

A JavaScript engine is simply a computer program that executes JavaScript code. It's responsible for translating human-readable JavaScript code into machine-readable instructions that the computer's hardware can execute.
When you write JavaScript code and run it in a browser, the code doesn't directly interact with your computer's hardware. Instead, it interacts with the JavaScript engine, which acts as an intermediary between your code and the underlying machine.
Every browser has its own JS engine, but the most well known one is Google's v8 Engine. This v8 Engine powers Google Chrome and also Node.js (used to build server side applications).
In this article, you'll learn more about what a JS engine is and how it works under the hood.
Here's what we'll cover in this quick guide:
How the JavaScript Engine Works
Any JS engine always contains a call stack and a heap.
The call stack is where our code gets executed with the help of the execution context. And the heap is an unstructured memory pool that stores all the objects in the memory that our application needs.
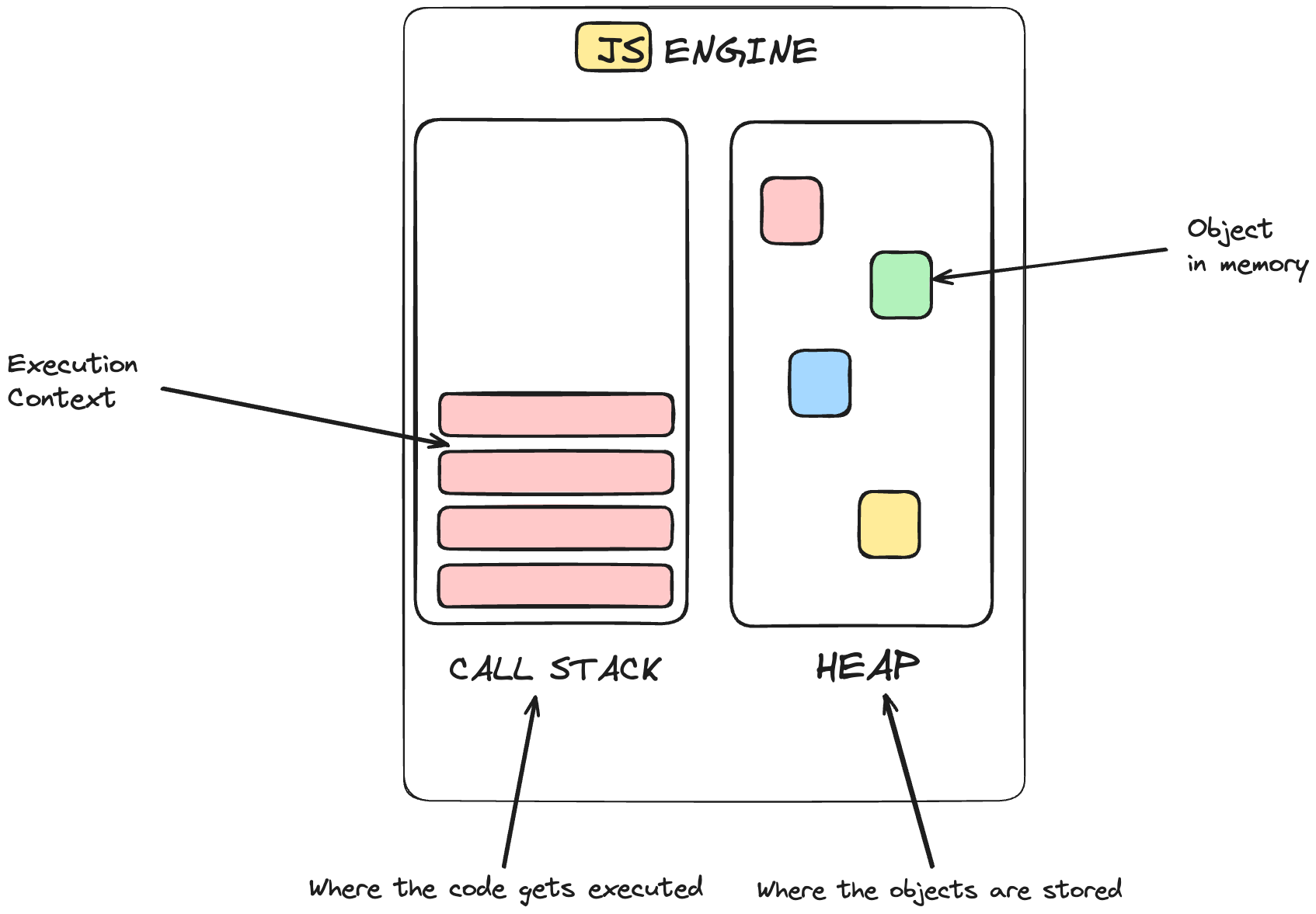 JavaScript Engine consists of a call stack and a heap
JavaScript Engine consists of a call stack and a heap
You should now understand where the code gets executed – but now the question is how the code gets compiled to machine code so that it can execute afterwards. But before this, let's understand in brief about compilation and interpretation.
