puppeteer. Setup for the content on the site was bit uncanny so I couldn’t start directly with selenium and node. Also, unfortunately, data was huge on the site. I had to quickly come up with an approach to first crawl all the links and pass those for details crawling of each page.
That’s where I learned this cool stuff with the browser Console API. You can use this on any website without much setup, as it’s just JavaScript.
Let’s jump into the technical details.
High Level Overview
For crawling all the links on a page, I wrote a small piece of JS in the console. This JavaScript crawls all the links (takes 1–2 hours, as it does pagination also) and dumps a json file with all the crawled data. The thing to keep in mind is that you need to make sure the website works similarly to a single page application. Otherwise, it does not reload the page if you want to crawl more than one page. If it does not, your console code will be gone.
Medium does not refresh the page for some scenarios. For now, let’s crawl a story and save the scraped data in a file from the console automatically after scrapping.
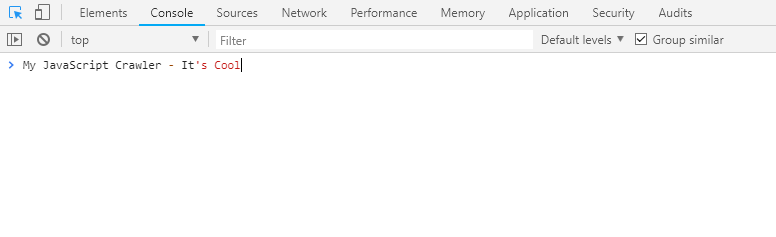
But before we do that here’s a quick demo of the final execution.
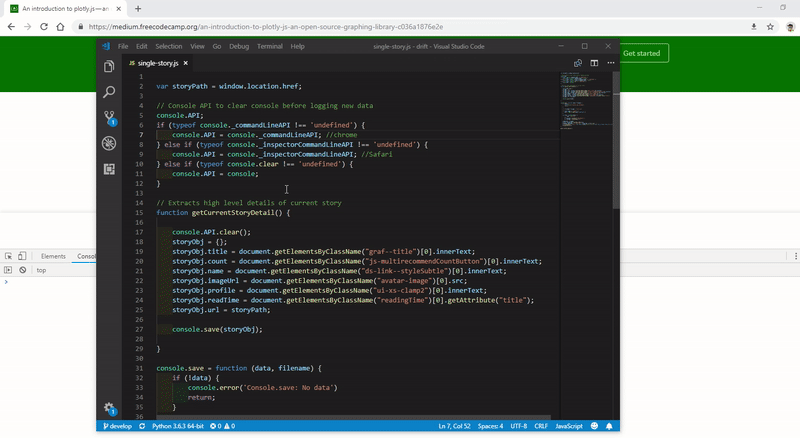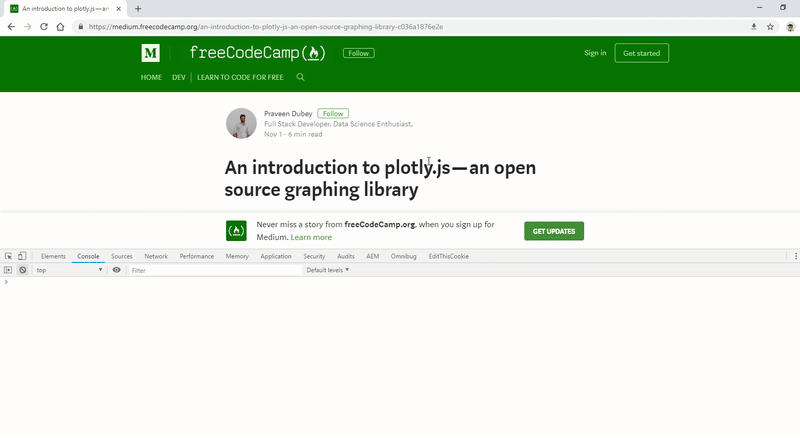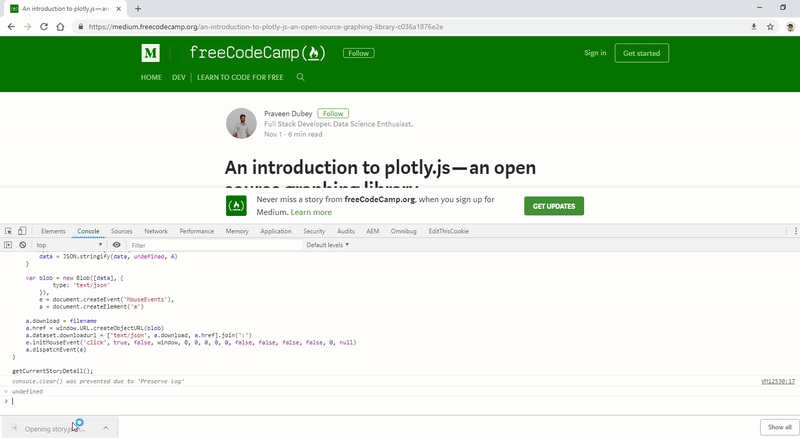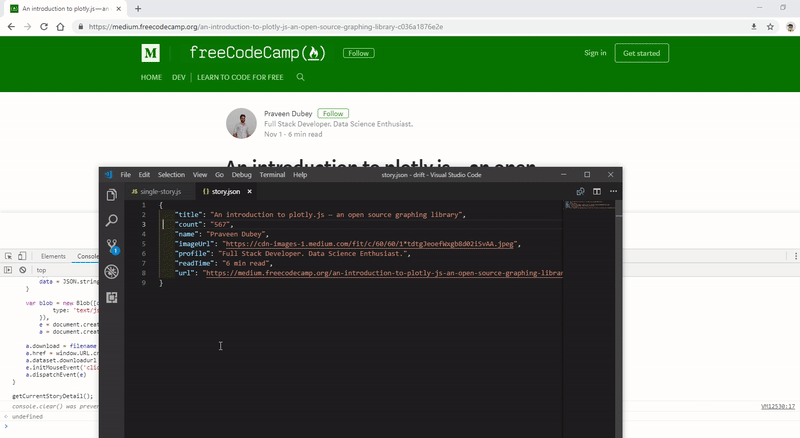 Demo
Demo
1. Get the console object instance from the browser
// Console API to clear console before logging new data
console.API;
if (typeof console._commandLineAPI !== 'undefined') { console.API = console._commandLineAPI; //chrome
} else if (typeof console._inspectorCommandLineAPI !== 'undefined'){ console.API = console._inspectorCommandLineAPI; //Safari
} else if (typeof console.clear !== 'undefined') { console.API = console;
}
The code is simply trying to get the console object instance based on the user’s current browser. You can ignore and directly assign the instance to your browser.
Example, if you using Chrome, the below code should be sufficient.
if (typeof console._commandLineAPI !== 'undefined') { console.API = console._commandLineAPI; //chrome
}
2. Defining the Junior helper function
I’ll assume that you have opened a Medium story as of now in your browser. Lines 6 to 12 define the DOM element attributes which can be used to extract story title, clap count, user name, profile image URL, profile description and read time of the story, respectively.
These are the basic things which I want to show for this story. You can add a few more elements like extracting links from the story, all images, or embed links.
3. Defining our Senior helper function — the beast
As we are crawling the page for different elements, we will save them in a collection. This collection will be passed to one of the main functions.
We have defined a function name, console.save. The task for this function is to dump a csv / json file with the data passed.
It creates a Blob Object with our data. A Blob object represents a file-like object of immutable, raw data. Blobs represent data that isn't necessarily in a JavaScript-native format.
Create blob is attached to a link tag <;a> on which a click event is triggered.
