
By Michael Shilman
A quick and dirty guide to scaling your launch and embracing the Internet hug of death
Startup Genome says premature scaling is the number one cause of startup death. You shouldn’t spend time optimizing a product when you don’t even know if users want it.
Yet every time you launch a web app, you run the risk of actually succeeding, and your server should be ready to handle the load.
In this article I’ll share a simple, free recipe to get your app launch-ready. An hour spent following these steps will save you countless hours of sleep over the course of your product’s lifetime.
In a nutshell:
- Benchmark using a load-testing tool like Loader.io.
- Use a caching proxy like NGINX to mitigate server load.
- Use a CDN like Cloudflare for fast loading and global distribution.
First-World Problems
Let’s get this out of the way. Having too much traffic to your website is a first-world problem, and writing about it is the ultimate humblebrag. Guilty on all fronts. Sue me.

But it’s still a problem. The startup world is filled with tales of services hitting the front page of Reddit, getting “unexpectedly” hunted on Product Hunt, and so forth. It’s a cliche at this point.
This article is the opposite of that. In the past year I’ve launched three services to millions of users and slept like a baby while my server was getting hammered by clicks, with zero downtime.
 You never know which channels will generate clicks, but it’s good to be prepared.
You never know which channels will generate clicks, but it’s good to be prepared.
Hello Money is Reddit’s tool of choice for portfolio visualization and peer feedback. Spikes: It ranked #1 on Product Hunt the day it launched and named by PH as one of the 7 best personal finance apps, has reached the top of /r/personalfinance multiple times (nearly 7M readers), and has been featured on Hacker News.
Goodbye Gun Stocks shows socially-conscious investors whether their mutual fund and ETFs are invested in gun companies and helps them find similar gun-free funds with lower fees and better historical returns. Spikes: written up in New York Daily News, Fortune, Time, Fast Company, Vice (Twice!), GOOD, it’s the #1 politics app on Product Hunt excluding Trump jokes (which are hard to compete with!). It’s also gotten a lot of love on both Twitter and Facebook.
Sidebar is Sacha Greif’s daily design newsletter. Sacha is a design powerhouse with over 20k twitter followers, numerous massive mailing lists, and an abundance of Hacker News karma. Whenever he launches anything it gets flooded with attention, so before he launched a redesign of Sidebar, I used this game plan to help make sure it could handle the load.
 Nice problems to have!
Nice problems to have!
Third-World Solution
For anybody who has built a truly Internet-scale service, like Google, Facebook, Amazon, I apologize in advance. Likewise, if you list DevOps as one of your skills you may be sickened by what you read here.
What I’m describing is a quick bandaid solution for startup folks like me who are ecstatic when their site receives 100,000 visitors in a shot. For a long-term scaling solution, look somewhere else.
I’ll present the solution in order. Plan to spend an afternoon on it the first time you implement this flow. Once you’re comfortable with it, you should be able to get a site ready in an hour or so.
Here are the steps again:
- Benchmark using a load-testing tool like Loader.io.
- Use a caching proxy like NGINX to mitigate server load.
- Use a CDN like Cloudflare for fast loading and global distribution.
1. The Mother of all Loads
The first step in getting ready is to measure your existing service under load, simulating thousands of user visits over a 1-minute interval.
There are a million different open source tools for load testing, but we want to get everything done in an hour, so we’ll use Loader.io, a free SaaS that’s trivial to set up and use.
There are only a few parameters you need to configure and then you’re set:
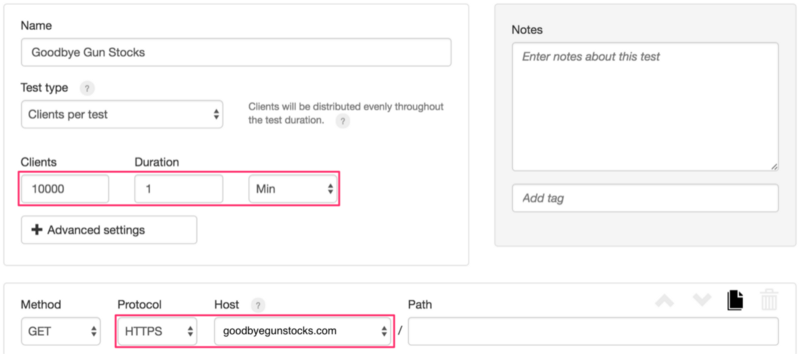 Load testing your service is as easy as filling out two fields.