Compilation vs Interpretation
In compilation, the entire code is converted into machine code at once and written in a binary file that can be executed by a computer.
 Source code gets compiled to machine code and then gets executed while running the program
Source code gets compiled to machine code and then gets executed while running the program
In interpretation, the interpreter runs through the source code and executes it line by line. The code still needs to get converted into machine code, but this time it is happening line by line while executing the program.
 Source code gets converted into machine code and gets executed at the same time line by line
Source code gets converted into machine code and gets executed at the same time line by line
JS used to be a purely interpreted language. But the modern JS engine now use a mix of compilation and interpretation which is known as "just-in-time" compilation
In JIT compilation, the entire code is converted into machine code at once and then executed immediately.
 Source code gets compiled to machine code and gets executed immediately
Source code gets compiled to machine code and gets executed immediately
You may wonder what's the difference between the compilation and JIT. Well, there's one major difference: after compilation, the machine code is stored in a portable file. It can be executed at any time – there's no need to rush immediately after the compilation process.
But in the case of JIT, the machine code needs to execute as soon as the compilation ends.
I'm not going to go in-depth into these concepts, but now you hopefully understand the basics of the compilation, interpretation and JIT.
JIT and JavaScript
Let's now understand how JIT works specifically in JavaScript.
So, whenever a piece of JavaScript code enters the engine, the first step is to parse the code.
During this parsing process, the code is parsed into a data structure called the AST (Abstract Syntax Tree). This works by first splitting up each line of code into pieces that are meaningful to the language (like the const or function keywords), and then saving all these pieces into the tree in a structured way.
This step also checks if there are any syntax errors. The resulting tree will later be used to generate the machine code.
For example, let's take a look at an AST for this line of code const greet = "Hello":
{
"type": "Program",
"start": 0,
"end": 201,
"body": [
{
"type": "VariableDeclaration",
"start": 179,
"end": 200,
"declarations": [
{
"type": "VariableDeclarator",
"start": 185,
"end": 200,
"id": {
"type": "Identifier",
"start": 185,
"end": 190,
"name": "greet"
},
"init": {
"type": "Literal",
"start": 193,
"end": 200,
"value": "Hello",
"raw": "\"Hello\""
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
You don't need to know or understand how ASTs work, this is just for curiosity.
You can play around and generate your own AST here.
The next step is compilation. Here the engine takes the AST and compiles it to machine code.
Then, this machine code gets executed immediately because its using JIT – remember that this execution happens in the call stack.
