

Different programming languages have their own ways of working with relational databases and SQL. Ruby on Rails has its Active Record, Python has SQLAlchemy, Typescript has Drizzle, and so on.
Go is a language with quite a diverse standard library, which includes the well-known database/sql package. And it has its own libraries and solutions for working with SQL, that suit different needs, preferences, and teams.
In this article, we'll explore and compare the most popularly used Go packages that let you work with SQL. We’ll look at some hands-on examples, as well as the pros and cons. We’ll also briefly touch on the topic of database migrations and how to manage them in Go.
You'll get the most out of this article if you already have some experience with Go, SQL, and relational databases (doesn't matter which one).
Table of Contents
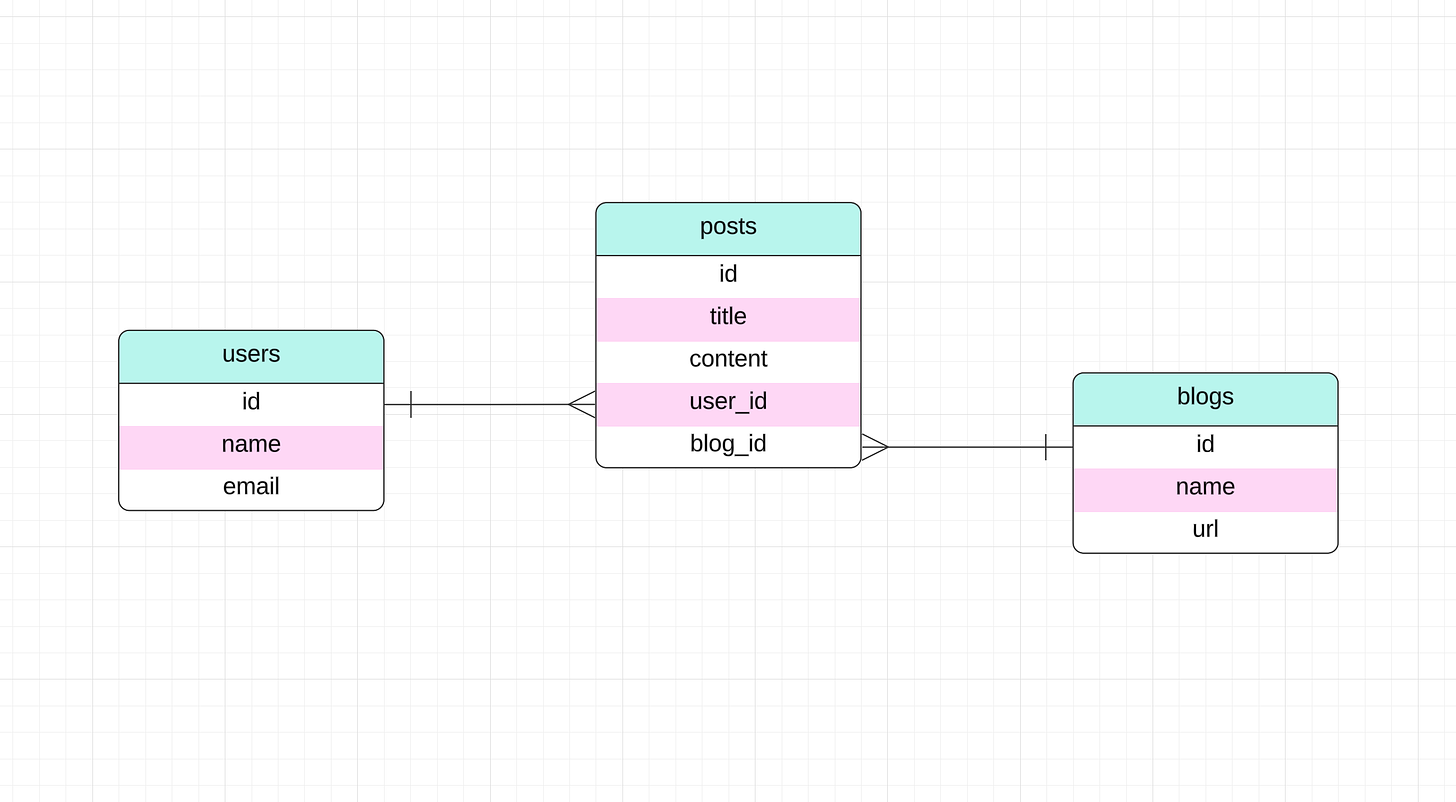
Demo Schema
For this article, we'll use a simple schema with three tables: users, posts, and blogs. For simplicity, we'll be using SQLite as our database engine. But if you want to choose another database engine, that shouldn’t be a problem, as all the libraries we'll be exploring support multiple SQL dialects.
