
By Drew Dahlman
Managing content can be a pain. Still, mentions of WordPress often bring about moans from some developers. Surely in 2018 there’s a better way.
Well, let’s make a headless CMS and publish static JSON that can be consumed by a serverless app — or rendered server side with caching for ultimate speed! Bonus for taking this approach: we can reduce security issues as well as use the data from our CMS in multiple places. And we never have to deal with server loads, because everything is coming from AWS S3.
Yes, WordPress has an API you can use. But the goal here is to avoid ever interfacing directly with WordPress in your apps, keep everything static.
For this post I’ve created a repo that comes packaged with everything we will go over here, but this post will explain what’s going on and how you could roll your own version of the uploader and parser.
Project repo: https://github.com/DrewDahlman/headless-wordpress
Plugin: https://github.com/DrewDahlman/wp-headless
Intro
All right — now let’s talk a bit about the goals of this project.
Security: Since we wont be using WordPress in the traditional sense we can hide the whole thing in some authentication or even just keep the project along with database dumps on github and when changes are needed you could spin the project up locally and publish.
Speed: Since we’re publishing static files to s3 the only time we have load on our database is when publishing content and making changes, by doing this our app will just be making one request, or we could split it out and load as we need which will always make an app faster.
Another way we could speed things up is to do serverside rendering and cache our data file which again increases our speed of delivery.
Cool, let’s make a headless WordPress.
Note that the example project comes with a database file that will automatically setup all of the following things for you, but feel free to toy around with it. You will however need to provide your own AWS credentials in order for uploads to work.
Setup
The first thing we want to do is spin up our WordPress instance. For this I am using the example repo but you could do this on your own. Once we’re running we will want to install our plugins. For this example I am using:
Advanced Custom Fields Pro
Custom Post Types
Amazon Web Services
Amazon s3 and Cloudfront
WP Headless
With just these plugins we’re ready to roll.
The first thing we want to do is setup aws and our s3 bucket. Go to the AWS settings page and put in your credentials.
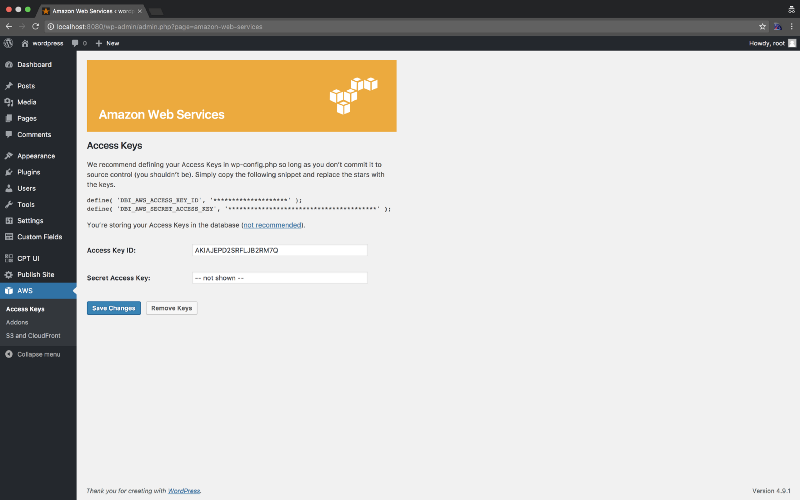
After that’s ready to roll, let’s setup our bucket.
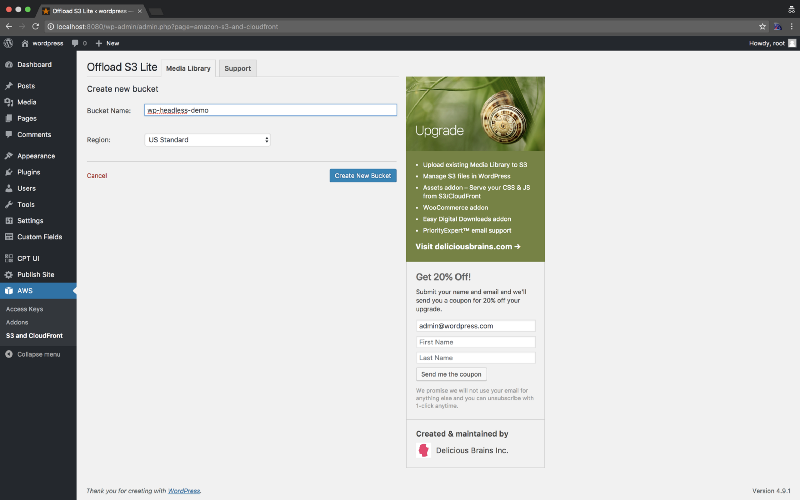
Once that’s set let’s setup some post types and some custom fields. For this example, let’s make a custom post type of TV shows.