But this is not the end. The modern JS engine generates inefficient machine code just to execute the program as fast as possible. Then the engine takes the already pre-compiled code to optimise and recompile the code during the already running program execution. All this optimisation happens in the background
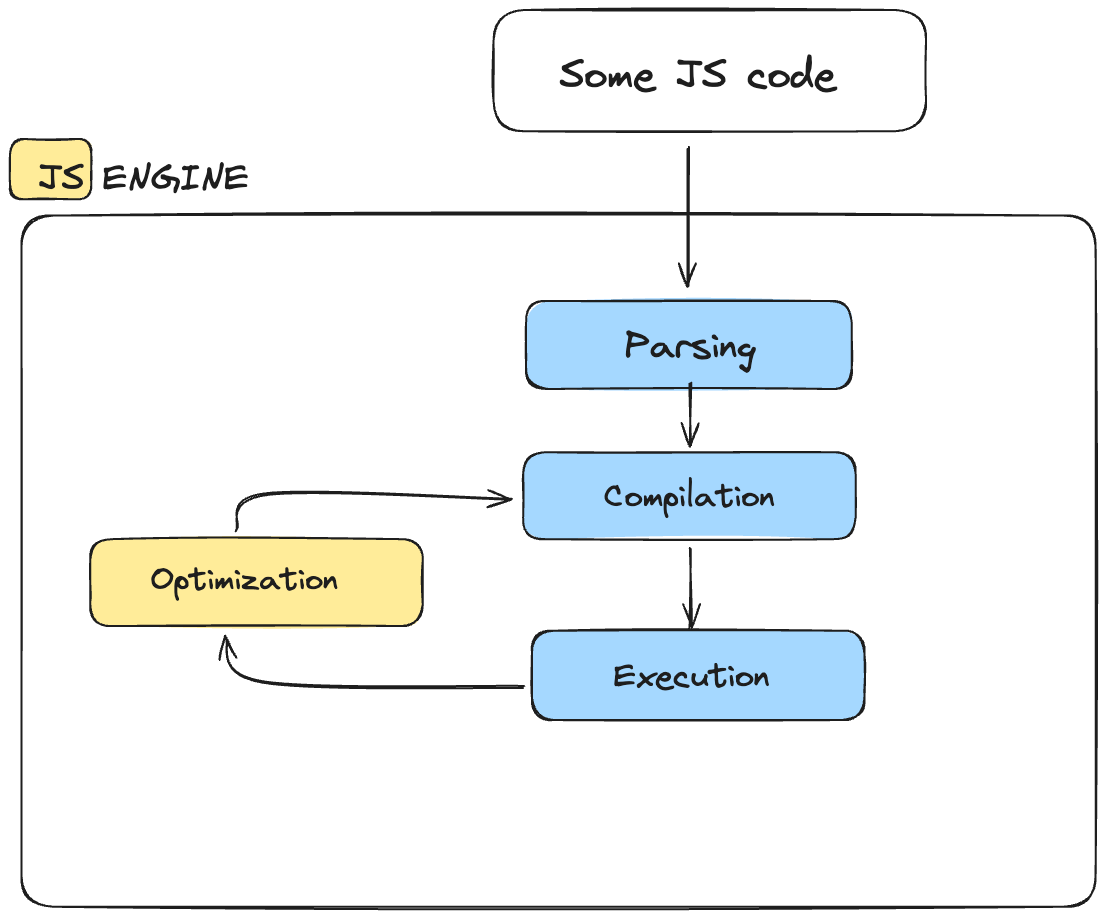 JIT in JavaScript
JIT in JavaScript
So, up to this point, you have learned about the JS Engine and how it works behind the scenes. Now, let's learn what a JavaScript runtime is – and in particular the browser runtime.
What is a JavaScript Runtime?
A JavaScript (JS) runtime is a comprehensive environment that enables the execution of JavaScript code. It consists of various components working together to facilitate the execution of JavaScript applications. When we refer to a JS runtime, we're typically talking about the entire ecosystem that extends beyond the basic execution of code.
Depending on where JavaScript is running (the web browser or server-side with Node.js), there might be additional environment-specific features in the runtime. For instance, in a browser, there could be features related to handling browser events, accessing the DOM, and interacting with browser-specific functionalities.
For now, we are just going to learn about the JavaScript runtime in the browser.
Just think of a JS runtime as a big box that includes all the things we need to run JavaScript in the browser.
 JavaScript runtime
JavaScript runtime
The core of a JS runtime is the JS engine.
