
By Marius Lazar
In today’s world, continuous integration and deployment (CI & CD) is a very common practice and an important part in any application life cycle. If you want to avoid spending valuable time on tasks that you can actually automate, keep on reading.
In this tutorial, I’m going to walk you through the steps we have followed to integrate a CI & CD pipeline in the development process of one of our Angular apps using CircleCI 2.0 and AWS S3.
Requirements
Before you start this tutorial, I assume you have the following:
- A CircleCI account
- An AWS account with rights to create new users
- An AWS S3 Bucket
- A Bitbucket or Github repository with your project
- A cup of coffee — you know… keeps you warm and focused :)
Setting up CircleCI
Let’s get to work. For setting up CircleCI, you need to create a new folder in your project root called .circleci (notice the dot) and add a config.yml file to it. Leave it empty for a second.
Go to the CircleCI interface and add your project by going to Projects tab > Add Project . CircleCI should have already found all your public repos. Select your project and press the Setup project button.
Select the options that fit you best (Linux/Platform 2.0/Node in our case), copy the sample config generated down on the page into your own config file, and push the changes to your repo. Now you can press the Start building button.
You can find a gist with the final configuration here.
Understanding the CircleCI configuration file
The bread and butter of this tutorial is to understand how to make use of the CircleCI config file. It has 3 main components: a version, a list of jobs, and a list of workflows.
The version is pretty obvious. It’s the CircleCI version that we are going to use.
Then we have the list of jobs. You can think of a job like an independent environment for running a list of commands or steps. Common things that you can achieve within a job include:
- Installing the tools you need to run/build/test your project
- Executing bash commands
- Storing or restoring items from the CircleCI cache
Then we have the list of workflows. A workflow is a way to manage your jobs. Let’s say you need a job to run only on specific branches or at specific times, or you want some of the jobs to run in parallel and some in sequence. That’s what workflows are for.
A basic CircleCI config structure:
In our case we have two jobs: the build job and the deploy job. I will describe each of them in the following sections, but for now, let’s see what attributes we are going to use for each of the jobs:
- The docker attribute — specify a Docker image used to create the container of the environment. CircleCI comes with a list of pre-built images that you can find here
- The working_directory attribute— the current directory which will be the place where all the steps will run
- The steps attribute — a list of steps (commands) that you want to run in the current job
There are a few types of steps that we are going to use in our configuration:
- The checkout step — used to checkout the code from the current branch into the working directory
- The run step — used to execute a bash command. You can specify a descriptive name which you are going to see in the CircleCI interface
- The save_cache step — used to store a cache of a file or a directory in the CircleCI storage. A common use case is to install the npm dependencies only once and then cache the _nodemodules folder using a hash of the package.json file as the cache key
- The restore_cache step — used to restore a cached item using the cache key
Each job has access to some predefined environment variables. You can check the full list here. You can also set up environment variables from the CircleCI interface or as a job attribute, but in this tutorial we are only going to use the following environment variables:
- CIRCLE_BRANCH — represents the current branch
- CIRCLE_SHA1 — represents a hash of the current commit
Configuring the CI pipeline
The CI pipeline will be responsible for building, linting, and testing the source code. All three processes will be aggregated into a single job called the build job.
You can have a quick look at the final build job below, but I’m going to take each step separately so we can learn a bit more about what’s happening there.
- We start by checking out the code from the current branch
# Checkout the code from the branch into the working_directory- checkout
- We log the current branch for debugging purposes
# Log the current branch- run: name: Show current branch command: echo ${CIRCLE_BRANCH}
- We restore the _nodemodules folder from the cache if it exists. You can have a peak at step 5 to see how it was saved.
# Restore local dependencies from cache- restore_cache: keys: - v1-dependencies-{{ checksum "package.json" }} - v1-dependencies-
You notice that we are using two cache keys. A key is a pattern to search for a cached item. The first one is specific to the current package.json file and the second one is more generic and matches all previously cached _nodemodules folders.