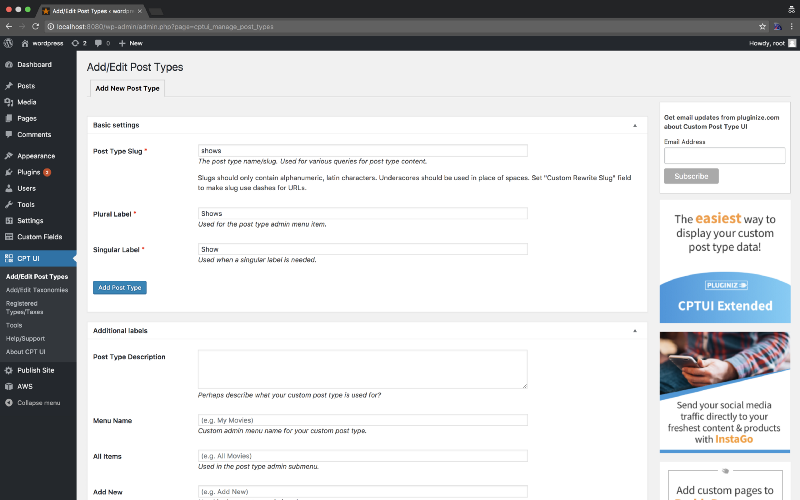
Cool now let’s make some custom field: Name, Cover, About, and a repeater of characters with name, and photo.
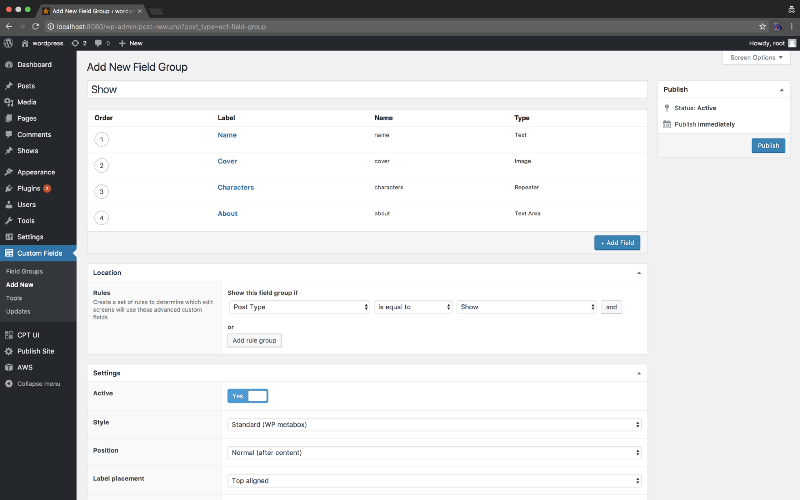
All right — now that we’ve got our fields and post types set up, the next thing to do is enter some content.
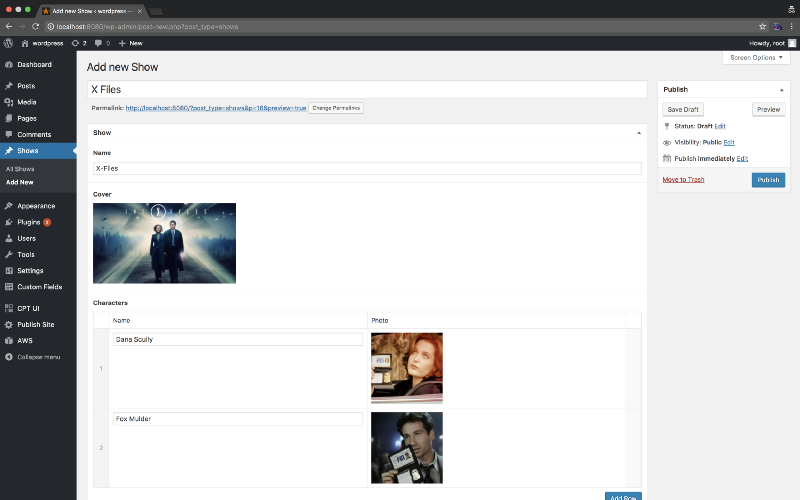
So with a post created, now let’s actually publish and see how this works. In the “Publish Site” plugin there is a content page where we can configure the files we will be publishing and how they are structured.
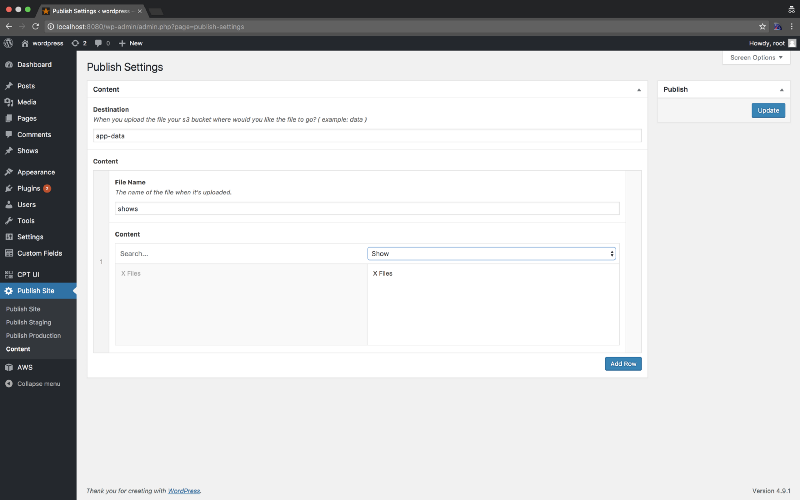
Setting up the content on where the files should be uploaded in the bucket we setup earlier, and then giving a name to our data file as well as selecting the posts, pages, media we want.
