

Excerpted from my book: Teach Yourself Linux Virtualization and High Availability: prepare for the LPIC-3 304 certification exam — also available from my Bootstrap-IT site.
Despite having access to ever more efficient and powerful hardware, operations that are run directly on traditional physical (or bare-metal) servers unavoidably face significant practical limits. The cost and complexity of building and launching a single physical server mean that effectively adding or removing resources to quickly meet changing demand is difficult or, in some cases, impossible. Safely testing new configurations or full applications before their release can also be complicated, expensive, and time-consuming.
As envisioned by pioneering researchers Gerald J. Popek and Robert P. Goldberg in a paper from 1974 (“Formal Requirements for Virtualizable Third Generation Architectures” — Communications of the ACM 17 (7): 412–421), successful virtualization must provide an environment that:
- Is equivalent to that of a physical machine so that software access to hardware resources and drivers should be indistinguishable from a non-virtualized experience.
- Allows complete client control over virtualized system hardware.
- Wherever possible, efficiently executes operations directly on underlying hardware resources, including CPUs.
Virtualization allows physical compute, memory, network, and storage (“core four”) resources to be divided between multiple virtual entities. Each virtual device is represented within its software and user environments as an actual, standalone entity. Configured properly, virtually isolated resources can provide more secure applications with no visible connectivity between environments. Virtualization also allows new virtual machines to be provisioned and run almost instantly, and then destroyed as soon as they are no longer needed.
For large applications supporting constantly changing business needs, the ability to quickly scale up and down can spell the difference between survival and failure. The kind of adaptability that virtualization offers allows scripts to add or remove virtual machines in seconds…rather than the weeks it might take to purchase, provision, and deploy a physical server.
How Virtualization Works
Under non-virtual conditions, x86 architectures strictly control which processes can operate within each of four carefully defined privilege layers (described as Ring 0 through Ring 3).
Normally, only the host operating system kernel has any chance of accessing instructions kept in Ring 0. However, since you can’t give multiple virtual machines running on a single physical computer equal access to ring 0 without asking for big trouble, there must be a virtual machine manager (or “hypervisor”) whose job it is to effectively redirect requests for resources like memory and storage to their virtualized equivalents.
When working within a hardware environment without SVM or VT-x virtualization, this is done through a process known as trap and emulate and binary translation. On virtualized hardware, such requests can usually be caught by the hypervisor, adapted to the virtual environment, and passed back to the virtual machine.
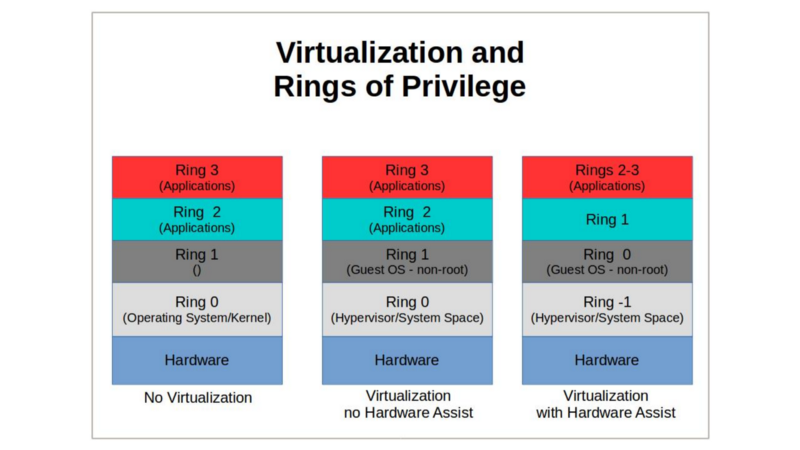
Simply adding a new software layer to provide this level of coordination will add significant latency to just about every aspect of system performance. One very successful solution has been to introduce new instruction sets into CPUs that create a so-called “Ring -1” that will act as Ring 0 and allow a guest OS to operate without having any impact on other, unrelated operations.
In fact, when implemented well, virtualization allows most software code to run exactly the way it normally would without any need for trapping.
Though often playing a support role in virtualization deployments — emulation works quite differently. While virtualization seeks to divide existing hardware resources among multiple users, the goal of emulation is to make one particular hardware/software environment imitate one that doesn’t actually exist, so that users can launch processes that wouldn’t be possible natively. This requires software code that simulates the desired underlying hardware environment to fool your software into thinking it’s actually running somewhere else.
