
By Ovidiu Bute
The word monorepo is a combination between “mono”, as in the Greek word mónos (in translation, alone) and an abbreviation of the word repository. A simple concept if taken verbatim: one lonely repository. The domain is software engineering so we’re referring to a home for source code, multimedia assets, binary files, and so on. But this definition is just the tip of the iceberg, since a monorepo in practice is so much more.
In this article I plan to distill the pros and cons of having every piece of code your company owns in the same repository. At the end you should have a good idea about why you should consider working like this, what challenges you’ll face, what problems it’ll solve, and how much you’ll need to invest in it.
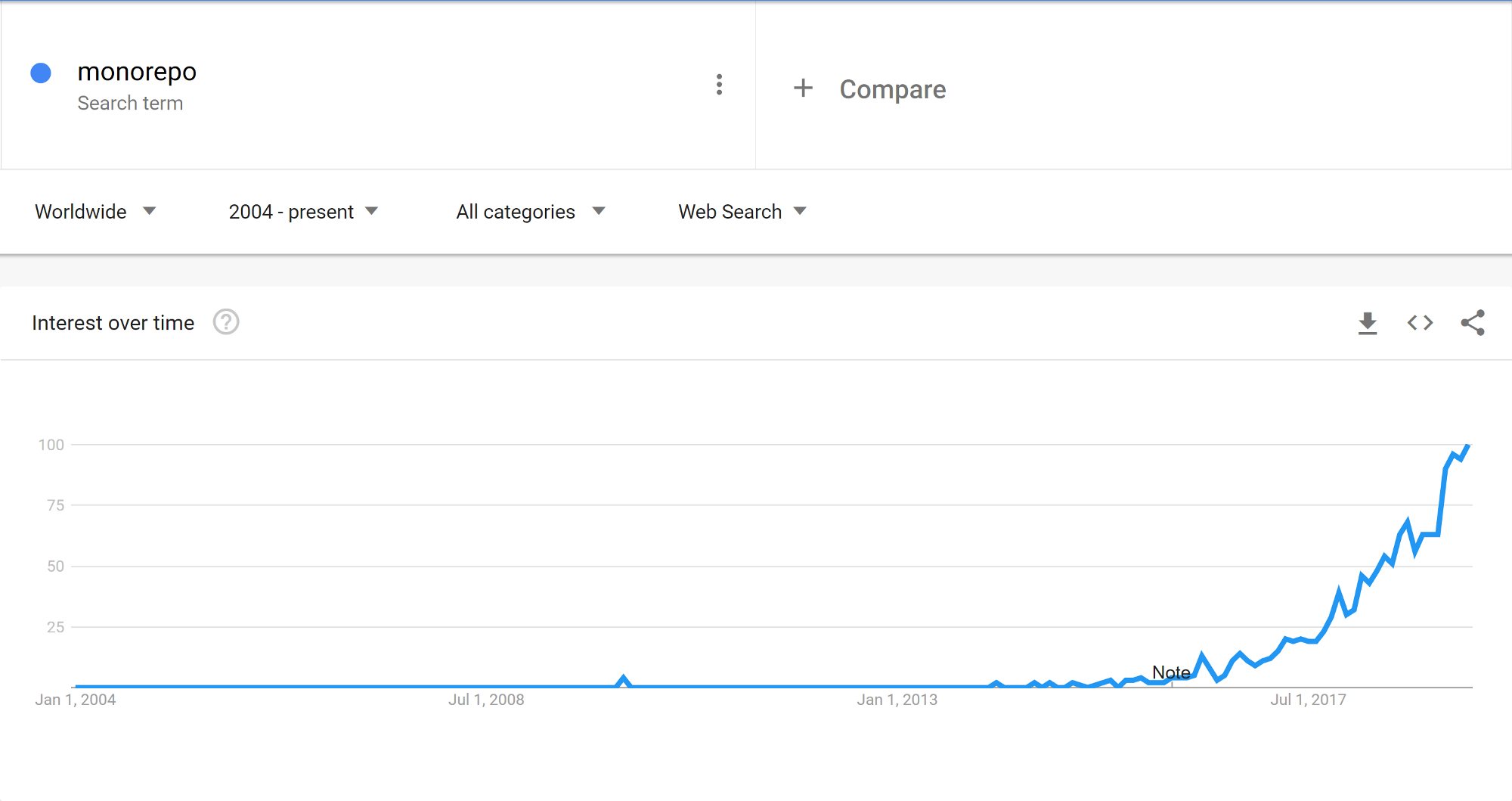 Relative interest in the term “monorepo” since 2004, source: Google Trends
Relative interest in the term “monorepo” since 2004, source: Google Trends
The term itself, as visible in the chart above, looks to be as new as 2017. However it would be a mistake to think that previously nobody was storing all of their code in one place. In fact during my first job back in 2009, the company I worked at stored every project in a single SVN repository, one directory per project. Indeed you may well be able to trace this practice back even further. But how can we explain the recent explosive popularity, then?