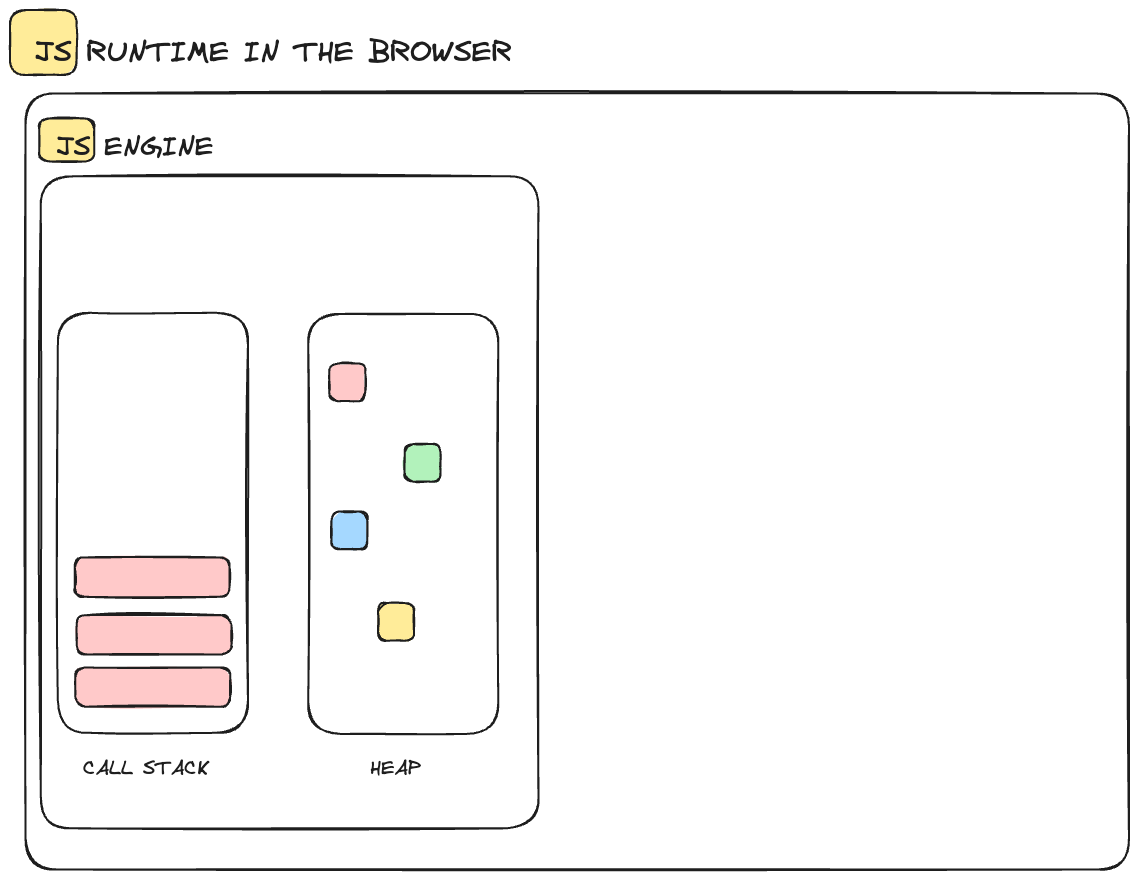 JavaScript engine inside JavaScript runtime
JavaScript engine inside JavaScript runtime
But the engine alone isn't enough. In order to work properly, we need Web APIs.
JS runtimes, especially in the context of web browsers, come with Web APIs that provide additional functionalities beyond the core JavaScript language. These APIs include interactions with the Document Object Model (DOM), XMLHttpRequest (for making HTTP requests), timers, and more.
Web APIs extend the capabilities of JavaScript, enabling it to interact with the browser environment and handle tasks like manipulating the webpage structure, handling user events, and making network requests.