Load testing your service is as easy as filling out two fields.
If you haven’t done any optimizations yet, the first run will probably break your service, and that’s OK. Here’s me breaking Goodbye Gun Stocks during my launch prep:
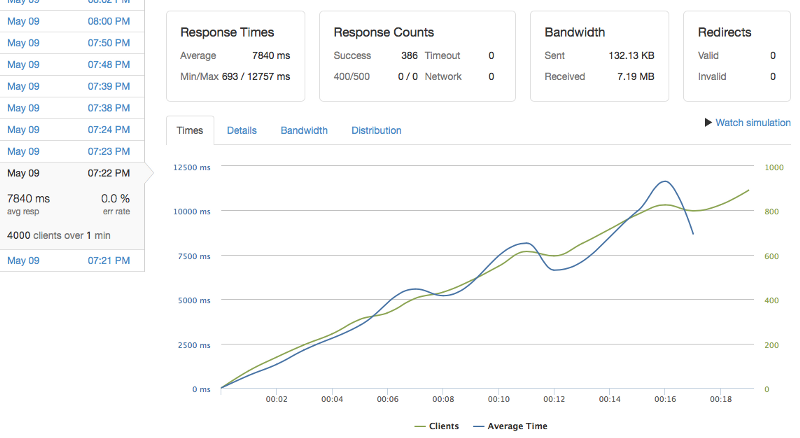 Before optimization: GoodbyeGunStocks.com breaks with 4K client load over a 1 minute interval.
Before optimization: GoodbyeGunStocks.com breaks with 4K client load over a 1 minute interval.
On the X axis is time, and the Y axis shows both active clients and average response time. Over time, both of these values increase steadily. Response time starts at 0 and grows to over 10 seconds during the course of the run. This is because the service is unoptimized and can’t handle the requests in time. Requests back up and everything grinds to a halt.
In contrast, here’s what a successful run looks like. The response time is down to an average of 9ms and stays that way through most of the run, occasionally spiking up to around 17ms.
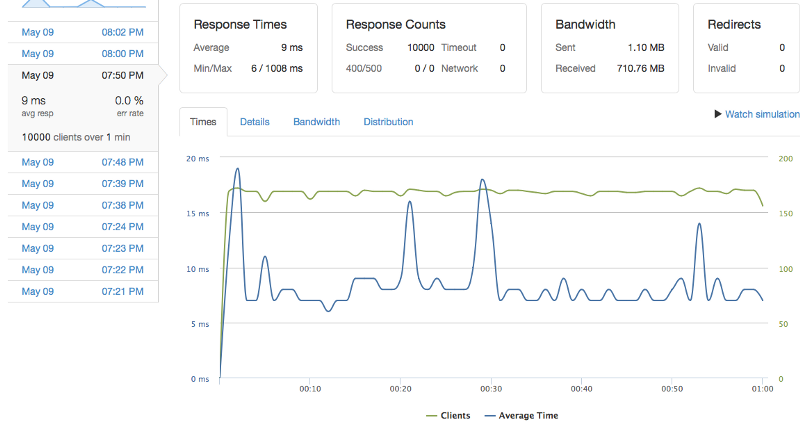 After optimization: GoodbyeGunStocks.com survives a 10K client load over a 1 minute interval.
After optimization: GoodbyeGunStocks.com survives a 10K client load over a 1 minute interval.
Note that since this is a quick-and-dirty approach to load testing, it has its limitations:
- Limited load. Loader.io’s free plan is limited to a maximum of 10,000 requests per minute, but that’s more than most services will get, even if they top out ProductHunt, Hacker News, and Reddit. If you really care, you can just upgrade to a paid version.