Here is our database schema in SQL:
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE blogs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
url TEXT NOT NULL UNIQUE
);
CREATE TABLE posts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
content TEXT NOT NULL,
user_id INTEGER NOT NULL,
blog_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) ON DELETE CASCADE,
FOREIGN KEY (blog_id) REFERENCES blogs (id) ON DELETE CASCADE
);
And here is its Entity-Relationship Diagram (ERD):
Raw SQL and database/sql
Let’s imagine your application needs to perform the following action:
Find the users who have posted at least two articles, along with the total number of posts they've made.
In pure SQL, you could translate that into the following query:
SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= 2;
A brief explanation of this query: we JOIN the users and posts tables, then GROUP by user_id. The HAVING clause filters the results to only include users who have posted at least 2 posts, and COUNT aggregates the amount of posts.
As mentioned above, Go provides a built-in package called database/sql with the necessary tools for working with SQL databases. It was developed with simplicity in mind, but supports all the necessary functionality such as transactions, parameterized queries, connection pool management, and so on.
As long as you’re comfortable writing your own queries and handling errors and results, it’s a great option. And some would say that it’s the best option, as there is no hidden logic and you can always copy the query and analyze it with EXPLAIN.
Here is how you can get the results of the query above in Go code using database/sql (some parts like connection are omitted):
type userStats struct {
UserName sql.NullString
PostCount sql.NullInt64
}
func getUsersStats(conn *sql.DB, minPosts int) ([]userStats, error) {
query := `SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;`
rows, err := conn.Query(query, minPosts)
if err != nil {
return nil, err
}
defer rows.Close()
users := []userStats{}
for rows.Next() {
var user userStats
if err := rows.Scan(&user.UserName, &user.PostCount); err != nil {
return nil, err
}
users = append(users, user)
}
if err := rows.Err(); err != nil {
return nil, err
}
return users, nil
}
In this code we:
Use the raw SQL query with an unnamed parameter, and pass the value of this parameter in
conn.Query()Iterate over returned rows and manually scan each row into a struct
userStatsdefined above. Note that the struct usessql.Null*types to handle nullable values properly.We need to manually check for possible errors and close the rows to release the resources.
Pros:
No additional abstraction/complexity added. Easy to debug raw SQL queries.
Performance. The database/sql package is quite performant.
Provides a good enough abstraction from different database backends.
Cons:
The code becomes a bit verbose as there is a need to scan each row, define proper types, and handle errors.
No compile-time type safety.
You can find the full source for this article in this Github Repository.
Raw SQL and sqlx
Now let’s have a look at some external packages which are popular in the Go community.
If you’re already familiar with database/sql and like its simplicity, you may enjoy working with sqlx. It’s built on top of the standard library and just extends its features.
It’s very easy to integrate existing codebases using database/sql with sqlx, because it leaves the underlying interfaces such as sql.DB, sql.Tx, and so on untouched.
The core features of sqlx are:
Named parameters.
Easier row scanning into structs with embedded struct support.
Better separation between single and multiple rows by using the
Get()andSelect()methods.Ability to bind a slice of values as a single parameter to an IN query.
Here is how you can get the results of the query above using sqlx:
type userStats struct {
UserName string `db:"name"`
PostCount string `db:"post_count"`
}
func getUsersStats(conn *sqlx.DB, minPosts int) ([]userStats, error) {
users := []userStats{}
query := `SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;`
if err := conn.Select(&users, query, minPosts); err != nil {
return nil, err
}
return users, nil
}
In this code, we use the Select() method which handles the scanning of the rows. It also closes the rows automatically so we don’t have to deal with that.
The code is much shorter than the database/sql version, but it can hide some implementation details from us. For example, be aware that Select loads the whole set into memory at once.
Pros:
Not that different from database/sql. Still easy to debug raw SQL queries.
A bunch of great features to reduce code verbosity.
Cons:
- Same as database/sql
ORMs
Object-relational mapping (ORM) is a technique (some call it a design pattern) of accessing a relational database by working with objects without having to craft complex SQL statements. It’s very popular in object-oriented languages – Ruby on Rails has its Active Record, Python has SQLAlchemy, Typescript has Drizzle, and so on.
And Go has GORM. In a nutshell, it lets you write queries as Go code by calling various methods on objects, which are then translated into SQL queries. But not only that, it has other features like database migrations, database resolvers, and more.
You may need to spend a bit of time initially setting up your GORM models, but later it can reduce a lot of boilerplate code.