So, basically Web APIs are functionalities that are provided to the engine but they are not a part of the JavaScript language itself. JavaScript gets access to these APIs through the window object.
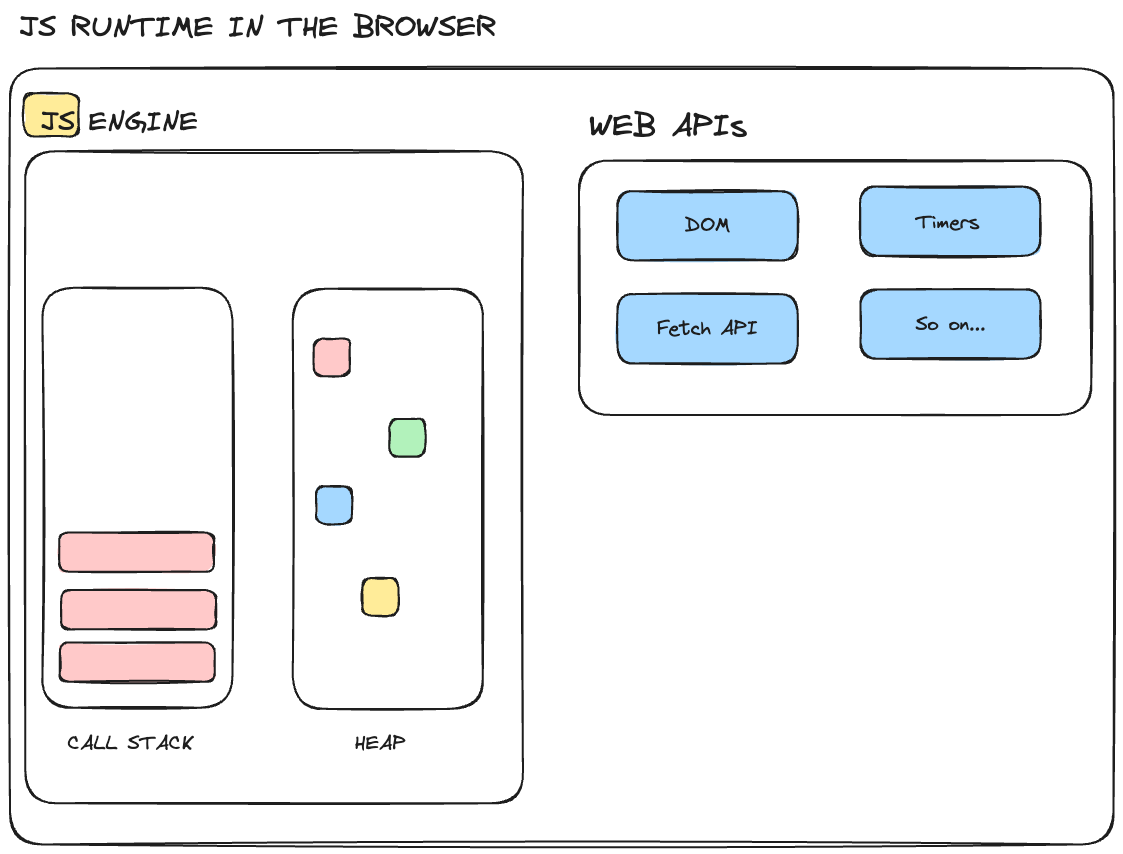 JavaScript engine and web APIs in JavaScript runtime
JavaScript engine and web APIs in JavaScript runtime
Asynchronous operations in JavaScript, such as handling user input or making network requests, utilize callback functions. These functions are placed in a queue known as the callback queue, awaiting execution. The callback queue ensures that asynchronous tasks are handled in an organized manner.
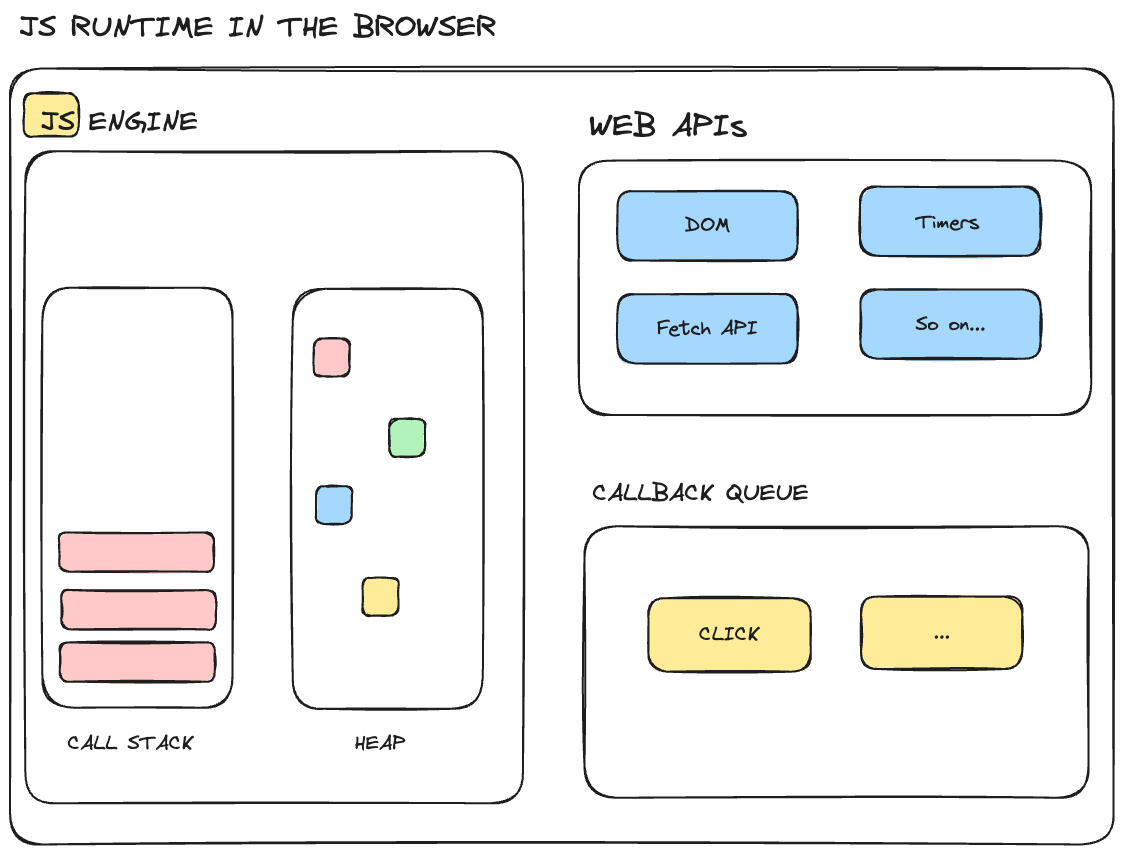 JavaScript Engine, Web APIs and callback queue in JavaScript runtime