The reality is that storing code in a single spot is not the main selling point. In the past years the major tech companies — Google, Facebook, or Dropbox have been showing off their way of working together within the same repository at massive scale. Organizations of tens of thousands of engineers collaborating within one repository is an awesome sight. And a difficult engineering problem. So difficult in fact that these companies invest a lot of money into tools and systems that allow developers to work productively. These systems in turn have solved problems that you may not even realize you had. This is what fascinates people during tech talks. This is what’s been driving searches since 2017.
- Front-end development at Google, Alex Eagle: https://medium.com/@Jakeherringbone/you-too-can-love-the-monorepo-d95d1d6fcebe
- Google monorepo presentation, Rachel Potvin: https://www.youtube.com/watch?v=W71BTkUbdqE
- Scaling Mercurial to the size of Facebook’s codebase, Durham Goode: https://code.fb.com/core-data/scaling-mercurial-at-facebook/
I’ve identified a few core features that a Google or a Facebook vetted monorepo offers. This is surely not an exhaustive list, but it’s a great starting point. When discussing each of one of these points, I took into consideration what life looks like without them, and what exactly do they solve. Certainly in our field of work everything is a trade-off, nothing’s free. For every pro that I list someone will find use-cases that directly contradict me, butI’m OK with that.
All your code, regardless of language, is located in one repository
The first advantage of storing everything in once place may not be immediately obvious, but as a developer, simply being able to freely browse through everything is of great impact. It helps foster a sort of team spirit and is also a very valuable and cheap way to distribute information. Have you ever asked yourself what projects are in development at your company? Past and present? Curious what a certain team is up to? How have they solved a particular engineering problem? How are they writing unit-tests?
In direct opposition to the monorepo we have the multirepo structure. Each project or module gets its own separate space. In such a system developers can spend quite a bit of time getting answers to the questions I listed above. The distributed nature of the work means there’s no single source of information that you can subscribe to.
There are companies that have transitioned from a multi to a monorepo layout by following only this feature from my list. Such a structure should not be confused with the topic of this article though. I’d define it instead as a collocated multirepo. Yes, everything is in one place, but the rest of the features on this list are far more interesting.
You‘re able to organize dependencies between modules in a controlled and explicit way
The traditional, battle tested way of handling dependencies is by publishing versions to a separate storage system from continuous integration systems, or even manually, from development machines. These are versioned (or tagged) to make it easier to search later on. Now in a multirepo setup, each project has a set of dependencies of external origins (third parties) or internal, as in, published from inside the same company.
In order for one team to depend on another one’s code, everything needs to pass through a dependency management storage system. Examples of this are npm, MavenCentral, or PyPi. I said earlier that you can easily build a collocated multirepo just by storing everything in one place. Such a system is indirectly observable. Let’s examine why that’s important.
As developers, our time is split very unequally between reading and writing code. Now imagine having to debug an issue that has its root cause inside of a dependency. We can rule out third parties here, since that’s a difficult problem as it is. No, this problem occurs in a package published by another team in your company. If your project depends on the latest version, you’re in luck! Just navigate to the respective directory and grab a cup of coffee.
“Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. …[Therefore,] making it easy to read makes it easier to write.”
― Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
More often though you might depend on an older version. So now what do you do? Do you try and use your VCS to read through the older code? Do you try and read the actual artifact instead of the original code? What if it’s minified, as is usually the case with JavaScript?
Contrast this with Google’s system, for example — since code dependencies are direct, as in, there are essentially no versions anywhere, one can say the system is directly observable. The code you’re looking at is pretty much your entire world. I say mostly because of course there are always going to be minor exceptions to this rule, such as external dependencies that would be prohibitive to host yourself. But that shouldn’t take anything away from this discussion.
While we’re on the topic of dependency management we should touch upon the subject of restrictions. Imagine a project where you’re able to depend on any source file you need. Nothing is off limits, you can import anything. For those of you that started their careers at least 10 years ago, this sounds like business as usual for the time. This is an almost complete definition of a monolith.
The name implies grandeur, scale, but more importantly, singularity. Practically every source file inside of a monolith cannot live outside of it. There’s a fundamental reason for this is relevant to our discussion: you don’t have an explicit and audit-able way of managing dependencies inside of a monolith. Everything is up for grabs, and it feels free and cheap. So naturally, developers end up creating a complex graph of imports and includes.