Emulation can be relatively simple to implement, but it will nearly always come with a serious performance penalty.
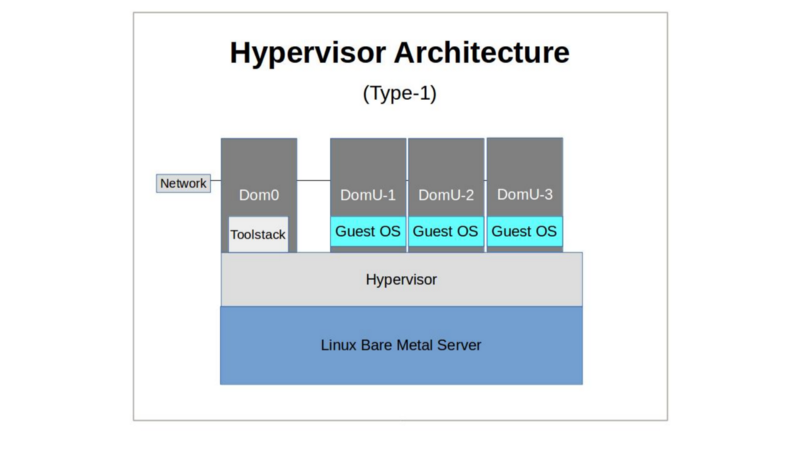
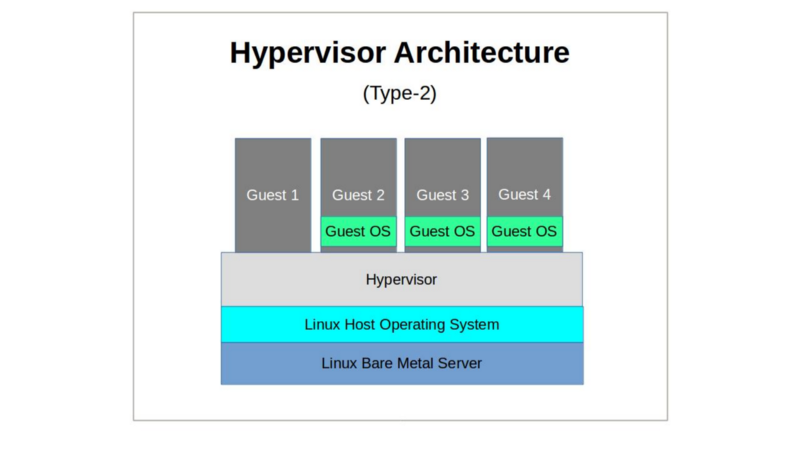
There have traditionally been two classes of hypervisor: Type-1 and Type-2.
- Bare-metal hypervisors (Type-1) are booted as a machine’s operating system and — sometimes through a primary privileged virtual machine (VM) — maintain full control over the host hardware, running each guest OS as a system process. XenServer and VMWare ESXi are prominent modern examples of Type-1. In recent years, popular usage of the term “hypervisor” has spread to include all host virtualization technologies, but once upon a time, it would have been used to describe only Type-1 systems. The more general term covering all types would originally have been “Virtual Machine Monitors”. Insofar as people use the term Virtual Machine Monitors at all these days, I suspect they mean “hypervisor” in all its iterations.
- Hosted hypervisors (Type-2) are themselves simply processes running on top of a normal operating system stack. Type-2 hypervisors (which include VirtualBox and, in some ways, KVM) abstract host system resources for guest operating systems, providing the illusion of a private hardware environment.
Virtualization: PV vs HVM
Virtual Machines (VMs) are fully virtualized. Or, in other words, they think they’re regular operating system deployments living happy lives on their own private hardware. Because they don’t need to interface with their environment any differently than a standalone OS, they can run with off-the-shelf unmodified software stacks. In the past, though, this compatibility came at a cost, as translating hardware signals through an emulation layer took extra time and cycles.
Paravirtual (PV) guests are, on the other hand, at least partially aware of their virtual environment, including the fact that they’re sharing hardware resources with other virtual machines. This awareness means that there’s no need for PV hosts to emulate storage and network hardware and makes efficient I/O drivers available. Historically, this has allowed PV hypervisors to achieve better performance for those operations requiring connectivity to hardware components.