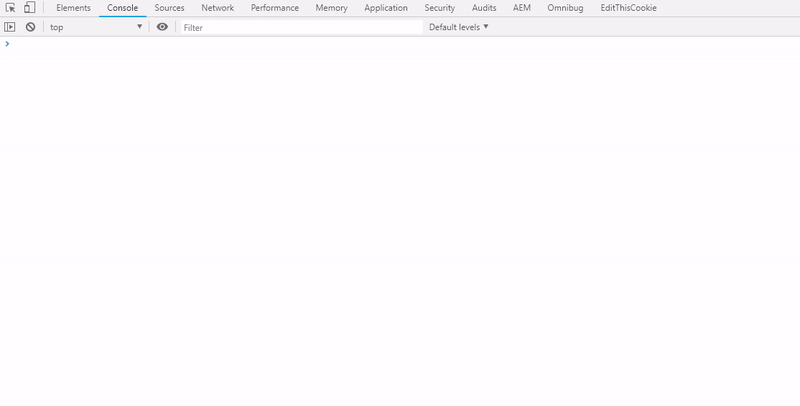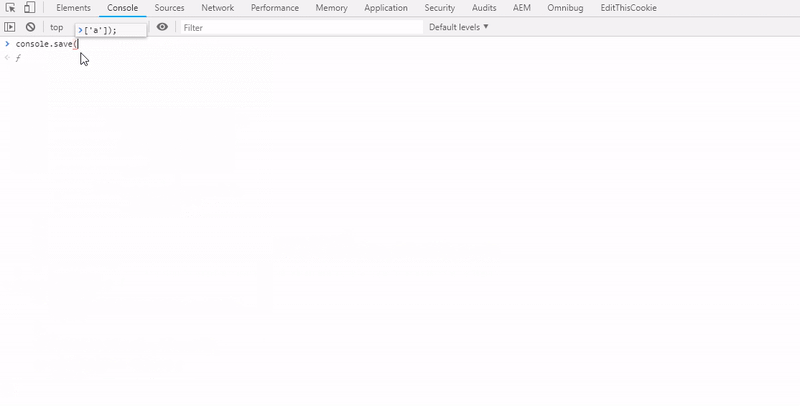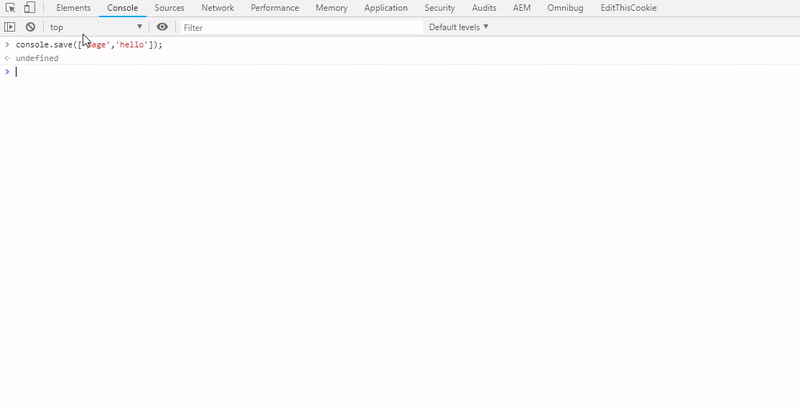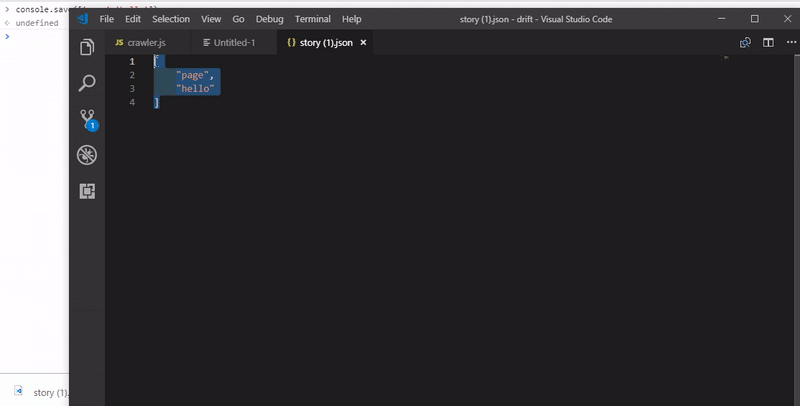
Here is the quick demo of console.save with a small array passed as data.