Nowadays practically everyone is doing microservices, there can be little doubt about that. Given sufficient scale, a codebase becomes a beast, as everything is inexorably linked to each other. I’m sure many developers will provide counter-arguments that monoliths can be managed in a clean, reasonable way without falling into this trap. But exceptions simply reinforce the initial statement. Microservices solve this by defining clear boundaries and responsibilities, and a monorepo is a natural extension of this philosophy. Typically modules offer a set of public exports, or APIs, and other modules are only able to use those as part of their contracts.
Software modules reuse common infrastructure
This is a topic that’s very near and dear to my heart. I’ll define infrastructure in this context, that of a software codebase, as the essential tools necessary to ensure productivity and code quality.
One of the reasons why I think betting your company on multirepos is a mistake has to do with a set of basic requirements any software engineering project should meet:
- A build system to be able to reliably produce a deliverable artifact.
- A way to run automated tests.
- A way to statically analyze code for common mistakes, potential bugs, and enforce best practices.
- A way to install and manage third party dependencies, i.e. software modules which are external to your company.
If you have your code split in multiple repositories, you need to replicate this work everywhere. Don’t underestimate how much work this involves! All of the features listed above require at the very minimum a set of configuration files which need to be maintained in perpetuity. Having them copied across more than two places basically guarantees you will always generate technical debt.
I know that some companies go to extreme lengths to minimize the impact of this. They’ll have their configurations bundled as scaffolding (a la create-react-app or yeoman), and use them to setup new repositories. But as we’ve seen in the section before this one, there’s no way to enforce that everyone’s on the latest version of these boilerplate dependencies! The amount of time spent upgrading each repository individually increases linearly in large codebases. Given sufficient scale, practically all published versions of an internal package will be depended on at the same time!
There’s a quote I absolutely love that relates to this conundrum:
At scale, statistics are not your friend. The more instances of anything you have, the higher the likelihood one or more of them will break. Probably at the same time.
If you think distributed systems just refers to web services, I would disagree. Your codebase is an interconnected, living system. Tens, hundreds, or thousands of engineers are racing to get their code into production each day, all the while struggling to keep the build green and the code quality up. If anything, to me this sounds even scarier than a set of microservices :)
Changes are always reflected throughout the entire repository
This is highly dependent on the rest of the features. It’s one of the benefits that’s easier to understand through example.
Let’s say I work at a company that builds web applications for customers all around the world. Everything is organized into modules, as is exemplified below via the popular open-source project Babel. At this company we all use ReactJS for front-end work, and out of pure coincidence, all of our projects are on the same version of it.
 _Babel’s myriad of modules: [https://github.com/babel/babel/tree/master/packages](https://github.com/babel/babel/tree/master/packages" data-href="https://github.com/babel/babel/tree/master/packages" class="markup--anchor markup--figure-anchor" rel="nofollow noopener noopener" target="blank)
_Babel’s myriad of modules: [https://github.com/babel/babel/tree/master/packages](https://github.com/babel/babel/tree/master/packages" data-href="https://github.com/babel/babel/tree/master/packages" class="markup--anchor markup--figure-anchor" rel="nofollow noopener noopener" target="blank)
But the folks at Facebook publish the latest version of React and we realize that upgrading to it is not trivial. To be more productive, we’ve built a library of reusable components that resides as a separate module. All projects depend on it. This new React version brings lots of breaking changes that affect it. What options do we have for doing the upgrade?
This is typically where monorepo adversaries would shoot down the entire concept. It’s easy to say that we’ve worked ourselves into a corner and that the multirepo structure would’ve been a superior choice given the circumstances. Indeed in the latter case what we would do is just gradually adopt the new React version in our projects one by one, preceded by a major version upgrade of our core components module.
But I would say this creates more problems than it solves. A core dependency breaking change release creates a schism in your engineering team. You now have two cores to maintain: the new one, which is used by a couple, brave teams in a few projects, and the older one, still depended on by almost the entire company.
Let’s take this problem to a bigger scale for further analysis. Our company may have some projects which are still in production, but are just in maintenance mode, and don’t have any active development teams assigned to them. These projects will probably be the last ones to migrate, extending the time window in which you keep working on two cores at the same time. The old version will still receive bugs or security fixes even though it’s deprecated, as you can’t risk your customers’ businesses.
All of this is to say that a multirepo solution promotes and enables a constant state of technical debt. There are lots of migrations going on, modules that depend on older versions of other modules, and many, many deprecation policies which may or may not be enforceable.
Let’s now consider an alternative solution to the React upgrade problem. By having all of the code in one place, and dependent on each other directly, without versioning, we’re left with one option: we have to do all of the work upfront, in all modules simultaneously.