However, to provide guest access to a virtual Ring 0 (i.e., Ring -1), modern hardware platforms — and in particular Intel’s Ivy Bridge architecture — introduced a new library of CPU instruction sets that allowed Hardware Virtual Machine (HVM) virtualization to leapfrog past the trap-and-emulate bottleneck and take full advantage of hardware extensions and unmodified software kernel operations.
The recent Intel technology, Extended Page Tables (EPT), can also significantly increase virtualization performance.
Therefore, for most use cases, you will now find that HVM provides greater performance, portability, and compatibility.
Hardware Compatibility
At least some virtualization features require hardware support — especially from the host’s CPU. Therefore you should make sure that your server has everything you’ll need for the task you’re going to give it. Most of what you’ll need to know is kept in the /proc/cpuinfo file and, in particular, in the “flags” section of each processor. Since there will be so many flags however, you’ll need to know what to look for.
Run
$ grep flags /proc/cpuinfo
…to see what you’ve got under the hood.
Container Virtualization
As we’ve seen, a hypervisor VM is a complete operating system whose relationship to Core Four hardware resources is fully virtualized: it thinks it’s running on its own computer.
A hypervisor installs a VM from the same ISO image you would download and use to install an operating system directly onto an empty physical hard drive.
A container, on the other hand is, effectively, an application, launched from a script-like template, that thinks it’s an operating system. In container technologies (like LXC and Docker), containers are nothing more than software and resource (files, processes, users) abstractions that rely on the host kernel and a representation of the “core four” hardware resources (i.e, CPU, RAM, network and storage) for everything they do.
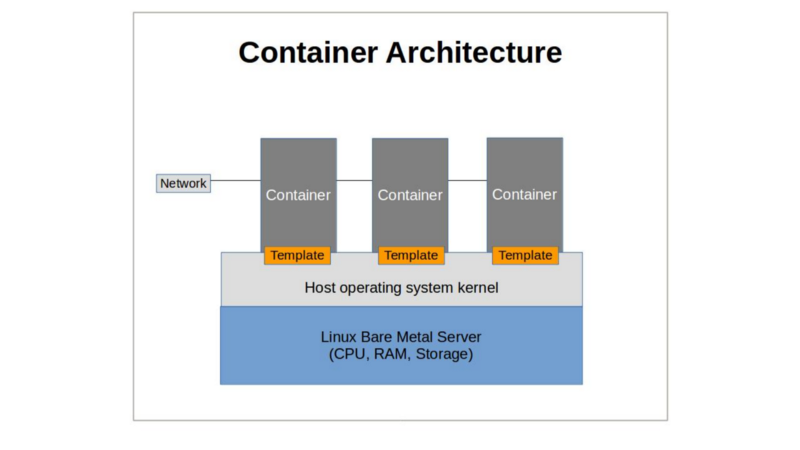
Of course, since containers are, effectively, isolated extensions of the host kernel, virtualizing Windows (or even older or newer Linux releases running incompatible versions of libc) on, say, an Ubuntu 16.04 host, is impossible. But the technology does allow for incredibly lightweight and versatile compute opportunities.
Migration
The virtualization model also permits a very wide range of migration, backup, and cloning operations — even from running systems (V2V). Since the software resources that define and drive a virtual machine are so easily identified, it usually doesn’t take too much effort to duplicate whole server environments in multiple locations and for multiple purposes.
Sometimes it’s no more complicated than creating an archive of a virtual file system on one host, unpacking it within the same path on a different host, checking the basic network settings, and firing it up. Most platforms, offer a single command line operation to move guests between hosts.
Migrating deployments from physical servers to virtualized environments (P2V) can sometimes be a bit more tricky. Even creating a cloned image of a simple physical server and importing it into an empty VM can involve some complexity. And once that’s done, you may still need to make considerable adjustments to the design to take full advantage of all the functionality the virtualization has to offer. Depending on the operating system that you are migrating, you might also need to incorporate paravirtualized drivers into the process to allow the OS to run properly in its new home.
As with everything else in server management: carefully plan ahead.
Excerpted from my book: Teach Yourself Linux Virtualization and High Availability: prepare for the LPIC-3 304 certification exam.
Interested in learning to deploy practical Linux admin projects? Check out my Manning book, Linux in Action.
Or, you can try a hybrid course called Linux in Motion that’s made up of more than two hours of video and around 40% of the text of Linux in Action.