By Yisroel Yakovson
Meet the Full Graph Stack
Are you looking for some quick new marketable skills? Or, do you want to create a robust back-end in a day for a startup?
I’m about to tell you how I did just that. More importantly, I’ll tell you how GraphQL has unleashed a brilliant disruption to app stacks.
I’ve got a masters in Computer Science and some recent patents in user interfaces to data. So in some ways, I can appreciate the power of these breakthroughs.
The times are changing, fast. I’ve spent a fascinating month rethinking backends, APIs, databases, and stacks. I was about to hire a senior back-end developer. The funny thing is, in the end, I decided that I did not need one. And you might not either.
I call this new type of app stack a Full Graph Stack, or Graph Stack for short.
The Basic Approach
You build a graph showing the data that you need for your front end. Then, recently developed tools generate the back end from scratch.
If you are unclear on what a graph is, take a few minutes to clarify that. An informal definition is enough: a graph is a set of points (think circles) with lines connecting them. A common name for these points is nodes, and the lines are edges.
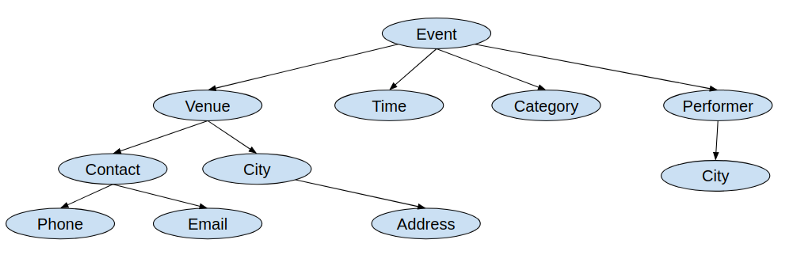
An app (including a web app) has types of information. A graph can represent the data needs of an app. The info types are nodes, and relationships between them are edges. For instance, the graph for an app to handle events may look like this:
The key point is that one such graph organizes every level of your app code, from the front end to the back end.
How it Works
A full graph stack focuses on a GraphQL schema specification. Directives may enhance the specification. If you’re not familiar with GraphQL, read up on it. For our purposes, API queries are subsets of the app graph.
The GraphQL schema contains a graph of core types and their relationships. Apollo offers a set of services that simplify building GraphQL interfaces. The data graph is the TypeDefs.
The TypeDefs are central to everything in the full graph stack. Your job is to create the TypeDefs to show your app graph. Converters generate:
- a full GraphQL schema from your TypeDefs. That includes mutations, which are updates.
- resolvers. These are functions that implement queries and mutations on your back end. As discussed in the second article, the converter that I used was neo4j-graphql-js.
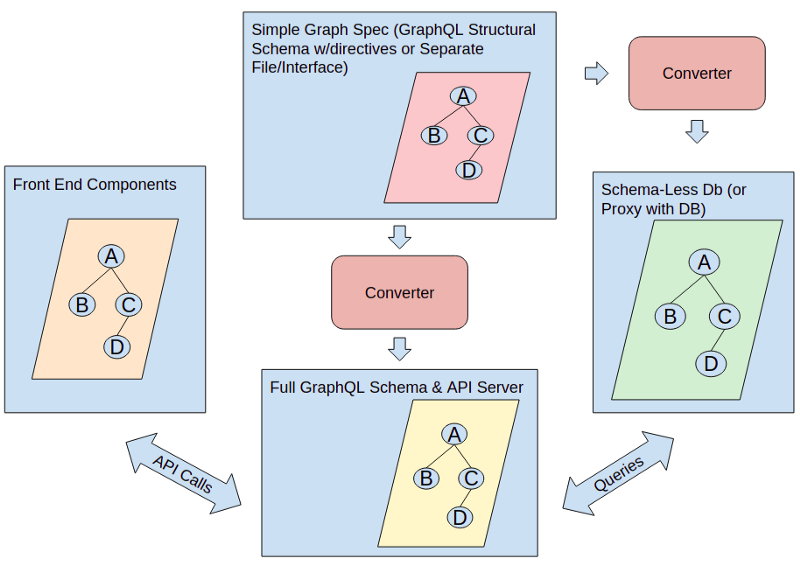
The key is that the back end uses a database that is either schema-less. Schema-less means that data is not confined to a predefined structure, or schema. Traditional relational databases limit data to their schema.
The common approach is to create a virtually schema-less database using Prisma.
But I urge you to consider a second approach: using an inherently schema-less database! Document stores and graph databases have no inherent schema. So you can take a schema-less database and conform it’s data to the schema of the GraphQL API.
You might object that it’s not that hard to map a GraphQL schema to a relational database. I agree, but today we need the flexibility to iterate. A full graph stack gives you that. A startup can pivot endlessly. A schema-less database is easy to update to conform to changes on the API.
Graph Databases
I argue that graph databases are the most ideal approach to a full graph stack. The databases are themselves graphs and thus map transparently to the GraphQL schema. You will be likely to have to deal with your database server at some point. Doing so is most simple and intuitive when it’s data structure is identical to your API.
Graph databases are not new. Many semantic database models sprung up in the 70’s and 80’s. Most presented the schema as a graph. But none of them grabbed much traction until the last decade.
Recent developments have fueled a new appreciation for graph data models:
- big data
- machine learning maturation
- needs for more efficient and flexible alternatives to relational databases (so-called NoSQL Databases).
There are a lot of graph database providers today. The current market leader is Neo4j, but significant competition looms. I do not claim that I have researched the options and determined that Neo4j is the best. But, Neo4j is very established, and tremendous support is out there for using them.
The Front End
I’m focusing on the back end in these articles, but the graph stack extends through to the front end.
The GRANDstack site observes that React is particularly suitable for a graph stack. React uses a simple hierarchy of elements which can map to GraphQL queries.
Apollo’s Query component even lets an element query it’s data directly. So components using query map to GraphQL. Your single source of truth becomes the back end. That is much simpler than recreating back end data in a Redux state.
Advantages
The full graph stack is a new paradigm, and not everyone has grasped its power. Many articles and blogs in recent years discuss solutions centered around GraphQL. Most claim things like an “instant back end”. But the fundamental goal of a single graph running your stack is not yet globally understood. Once people appreciate that vision, tools will become more consistent and complete.
In short, the advantages of a full graph stack are:
- Quick implementation.
- Flexibility. You can iterate your solution fast.
- Transparency.
- Consistency. The same graph at every level.
- Independence. The api-level focus with a simplified back end removes lock-in for back end services. This is a surprising turnaround. Power moves away from the vying cloud service providers.
Check out Launch Your MVP Server in an Hour for step-by-step instructions on building one!
This is the first of 3 articles about Full Graph Stacks. See also Launch Your MVP Server in an Hour and From MVP To Production Server In A Day.