If that sounds like a scary proposition, I don’t blame you. It’s terrifying to think about, at first. However the advantage is clear: no migrations, no technical debt, less confusion around the state of our codebase. In practical terms, there is one obstacle to overcome with this solution — there may be hundreds, thousands, or millions of lines of code that need to be changed all at once. By having separate projects we avoid the sheer volume of work by doing it piece by piece. It’s still the same total amount of changes, but we’re naturally inclined to think it would be easier to do that over time, rather than in one push.
To solve this last problem large companies have turned to codemods — programmatic transformations of source code that can run at very large scale. There are numerous tutorials out there if you’re interested, but the gist of it is — you write code that first detects certain patterns in your source code, and then applies specific changes to it. To take our React example further, you could write a codemod that replaces a deprecated API with a newer one, and even apply logic changes if necessary. Indeed this is how Facebook recommends you migrate from one version of their library to the next. It’s how they’re doing it internally. Check out their open-source examples.
Viewed from this angle, a migration doesn’t seem as scary as before. You do all of your research upfront, you define how you want to essentially rewrite the affected code, and apply the changes more or less all at once. This to me is a robust solution. I’ve seen it in action, it can be done. It’s indeed amazing when it works and lately more and more companies are adopting it.
Drawbacks
The old adage of “there’s no such thing as a free lunch” certainly applies here, as well. I’ve talked about a lot of pros, but there are some cons which you need to think about.
Given that everyone is working in the same place, and everything is interconnected, tests become the blood of the whole system. Trying to make a change that impacts potentially thousands of lines of code (or more) without the safety net of automated tests is simply not possible.
Why is this any different from traditional ways of storing code? I’d say that versioned modules hide this particular problem, at the expense of creating technical debt. If you own a module that depends on another team’s code, by way of a strict version number, then you’re in charge of upgrading it. If you don’t have sufficient test coverage, you’ll err on the side of caution and simply delay upgrading until you’re confident the module doesn’t affect your own project. As we’ve discussed earlier, this has a serious long term consequences, but it’s a viable strategy nonetheless. Especially if your business doesn’t actually promote long term projects.
We mentioned the benefit of every contributor being able to access all of the source code in your organization. If we flip that around, this can also be a problem for some types of work. There’s no easy way you can restrict access to projects. This is important if you consider government or military contracts as they typically have strict security requirements.
Finally let’s consider continuous integration. You may be using a system such as Jenkins, Travis, or CircleCI, to manage the way your code is tested and delivered to customers. When you have more than one repository you typically set up one pipeline for each. Some teams even go further and have one dedicated CI instance per project. This is a flexible system that can adapt to the needs of each team. Your billing team may deploy to production once a week, while your web team would move faster and deploy multiple times a day.
If you’re considering moving to a monorepo, be wary of your CI system’s capabilities. It will have to do a lot of work. Simple tasks such as checking out the code, or building an artifact may become long running tasks which impact productivity. Google developed and runs its own custom CI solution, and for good reason. Nothing available on the market was good enough.
Now before you conclude that this is a blocker, I’d recommend you carefully analyse your project and the tools you use. If you’re using git, for example, there’s a myth going around that it can’t handle big repositories. This is demonstrably inaccurate, as best exemplified by the project that inspired git in the first place, the Linux Kernel.
Make your own research and see how many files and lines of code you have, and try to predict how much your project will grow. If you’re nowhere near the scale of the Kernel, then you’re OK. You could also make the point that git isn’t very good at storing binaries. LFS aims to solve that. You can also rewrite your history to delete old binaries in order to optimize performance.
In a similar vein, open-source CI systems are much more powerful than you think. Jenkins for example can scale to hundreds of jobs, dozens of workers, and can serve the needs of a large team with ease. Can it do Google scale? Absolutely not! But do you have tens of thousands of engineers pushing to production every day? The plateau at which these tools stop performing is so high, it’s not worth thinking about until you’re close to it. And chances are, you’ll know when you’re getting close.
And finally, there’s cost. You’ll need at least one dedicated team to pull this off. Because the amount of work is certainly not trivial, and it demands passion and focus. This team will need to, and I’m just summarizing here, build and maintain in perpetuity what is essentially a platform that stores code, assets, build artifacts, reusable development infrastructure for running tests or static analysis, and a CI system able to withstand large workloads and traffic. If this sounds scary, it’s because it is. But you’ll have no problems convincing developers to join such a team, it’s the type of experience that’s hard to accumulate by doing side-projects at home.
In closing
I’ve talked about the many advantages of working in a monorepo, the drawbacks, and touched upon the costs. This setup is not for everyone. I wouldn’t encourage you to try it out without first evaluating exactly what your problems and your business requirements look like. And of course, do go through all of the possible alternatives before deciding.