
By Akash Sant
I wrote this post not to describe how to use certain technologies, but rather to provide insights into the lessons we learned while mitigating a Denial of Service (DoS) attack on a web based service we built.
We’ll start with a bit of a background for context.
For the past year, my friends and I believed that inter-city transportation needed a serious upgrade.

We started noticing that something didn’t seem right here. We are all busy students, and waiting in such long lines for public transportation is just not worth our time. Inter-city transportation lacked the elements of reliability, efficiency, and simplicity. We decided that going forward, this needed to change.
Introducing POOL - #MadeWithLove
For the past few months, a team of four Software Engineers and I have been working on a simple, fast, and easy to use car pooling application for Android and iOS.
I recall the day when we first met to brainstorm the idea for the project. Our notes were filled with the challenges we would be facing while executing an idea of such scale. Challenges that were related to the reliability of users, trust between drivers and riders, and trip scheduling issues.
The current number of members on Waterloo carpooling and ride sharing groups on Facebook is approximately 40,000. We knew we would have to build fast and scalable services. We started our first prototype as an Android application, which lead to a port to React Native to make it cross-platform.
On March 7th, 2018, we announced an official release of version 1.0.
Within two hours, 40+ users had signed up and 14+ drivers had offered their services. Everything was going as planned. However, it wouldn’t really be a party without a party crasher, would it?
The Denial of Service Attack
Denial of Service (DoS) attacks aim to flood the victim servers with fake requests, thus preventing them from serving legitimate users.
Three hours after we launched, we received a support email from a user with the message that, “The nearby trips just keeps on displaying the loading symbol”. I felt slightly excited to know that someone cared enough to send us a support email, but my excitement was short lived after I decided to have a look at the server logs. I couldn’t believe what I was seeing.
The servers were getting overwhelmed by a flood of ~600 requests per second. We were under attack, and instantly knew this was not legitimate traffic.
My first instinct was to put the servers in maintenance mode and hope that the attacker would go away. But as soon as we restored the server back from maintenance mode, the attacks resumed. At this point, we realized that our app was getting more traction than we had assumed and I was completely confused as to where to start with implementing a fix.
Project S.O.S - Securing our Services
All the core team members were alerted, and we assembled to put our brains together to mitigate the attack. We used a number of different methods, which I’ll describe below.
Rate-limiting
When the attacks continued, I knew we needed to slow them down by implementing some kind of rate-liming on our APIs.
Rate-limiting is essentially limiting the number of requests (per minute) to a given IP from a specific source (which in our case was the Internet). After applying the rate limit, only a specific number of requests would be accepted by the server.
The rate-limiting algorithm must be fast so that it doesn’t just queue all of the incoming requests, but rather rejects all the attacker’s requests as quickly as possible.
This was a start, but it was definitely not enough to stop the attacker for good.
Endpoint specific Rate-limiting
Next, due to rate limiting, flooding the servers and causing request queuing was not feasible for the attacker. So the attacker slightly changed their strategy. Instead, they now targeted POST endpoints on the server in order to post fake data to the server. This meant that they could create N trips every minute (based on the previous rate-limiting step).
In a couple of hours, the server had 100s of dummy trips created by the attacker. This called for rate-limiting the POST endpoints with a stricter limit. Rate-limiting our POST endpoints to about two requests per hour did the trick. Even if the attacker now created dummy trips, we would have enough time to catch them and clean-up our datastore.
Better luck next time!
During the next few hours of monitoring, the attacker tried again. However no damage was done and the application was successfully live throughout the attack. So the rate-limiting strategies had done the trick! Now it was time to focus on finding who it was.
Monitoring and tracking our server logs allowed us to retrieve the IP address for the origin of the attacks.

The request path and the attacker’s forward IP address have been redacted for privacy reasons. The logs were recorded during maintenance mode. If you inspect the logs more closely, you’ll notice the id field in the request. This represents the fake account that the user had created on our services to be able to gain access to the app.
Pool uses Facebook authentication, meaning the attacker had created a fake Facebook account to sign-up with Pool. Using the local id (recorded in the logs) we were able to find the Facebook id for the user and issue an account ban.
Our team then used https://www.whois.com/whois/ to perform a domain lookup on this IP address.
With more digging around, we noticed that the requests were originating from an EC2 instance on Amazon Web Services. At this point we realized that we could have just reported the IP address to AWS, but what’s the fun in taking the easy way out?
It doesn’t end just yet…
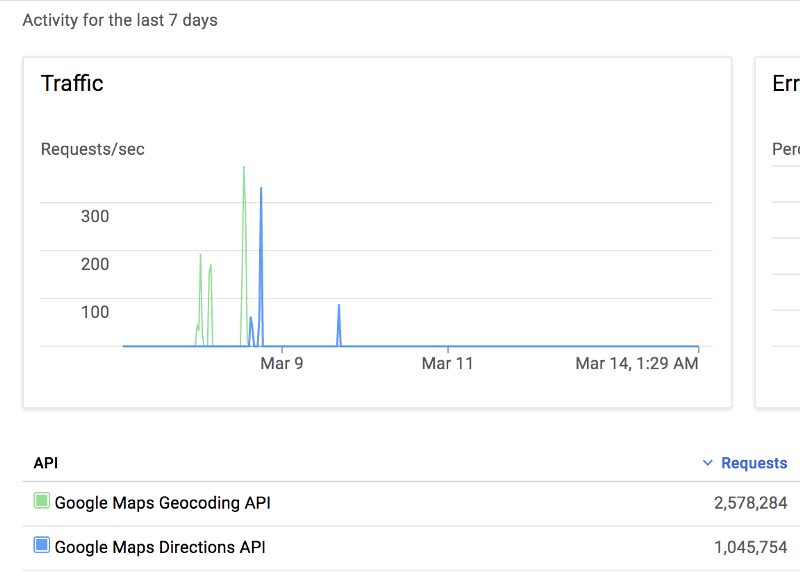
Following these measures, before the account ban could take affect, the attacker decided to use the Google Cloud Platform API keys (formerly exposed on client side) to use all the Google API quota. An estimated 4 million requests had hit the servers in under an hour.
But this just required a simple fix.
- We first prevented the attacker’s attempt to steal the Google API quota by adding app-level restrictions to the API keys. Meaning, only the requests made from the application would get through.
- We added a more permanent fix by moving the Google API calls on the server side, thus hiding the API keys on the server. It is usually a secure practice to hide the key behind an environment variable on the server.
If you intend to defeat a hacker, you must think like a hacker!
If I was the attacker using the EC2 instance to flood the servers with requests, I would want to check for an HTTP request error code to know when the services went down to save up on resources. Rate limiting submits an error code of 429 - Too Many Requests, whereas a successful connection request would return a 200 - OK.
I was able to configure this on the server side to return 200 - OK instead of the rate limiting “too many requests” error code. This prevented the attacker’s scripts from knowing when they were being rate-limited and constantly used up their resources.
While monitoring the server logs, we noticed that the requests from the attacker were coming in and getting rejected by the server through rate-limiting.
Conclusion
After fighting the attacks for 30 hours, our services were finally impenetrable to a DOS attack from this attacker. They made many attempts before finally giving up. At each step during the attack, a small and simple measure was taken to mitigate the DOS. Together these simple tactics proved to be highly effective.
At the end of the day, simplicity and perseverance goes a long way and failures are just the stepping stones to success.