
By Jeff M Lowery
You can apply similar rules to data object types, too.
You probably learned the term Normal Form in the context of defining schemas for relational databases. Database normalization strives to reduce data redundancy in table rows and columns. Consequently, data anomalies are less likely to occur.
What’s a data anomaly?
Suppose we had this situation:
Table A contains values for properties X, Y, Z for a row identified by the id of x; these are assertions about x. Let’s say Y in row x is asserted to be the value 3.
Table B also contains the same assertions about why Y for x
Table A is told later, “Facts have changed. Y is now 4”
Table B is later queried, and says Y is still 3.
Now A and B assert two different facts about Y, depending on which table you query.
That’s a data anomaly: two different assertions about a fact. And facts do matter in computer systems.
The what and whyfors of Normal Forms
I’ll use the term type to denote the meta data of an object. This could be implemented by a class definition, mixin, trait, stamp, or whatever mechanism your preference and language of choice supports. I’ll also be focusing on data objects, such as POJOs, PODOs, JSON and similar simple objects.
Stated informally, the first three normal forms are described as follows:
First Normal Form (1NF): No repeating elements or groups of elements
Second Normal Form (2NF): All Non-key Attributes are Dependent on All of Key
Third Normal Form (3NF): No dependencies on non-key attributes
That’s pretty dry reading. But applying these principles to object type definitions is actually pretty intuitive. Once you’ve internalized these rules, you won’t even think about them consciously again.
Objects are relational, too
Relational databases support associations by way of Primary and Foreign Key constraints. Hierarchies are implicit, if they exist at all. Associations are looser than hierarchies and taxonomies, but also harder to think about.
In a hierarchy, you have parent-child relationships. There is often a hierarchy of data types as well (class-subclass) which is also modeled. Relationships in a object containment hierarchy are more constrained, generally one-way (parent to child), but also easier to grasp than a more general (and flexible) association.
1NF: No repeating elements or groups of elements
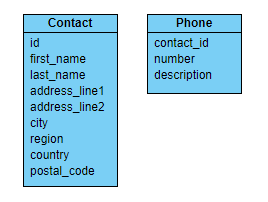
Say we have the following contact information:

Where are the repeating elements?
- Name attributes: this could be considered a one-to-many relationship, where the number of names is indeterminate (such as British royalty). In practice, though, first, last, and possibly middle name are sufficient for most application domains, so there’s no real need to normalize these fields.
- phones: The repetition of phone attributes does look like a potential problem: is two phones enough? And what if further information is later associated with the phone number, like time available?
- address lines: again, are two enough? In some countries, street addresses can be four lines long, but that’s the limit. Since they are simple strings, it’s no tragedy if one or two more address lines are added later.
Here’s a possible model, with Contact and Phone types:
2NF: All Non-key Attributes are Dependent on All of Key
What does this mean in plain English? In a database, it means that all columns in a row should be directly dependent on any candidate keys of that row.
So let’s take a look at Contact again:

Here the key is a generated id value, sometimes referred to as a surrogate key. Are the address attributes dependent on Contact ID? Well…
It all depends on the domain.
The six address properties are surely not attributes of the Contact, but are rather means of identifying a physical location. It is possible a contact could have many addresses, and perhaps an address has many contacts.
Should this be modeled as a many-to-many relationship, with some ContactAddress object type that has a Contact ID and an Address ID? It is going to depend on what is important to your application domain. Some application may treat Contacts as strong entities, independent of Address, but Addresses as weak entities, dependent on a Contact for existence. In that case, one contact can have many addresses, and each address refers to a contact, like this:
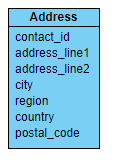
There is a potential data anomaly: if you change the address for one contact, you don’t change that same address for all contacts. If Contact is your primary source of reference, then that may be the desired behavior: your contact moves (to another organization, say) and the remaining Contacts stay in place.
3NF: No dependencies on non-key attributes
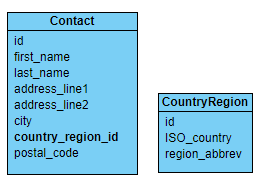
Looking at Address again, you might spot the two dependent fields, region and country. A country may or may not have regions, but a region does have a country: you don’t want to mix them up.
One way of ensuring that the region belongs to the correct country is to create an identifier for each (country, region) pair, then have the address refer to the identifier rather than to region and country independently:
A word about generated identifiers
In my opinion, generated identifiers are an implementation detail, and are really only needed by client code when modifying or deleting a back-end record (such as a row in a database), but never as part of a read-only query. They should also never be seen by the user of the system, because they are meaningless.
Table per Type, Table per Type Hierarchy
The neat thing about normalized object types is that they map easily to relational database tables. For a relational database implementation, tables mirror the object types (Table per Type) or at least contain information for multiple types derived from a base type (Table per Type Hierarchy). This may sound like I’m advocating Object-Relational Mapping, but no… I am merely saying that it is beneficial to have your Logical Model share the same characteristics of the Physical Model at a conceptual level. Implementation is another subject entirely.
References
There are ample resources about normalization of relation database schemas:
Database Normalization: First, Second, and Third Normal Forms - Andrew Rollins
I read a great explanation of first, second, and third normal form a few weeks ago. For those that know what database…
www.andrewrollins.com
Database Second Normal Form Explained in Simple English
The second post focused on the first normal form , its definition, and examples to hammer it home. Now it is time to…
www.essentialsql.com
What is Second Normal Form (2NF)? - Definition from Techopedia
Second Normal Form 2NF Definition - Second normal form (2NF) is the second step in normalizing a database. 2NF builds…
www.techopedia.com
Database Third Normal Form Explained in Simple English
The third post focused on the second normal form, its definition, and examples to hammer it home. Once a table is in…
www.essentialsql.com
Also, when researching this post, I came across a somewhat different take on how to apply normalization rules to object types.