- HTTP/S only. Loader.io only supports HTTP/S requests for now. Some modern web apps, such as Meteor (which was used to build all three services above) also use websockets for communication. If you really care, you can use other tools to load test, but you probably won’t be done in an hour. For example Meteor has MeteorDown for load testing. Kadira, by the same authors, is the best tool hands-down for understanding Meteor performance issues.
2. NGINX: The Band-Aid of the Internet
If your service survived the load test, you may as well launch now. If not, you might be second-guessing yourself, and it’s probably worth seeing whether there’s a quick fix.
There are so many possible explanations for what went wrong, and even for a small app you could spend a lifetime tuning server configurations, database queries, and badly-written loops.
But screw all that. NGINX is a free, open-source high-performance web server and jack-of-all-trades proxy. You can use it to smooth over most performance issues with a small time investment. After you learn it, it will be a trusted tool you can use for kludging over everything you build in the future.
The key thing about NGINX is that it’s blazingly fast and with a little work you can configure it to do almost anything. For all of my services, I run an NGINX server in front of the actual service, as a caching load-balancing reverse proxy:
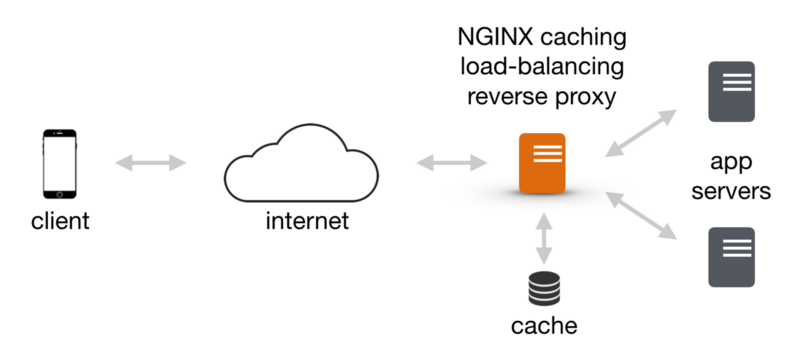 A caching load-balancing reverse proxy to atone for all of your performance sins.
A caching load-balancing reverse proxy to atone for all of your performance sins.
Setting it up
Setting up NGINX is a quick and well-documented process. The confusing thing is that it does so many different things it can be difficult to configure. So I’ll cut to the chase and share the configuration we’re using for Sidebar, and explain it so you can use it as a starting point for optimizing your own service:
There are three key things going on here:
- Reverse Proxy. All the configuration lines below the PROXY STARTS HERE line configures NGINX to be a reverse proxy, meaning that it forwards requests on to your web app, fetches the response, and returns the response to the requestor.
- Load Balancer. The upstream declaration at the top configures NGINX to also be a load-balancer, so it can farm requests out to multiple back-end servers instead of just one.
- Cache. Everything after the CACHING line sets NGINX up to be a cache, meaning that NGINX can store some of the responses and return the results without ever hitting the back-end app server.
NGINX as a reverse proxy is not important in and of itself, but it enables load balancing and caching, which are both awesome for scalability. So let’s drill into those a bit.
Load Balancer
Load balancing means that you can set up multiple app servers to run your app. This has a few benefits:
- Horizontal Scalability. If your app is CPU- or memory-bound, and your traffic maxes out your server, you can easily add another back-end server.
- Dynamic Redeployment. If you need to modify your server code, you can spin up a new machine running the new code, test it out, and then add it into the load-balancer
- Fault Tolerance. If one of your servers crashes or gets overloaded, NGINX can be configured to automatically remove it from the list. The configuration above does not do this, but it’s possible to add.
The only down-side to running a load balancer is a minor increase complexity (totally worth it), and potentially increased server costs. Note that you can also proxy to a server running on a different port on the same machine to save cost, and NGINX is so efficient that this is OK for all but giant loads.
Caching
Caching means that HTTP responses are stored disk for some period, and when a client makes the same request during that cache period, NGINX will return the cached response rather than hitting the app server.