JavaScript Engine, Web APIs and callback queue in JavaScript runtime
For example, we attach event handler functions to DOM events like a button to react to certain events. These event handler functions are also called callback functions. So, as the click event happens, the callback function will be called
Here is how it works behind the scenes:
- First, after the event occurs, the callback function is put into the callback queue.
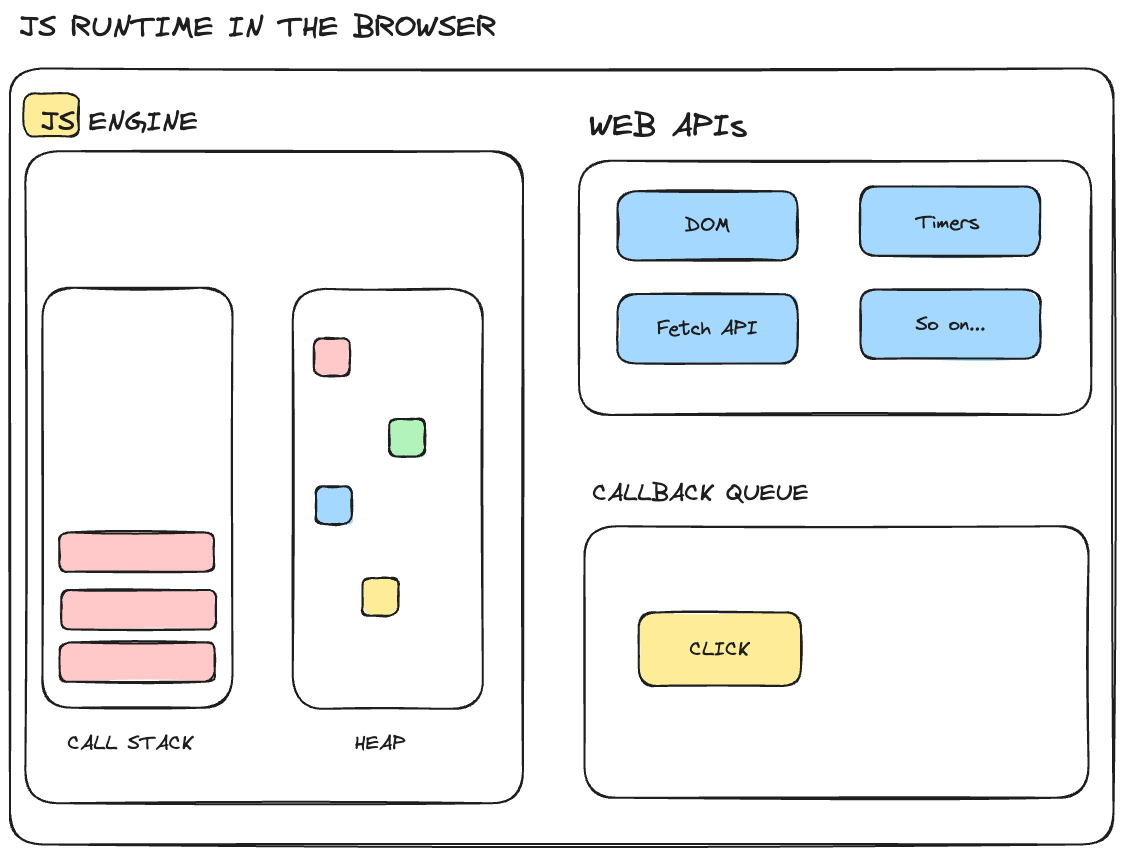 click event is inside the callback queue
click event is inside the callback queue
- Then, when the call stack is empty, the callback queue gets passed to the call stack so that it can be executed and this happens by something called the Event Loop.