In case the very specific cache doesn’t exist, we are going to look for any previously cached _nodemodules folder and restore that instead. This is useful when only some of our dependencies have been updated, because we don’t need to download and install the whole list of dependencies. We are only going to do that for the updated packages and restore the unchanged ones from the cache.
- We install the project dependencies. If those dependencies have already been restored from the cache, this step will be very quick. Otherwise it can take up to a few minutes. That’s why caching is important. Saves you time and money.
# Install project dependencies- run: name: Install local dependencies command: npm install
- We cache the _nodemodules folder in case it doesn’t exist. Keep in mind that a cache is immutable, so it will not be overwritten if it already exists.
# Cache local dependencies if they don't exist- save_cache: key: v1-dependencies-{{ checksum "package.json" }} paths: - node_modules
A new cache will be generated with the folders/files specified in the paths attribute every time something is changed in the package.json file. The key of the cache is generated using the checksum function, which will output a base64 encoded hash of the package.json file’s content.
One commonly used technique is to prefix your cache key with a version number, so whenever you want to regenerate your caches, you can just change the version number.
- We run the lint and test commands. It’s probably worth noticing that if any of the steps fail, the whole build will fail.
# Lint the source code- run: name: Linting command: npm run lint
# Test the source code- run: name: Testing command: npm run test
- We run the build command. Notice that we are going to use a multi-line command with each line running in the same shell, so we start the command with the pipe (|) character.
We check the current branch name and run the corresponding npm script to build the project. We do this because we have different configurations based on the environment. The resulting files will be saved into the dist folder.
# Build project with different configuration based on# the current branch- run: name: Building command: | if [ "${CIRCLE_BRANCH}" == "staging" ]; then npm run build-qa elif [ "${CIRCLE_BRANCH}" == "master" ]; then npm run build-prod else npm run build-dev fi
- Finally, we save the dist folder into the cache so we can restore it later in the deploy job. We are using both CIRCLE_BRANCH and CIRCLE_SHA1 environment variables to generate a unique cache key which doesn’t already exists in the cache.
Notice that we are not in a shell command, so we need to take those variables from the .Environment variable.
# Cache the dist folder for the deploy job- save_cache: key: v1-dist-{{ .Environment.CIRCLE_BRANCH }}-{{ .Environment.CIRCLE_SHA1 }} paths: - dist
As a side note, we first tried installing angular-cli globally and cached it for later use, but it would take up to 30s to finish the installation even when it was cached. So we decided to create a few npm scripts to run ng commands using the local angular-cli.
"scripts": { "ng": "ng", "start": "ng serve --env=local", "build": "ng build", "test": "ng test", "lint": "ng lint", "e2e": "ng e2e", "build-dev": "ng build --target=development --environment=dev", "build-qa": "ng build --target=production --environment=qa", "build-prod": "ng build --prod"}
And that’s it! We now have a working CI pipeline. You should be able to save this into your own config file, push it to your repo, and check if everything is working as you expect.
In case you are wondering, you don’t need any workflow in place to run a job. By default, each job will fire when you push a change.
Configuring the CD pipeline
The CD pipeline will be responsible for deploying the distribution files resulting from the build job to an AWS S3 bucket. Guess what? We are going to call this the deploy job.
Before we can continue, we have to give CircleCI permissions to access the AWS S3 Bucket.
First, we are going to create a new IAM user in the AWS Management Console. Go to Services > IAM > Users > Add User . Give it a name and select the Programmatic access box for the Access type.