Putting together all the pieces of the code, this is what we have:
- Console API Instance
- Helper function to extract elements
- Console Save function to create a file
Let’s execute our console.save() in the browser to save the data in a file. For this, you can go to a story on Medium and execute this code in the browser console.
I have shown the demo with extracting data from a single page, but the same code can be tweaked to crawl multiple stories from a publisher’s home page. Take an example of freeCodeCamp: you can navigate from one story to another and come back (using the browser’s back button) to the publisher home page without the page being refreshed.
Below is the bare minimum code you need to extract multiple stories from a publisher’s home page.
Let’s see the code in action for getting the profile description from multiple stories.
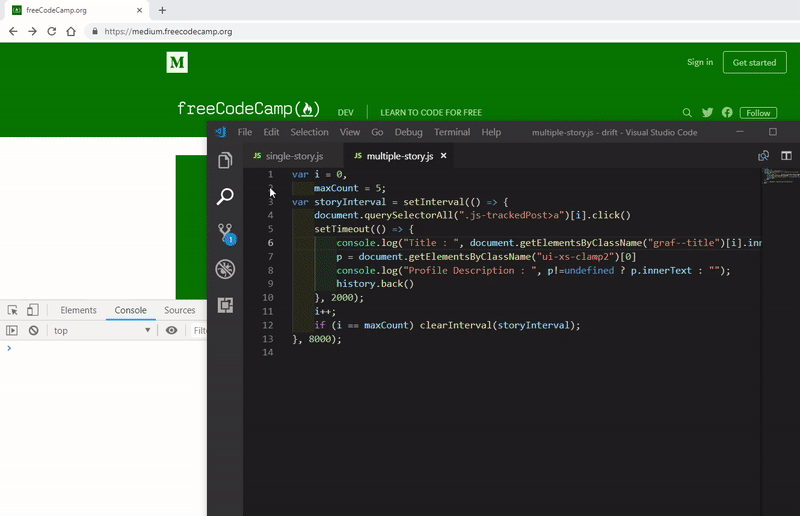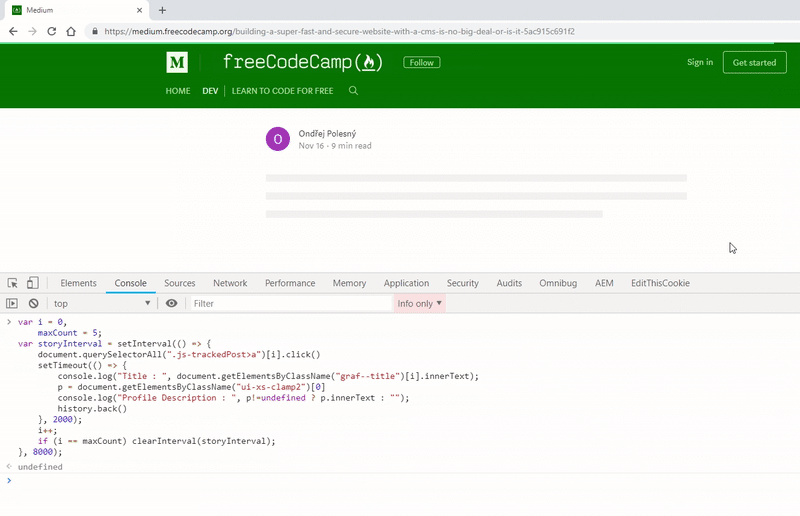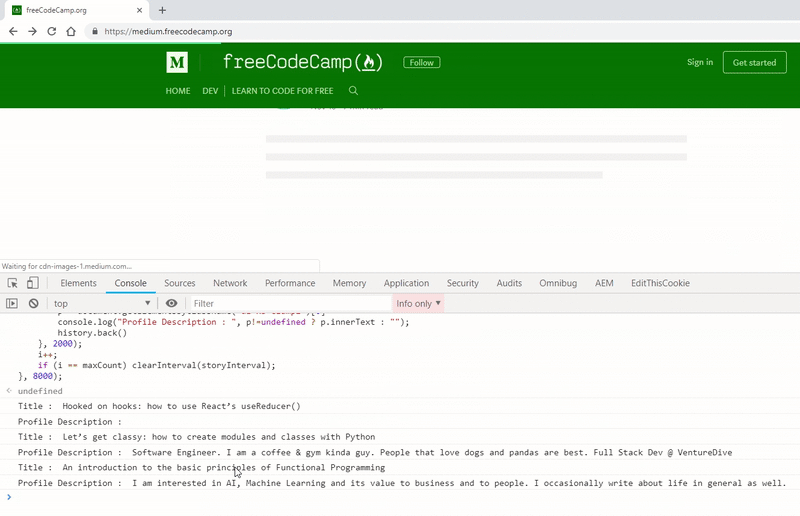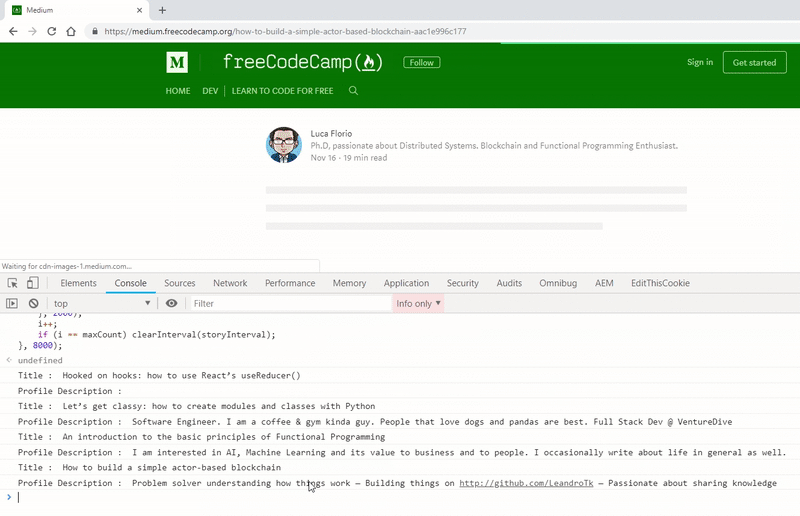
For any such type of application, once you have scrapped the data, you can pass it to our console.save function and store it in a file.
The console save function can be quickly attached to your console code and can help you to dump the data in the file. I am not saying you have to use the console for scraping data, but sometimes this will be a way quicker approach since we all are very familiar working with the DOM using CSS selectors.
You can download the code from Github
Thank you for reading this article! Hope it gave you cool idea to scrape some data quickly without much setup. Hit the clap button if it enjoyed it! If you have any questions, send me an email (praveend806 [at] gmail [dot] com).
Resources to learn more about the Console:
Using the Console | Tools for Web Developers | Google Developers
_Learn how to navigate the Chrome DevTools JavaScript Console._developers.google.comBrowser Console
_The Browser Console is like the Web Console, but applied to the whole browser rather than a single content tab._developer.mozilla.orgBlob
_A Blob object represents a file-like object of immutable, raw data. Blobs represent data that isn't necessarily in a…_developer.mozilla.org