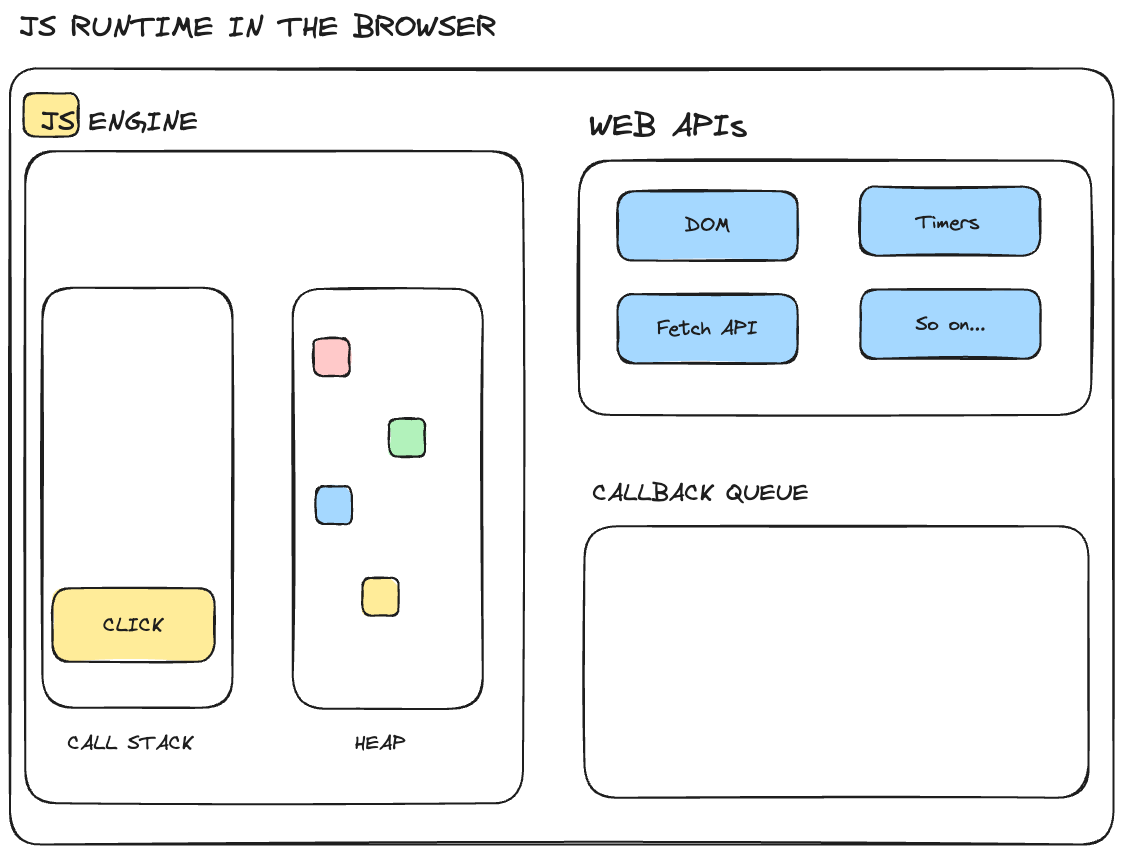 click event now goes into the call stack
click event now goes into the call stack
So, in short, the event loop takes callback functions from the callback queue and puts it into the call stack, so that it can be executed.
That's it! You now know the basics of how the JS Engine and JS Runtime work.
Conclusion
To review, a JavaScript engine is a program designed to execute JavaScript code. It utilizes the call stack and execution context, with all necessary data stored in the heap.
When examining the JavaScript runtime in a browser, it consists of the JS Engine, WEB APIs, callback queue, and an event loop. The event loop plays a crucial role in transferring callback functions from the queue to the call stack, ensuring the seamless execution of JavaScript applications.