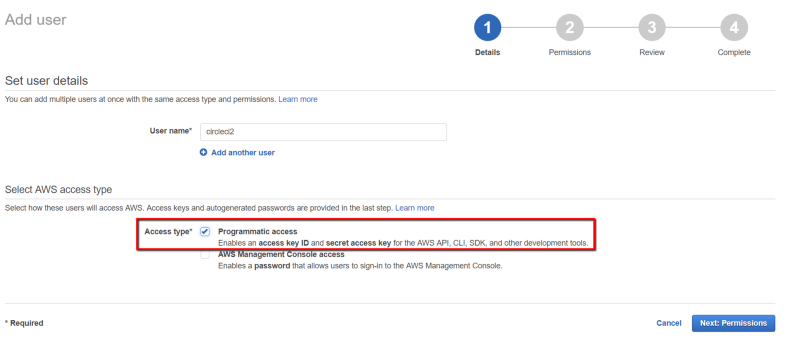 Setting programmatic access for a new user
Setting programmatic access for a new user
Go Next . We now have to go give the user some permissions. In our case, we only need the circleci user to be able to Read/Write an AWS S3 Bucket. Find and select the AmazonS3FullAccess policy, then press theCreate user button.
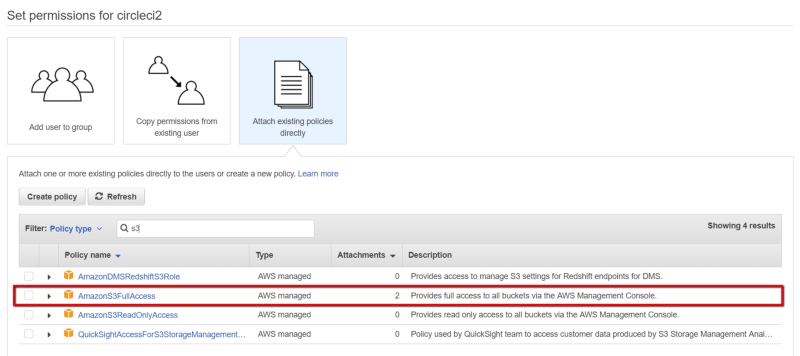 Select user’s permissions
Select user’s permissions
On the next page, you will have an Access key ID and a Secret access key for the new user. Keep this page open and go to the CircleCI interface. Get into the project settings and search for AWS Permissions. You will need to use the previously generated keys in here.
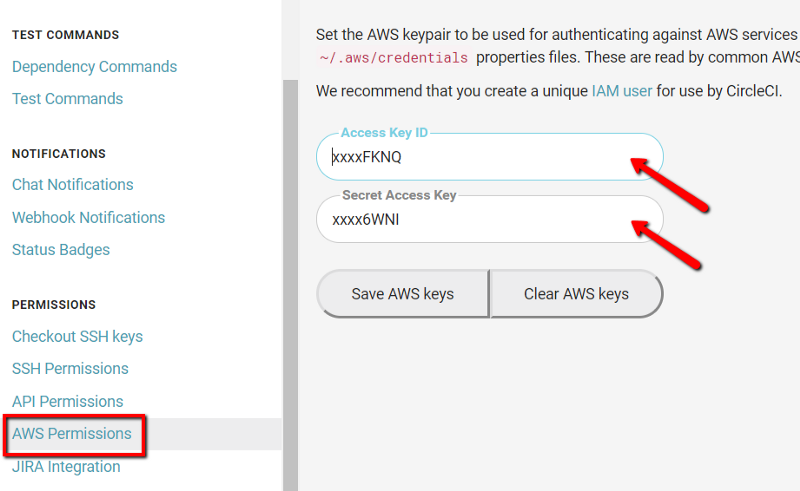 Setting the AWS Permissions of a CircleCI project
Setting the AWS Permissions of a CircleCI project
Once you’ve done that, we can continue with our deploy job.
Same as previously, you have the final deploy job below. But I’m going to discuss each step separately, even though they are pretty straight-forward this time.
- We start by logging the branch name for debugging purposes.
# Log the current branch- run: name: Show current branch command: echo ${CIRCLE_BRANCH}
- We restore the cached dist folder saved on the build job.
# Restore cache from the build job which contains the# dist folder that needs to be deployed- restore_cache: key: v1-dist-{{ .Environment.CIRCLE_BRANCH }}-{{ .Environment.CIRCLE_SHA1 }}
- We install the aws cli using sudo rights.
# Install AWS cli- run: name: Install aws cli command: sudo apt-get -y -qq install awscli
- We run the deploy command which is going to deploy the code from the dist folder to the AWS S3 Bucket corresponding to the current environment. We have again a multi-line command, so we need to start with the pipe (|) character.
# Deploy to the S3 bucket corresponding to the current branch- run: name: Deploy to S3 command: | if [ "${CIRCLE_BRANCH}" == "develop" ]; then aws s3 sync dist s3://project-dev/ --delete elif [ "${CIRCLE_BRANCH}" == "staging" ]; then aws s3 sync dist s3://project-qa/ --delete elif [ "${CIRCLE_BRANCH}" == "master" ]; then aws s3 sync dist s3://project/ --delete fi
The signature for deploying to an AWS S3 Bucket using the aws cli is as follows:
aws s3 sync <% path-to-folder %> s3://<% bucket-name %>/ --delete
The delete flag will clear the bucket before deploying any files.
One more thing. Or maybe two… We have encountered 2 errors after we had this configuration in place. Maybe they are not applicable in your case, but I will still give you a short summary.
- The region of the S3 Bucket was not specified.
A client error (PermanentRedirect) occurred when calling the ListObjects operation: The bucket you are attempting to access must be addressed using the specified endpoint. Please send all future requests to this endpoint.
To solve this error, we had to add the bucket region to the deploy command:
aws --region eu-west-2 s3 sync <% path %> s3://<% bucket-name %>/
- The authorization to the S3 Bucket was using an old protocol which is not supported by the current bucket.
A client error (InvalidRequest) occurred when calling the ListObjects operation: The authorization mechanism you have provided is not supported. Please use AWS4-HMAC-SHA256.
To solve this error, we had to set the authorization mechanism for authenticating an AWS S3 Request to use the Signature Version 4 before running the deploy step:
# Set the signature version for the S3 auth- run: name: Setting Signature Version 4 for S3 Request Authentication command: aws configure set default.s3.signature_version s3v4
That’s it! We now have a working CD pipeline. Only one small problem… It will run on every push. So let’s configure a workflow to solve this.
Putting the CI & CD jobs into a workflow
In our case, we want to run the build job on every commit and the deploy job only when we commit to develop, staging, or the master branch. A workflow, by default, is triggered by pushing to any branch.
We actually wanted the build job to run only when we make a Pull Request (PR), and this is possible by going into the Advance Settings of your CircleCI project and turning on the Only build pull requests option.
But the problem comes when you need to run the workflow on PR and also on develop, staging, and master branches. We couldn’t find how to make this work. But if you have any suggestions, please leave me a comment!
Back to our workflow config. It is pretty self-explanatory:
You can see that we have defined the build_and_deploy workflow which contains… the build and deploy jobs. The build job has no restrictions, so it will run whenever the workflow runs.
On the other hand, the deploy job has a require property for the build job which means that it will only run if the build job is successful. It also has a filter attribute which is used to select the branches that it will run on.
With this configuration in place, we have limited the execution of the deploy job to the develop, staging, and master branches only when the build job is successful, which is exactly what we wanted.
That’s pretty much it. A gist with the entire configuration can be found here.
Bonus feature
If you are like us and you would like know what’s happening with your project, you will be glad to hear that there is a CircleCI app for Slack which can be configure to give you real time alerts when a build succeeds or fails. It’s nice to have.
Final thoughts
I know it can be intimidating, but don’t be afraid to integrate a CI & CD pipeline into your project. It will take a bit of time until you get the configuration right, but it’s worth it!
If you think this article was helpful for you, please recommend and share!
Thanks for reading! If you have any comments or questions, please reach out to me! I’m always glad to help :)