After that it’s as easy as saving and clicking “Publish Staging” or “Publish Production”.
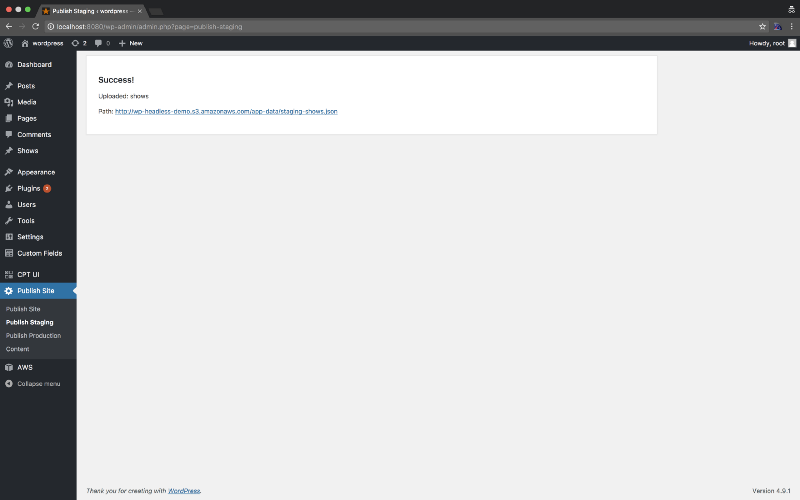
Boom! Success! You should see something like this.
So let’s check out the data.
This is a simple example, but you could for your projects have even more data. Notice a few neat things happening here. We get the raw WordPress data about the slug and such, but we also get all of our ACF fields as well as image objects and if we wanted related posts, or galleries — whatever you want to create!
How does this work?
The Code
Cool, so now we have this all working. But how does it work? And how can you create something similar with your own modifications for publishing? Sometimes you might not want any of the raw WordPress data, maybe just a slug and an ID.
Let’s check out the wp-headless plugin. I made this as a plugin because it’s easier to manage lifecycle hooks but also keeping with the idea that we can keep everything living on it’s own. Maybe you do want to still use the traditional theme but also have this as an option.
DrewDahlman/wp-headless
_wp-headless - A simple plugin for publishing static JSON files from Wordpress for a headless CMS._github.com
Checking out the code, it’s all pretty straight forward. The plugin is nice because it checks for dependencies and sets up the initial publish page with the essentials to make it easier. You could totally roll your own version of this if you wanted to other options or more refined options.
A neat thing here too is setting the environments, so we can have a staging-FILENAME.json and production-FILENAME.json.
Where things get interesting is around line 134 where we have a recursive function that parses a post.
This is called by our publish function that loops over the content field in our Publish Site settings page.
By looping over each of our potential content buckets — as well as the posts inside of those — we call parse post which loops over each field from WordPress and then checks for ACF fields we may have.
This has the ability to go one level deep in terms of relationship fields. (This is mostly due to the fact that a related post may reference this post which would go on forever nesting and relating.)
Some other things here: we’re generating a random name for our file and saving it locally before uploading. If it succeeds we delete the random directory and file and the site is published.
The uploader is straight forward as well, it uses the AWS plugins we setup before for determining the destination bucket. Note that you could absolutely add multi language to these publishes as well by adding in a param to check WPML if you’re using that and adding something staging-es-FILENAME.json or something.
The uploader gets the filename, a temp file and the final destination. This checks with our plugins and uploads to S3.
Now that this is all setup and working you can consume that s3 file anywhere! Ways I have used this setup have been putting a WordPress install on a server under a subdomain with authentication before login such as https://admin.example.com. This again keeps the WordPress hidden from the world at large and adds a layer of security to your application.
You could even have another app living on your server that consumed from S3 and renders serverside. The benefits of all of this is better security, more options for consuming the content, and lower server loads.
Another option you can take is to do a database dump after making edits and save that in a GitHub repo and allow team members to pull down spin up the site make changes and publish. Again, keeping things secure without worry of any vulnerabilities.
Again check out the plugin on Github and the example project to see how this works!
DrewDahlman/wp-headless
_wp-headless - A simple plugin for publishing static JSON files from Wordpress for a headless CMS._github.com