This has a couple key benefits:
- Decreased server load. NGINX is incredibly efficient and can handle thousands of requests on a normal server. I’ve never run into any problems with it, even running high-traffic sites. The real problem is with app servers or databases, and every cached response from NGINX is one less request that the app server needs to handle.
- Response speed. The cached responses are super fast. If your data is not rapidly changing or user-specific, then the user should see the result in milliseconds if she is on a reasonably fast connection.
Unlike load balancing, caching can have some downsides, and you should be careful about how you cache.
- Stale data. The most obvious problem is stale data. If your data has lots of highly dynamic data like a realtime stock site, or lots of user-specific data, then caching is a challenge. However, most pages and apps have a mostly static homepage which captures most of the traffic, and then a more dynamic sections which much fewer users click through to. If your service has this pattern, you can cache the former, and leave the latter uncached.
- Decreased security. If your responses have user-sensitive data in them, you cannot cache them. Be careful about caching and security! In the configuration above that we created a $skip_cache variable to avoid caching for signed-in users. We test for the cookie meteor_login_token but this should be easy to customize for your setup.
- Complexity / Debug-ability. As soon as you start caching you introduce a major new source of complexity into the system. When something goes wrong is it because there’s a bug in the service, or a bug in the cached response, or?
In spite of the problems with caching, with a little practice it can be a great quick fix for almost any performance issue. There are plenty of other places you can cache too (database requests, etc.), but NGINX is easy.
Re-run Your Load Test
As you optimize your service, re-run your load test. Here’s Goodbye Gun Stocks after receiving some NGINX love:
After optimization: GoodbyeGunStocks.com survives a 10K client load over a 1 minute interval.
After your service is handling the load, be sure to do manual testing to make sure you haven’t broken anything. Be sure to test basic functions like user signin / signout, since those are things that are easy to mess up when you cache. If everything looks good, you should be good to go.
Setting up NGINX like this can cover up even the most inefficient server code. It can take some fiddling, but for most apps it will do the trick for getting you launch ready in a snap.
3. Going Global
OK, you’ve gotten through the hard part and you’ve got a service that can withstand most traffic spike. But the Internet is a global village, and if you post your service to any major traffic source, you’ll be getting traffic from the other side of the planet. Let’s make sure those users have a decent experience too.
Fortunately, there are Content Delivery Networks for this. I recommend Cloudflare. The basic options are free and should be more than enough for your MVP.
 Cloudflare’s tabbed UI has lots of options, but it only takes a minute to configure the basics.
Cloudflare’s tabbed UI has lots of options, but it only takes a minute to configure the basics.
In addition to making all your static assets load faster, setting up Cloudflare has a few other benefits:
- Security. Cloudflare gives you one-click HTTPS. Setting up HTTPS on your server can be a pain, even with awesome services like LetsEncrypt that make it relatively cheap and easy. Cloudflare provides a minimal HTTPS with a click of a button, even if your server is only running HTTP. This is good enough for many minimum viable products, though if you’re dealing with sensitive information such as finance or health security, you should definitely encrypt the entire flow.
- DDoS protection. When I was launching Goodbye Gun Stocks, I worried about potential denial of service attacks since gun violence prevention is a hot-button issue in the US. It ended up not being a problem, but if it had been Cloudflare has some built-in service to help handle that. I haven’t used it, but it’s great to know somebody has your back.
Ok, Now Ship it!
Using this launch kit you can quickly take your new service from minimum viable product to a load-tested, launch-ready, and globally accessible service. This is all possible using free tools and a minor time investment.
If your service goes totally viral like The Dress, whose Tumblr page received 14,000 views a second at its peak, then these techniques probably won’t cut it, and your servers may end up in a smoking heap. But hey, there are worse problems to have!
Comment below with questions or suggestions. And follow me here or on Twitter for more great articles coming down the pipe.
Best of luck and happy launching!
And finally, if this was useful, please tap the ? button below. Thanks!
Many thanks to Keywon for making Hello Money and Goodbye Gun Stocks launches a success and introducing me to this “problem”; Sacha Greif and Josh Owens for Sidebar ops collaboration; WooGenius for figuring out load testing with me.
Header image: Jeff Eaton