Our simple schema and query example may not be the best to visualize the strengths and weaknesses of GORM, but should be enough to demonstrate how we can run a similar query and scan the results:
type User struct {
gorm.Model
ID int
Name string
Posts []Post
}
type Post struct {
gorm.Model
ID int
UserID int
}
type userStats struct {
Name string
Count int `gorm:"column:post_count"`
}
func getUsersStats(conn *gorm.DB, minPosts int) ([]userStats, error) {
var users []userStats
err := conn.Model(&User{}).
Select("name", "COUNT(p.id) AS post_count").
Joins("JOIN posts AS p ON users.id = p.user_id").
Group("users.id").
Having("post_count >= ?", minPosts).
Find(&users).Error
return users, err
}
The SQL query generated by gorm will be roughly the same as the one we wrote manually in the database/sql variant.
To summarize the code above:
We declared our User and Post models and extended it with the default
gorm.Modelstruct. Later we can use these two models to build any queries we want by using gorm methods.We also defined our small result type
userStatsWe used methods such as
Select(),Joins(),Group(), andHaving()to produce the query we want.
With such an easy example, it’s hard to see the potential issues – everything looks just right. But when your project becomes more complex, you will most definitely encounter some issues with that. Just look at the StackOverflow questions marked with go-gorm.
It's good to be careful about using ORMs in performance-critical systems or where you need direct control over database interactions. This is because gorm uses a lot of reflection, and can add overhead and sometimes obscure what's happening at the database level. Any project where the functionality is wrapped in another huge layer runs the risk of increasing the overall complexity.
Pros:
Abstraction from different database backends.
Big feature set: migrations, hooks, database resolvers, and more.
Saves quite a bit of tedious coding.
Cons:
Another layer of complexity and overhead. Hard to debug raw SQL queries.
Performance drawbacks. May not be as efficient for some critical applications.
Initial setup can require some time to configure all the models.
Generated Go Code from SQL using sqlc
This nicely brings us to another unique approach of generating Go code from SQL queries using sqlc. With sqlc, you write your schema and SQL queries, then use a CLI tool to generate Go code from it and then use the generated code to interact with databases.
This ensures that your queries are syntactically correct and type-safe. It’s ideal for those who prefer writing SQL but are looking for an efficient way to integrate it into a Go application.
sqlc needs to know your database schema and queries in order to generate code, so it requires some initial setup. We can add our schema and query above to the files schema.sql and query.sql. Then using the following config, we can generate the Go code:
version: "2"
sql:
- engine: "sqlite"
queries: "query.sql"
schema: "schema.sql"
gen:
go:
package: "main"
out: "."
We also need to name our query in query.sql and mark the parameters:
-- name: GetUsersStats :many
SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;
After we run sqlc generate, we can use the following generated types and functions which make our code type-safe and quite short.
func getUsersStats(conn *sql.DB, minPosts int) ([]GetUsersStatsRow, error) {
queries := New(conn)
ctx := context.Background()
return queries.GetUsersStats(ctx, minPosts)
}
What makes sqlc special is that it understands your database schema, and uses that to validate the SQL you write. So your SQL queries are being validated against the actual database table, and sqlc will give you a compile-time error if something is wrong.
Pros:
Type safety with generated Go code.
Still easy to debug SQL code.
Saves quite a bit of tedious coding.
Performance.
Cons:
Initial configuration setup for database schema and queries.
Not perfect static analysis. Sometimes you need to explicitly set the parameter type, and so on.
If you’re good with SQL statements and prefer not to use much code to express your database interactions, this is your package.
Database Migrations
Since we’re on the topic of SQL databases here, let’s briefly review how database migrations work in Go. The schema of the database almost always evolves over time and no one wants to do these changes manually. So there are tools developed to help with that.
The main goal of database migration tools is to ensure that all environments have the same schema and developers can easily apply the changes or roll them back.
I mentioned above that GORM can do the migrations as well if your project uses it as its ORM. If you use database/sql, sqlx or sqlc you’ll have to use separate projects to manage them.
The most popular projects are:
golang-migrate: one of the most famous tools for handling database migrations. It supports many database drivers and migration sources, and takes a simple and direct approach for handling database migrations.
goose: another solid option when choosing a migration tool. It also has support for the main database drivers. Two of its main features are support for migrations written in Go and more control of the migration application process.
You can then integrate these tools directly into your application or in CI/CD. But running them properly in CI/CD requires some setup (for example in case of deploying to Kubernetes), and I’ll dive deeper into that in my upcoming articles.
Conclusion
There are many well-written, tested, and supported database packages for Go that can help you with faster development and writing cleaner code. There is also the very powerful database/sql included in the standard library that can do most of your daily work.
But whether you should use it or not depends on your needs as a developer, your preferences, and your project. In this article, I tried to highlight the strengths and weaknesses of each option.
You can find the full source for this article on this Github Repository.
I’ll end this article with this famous meme:
