
By Grant Bartel
In this lesson, we’ll explore a popular algorithm called minimax. We’ll also learn some of its friendly neighborhood add-on features like heuristic scores, iterative deepening, and alpha-beta pruning. Using these techniques, we can create a more flexible and powerful game playing agent. It’ll be able to compete in many challenges, including the strategy game Isolation.
In my previous post How To Win Sudoku, we learned how to teach computers to solve the puzzle Sudoku. If you haven’t read it, go ahead and give it a quick read. But that was really just a way to get our feet wet, before diving into more sophisticated methods of game playing agents. Especially those methods that can make strategic moves against an opponent!

Don’t Get Stranded
Isolation (or Isola) is a turn-based strategy board game where two players try to confine their opponent on a 7x7 checker-like board. Eventually, they can no longer make a move (thus isolating them).
Each player has one piece, which they can move around like a queen in chess — up-down, left-right, and diagonal. There are three conditions under which the pieces can be moved —
- They cannot place their piece on an already visited square.
- They cannot cross over already visited squares (squeezing through them diagonally is OK).
- They cannot cross over each other’s piece.
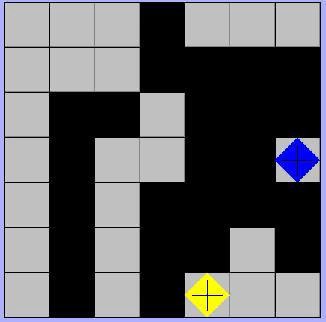
In the above picture, you can see from the black squares that both players have placed their pieces on various parts of the board. But as the game progressed, it shows that the yellow player still has three possible moves. Up and to the right, right one square, and right two squares. But the blue player is out of options. Hence, the yellow player is the winner here.
Now this may seem like a simple game — and to be honest, it is. It’s not like we’re playing poker or Starcraft. Yet, there is still an enormous amount of possible moves either player can make at any point during the game.
In puzzles like Sudoku, there’s an “answer” which we want to solve for. But there is no answer when it comes to strategy games.
We’re playing against another opponent — like a person, computer, or a cat detective. This requires strategy and some thought into how the game may turn out as it rolls along.
Such games can evolve and produce an absurd amount of possible outcomes. So we need to think of how we can choose the best possible move, without spending the amount of time it took for cats to populate the Earth.

Okay, no more cats!
Mighty Minimax And Friends
Now that you know how to play Isolation, let’s take a look at how we can use the minimax algorithm; a staple in the AI community. We’ll also look at heuristic scores, iterative deepening, and alpha-beta pruning. Together with these, we can build a competitive AI agent.
Minimax
The minimax algorithm is very popular for teaching AI agents how to play turn-based strategy games. The reason being is that it takes into account all the possible moves that players can take at any given time during the game. With this information, it then attempts to minimize the opponent player’s advantage while maximizing the agent’s at every turn the AI agent gets to play.
Now, how does this look?
Well, similar to how an AI agent would play a game like Sudoku, we can model the next possible moves either player can make via a search tree. However, we’ll need to use a search tree with variable breadths — or in other words, a tree level’s width. The reason being is that there are a variable number of moves each player can make at any given time during the game.
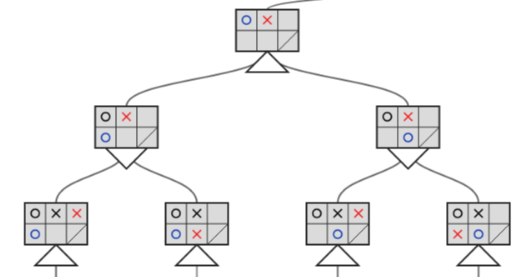
The tree shown above represents the next moves available during a game of Isolation. It has a 2x3 grid, with the bottom right square being unreachable. As you can see, the two players are a blue circle and a red cross.
The top of the tree (the root node) illustrates a move made by the red player. The middle level illustrates the next possible moves by the blue player. And the third level illustrates the possible moves by the red player, given the previous move made by the blue player.
Each game state or node in the tree has information about which player has the most to gain from any potential move.
Now you might be wondering, what the heck are those triangles below each move?
The downward triangle represents a location in the tree where minimax will minimize the opponent’s advantage. Whereas, the upward triangles are the locations where minimax maximizes the agent’s advantage.
But minimax can only know either players’ advantage if it knows the paths in the tree that lead to a victory for either player. This means minimax must traverse to the very bottom of the tree for every possible series of moves. Next, it has to assign some score (e.g., +1 for a win and -1 for a loss), and propagate those numbers up through the tree. This way, each game state or node in the tree has information about which player has the most to gain from any potential move.
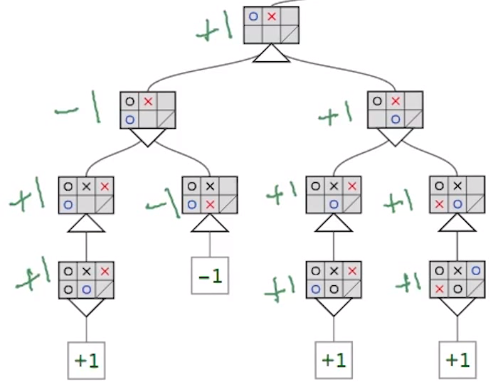
In this picture, we can make a couple of observations. First minimax assigns a number to the final game outcomes at the leaf nodes. Then it propagates them upward through the tree, performing minimizations and maximizations on the way. Once minimax finishes filling in the tree, whenever it’s the AI agent’s turn, it’ll know which moves will likely lead to a win or loss.
The second level after the root node shows the next possible moves for the blue player (our AI agent). Our agent wants to maximize the available scores during its turn. So it would choose the move represented in the right-most node following the root node. Super cool!
But does it make sense to simply assign a +1 or -1 to game outcomes? Shouldn’t this score take into consideration how the game is won or lost?
Spoiler alert: the answer is yes!
Heuristic Scores
In the world of strategy games, a heuristic score is essentially a subjective value we assign to some game state. This value is based on our understanding of how the game is won and lost. By choosing a well-thought-out heuristic score, we’re able to teach our AI agent how to best select its next moves while playing the game Isolation.
Now there’s probably an unlimited number of heuristic scores we could come up with. But here we’ll only look at a few of them, apart from the naïve score (NS) of +1 and -1.
One idea could be to count all the next possible moves each player has at any given time, since more possible moves mean less chance of being isolated. We’ll call this the open move score (OMS).
Another idea could be to use the value obtained from OMS and subtracting the number of next possible moves the opponent has. The reason being that each player wants to increase their amount of moves while decreasing their opponent’s. We’ll call this the improved score (IS).
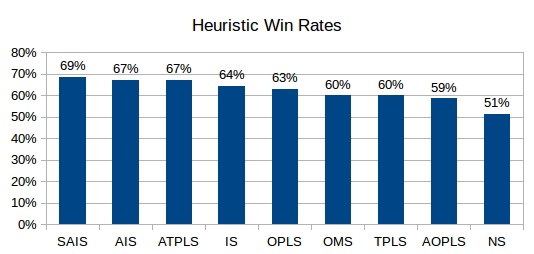
The above figure shows the win rates over many simulated isolation games played between AI agents using different heuristic scores. Now you can see how different our scores did during actual game play. But there were some heuristic scores that outperformed the ones we came up with
Interestingly, the top two are almost exactly the same as improved score. We’ll call them aggressive improved score (AIS) and super aggressive improved score (SAIS). But there’s a slight difference between these scores and the original. The top two scores apply a factor of two and three to the value you subtract with (the number of moves available to the opponent) when computing the improved score.
You can discover an optimal “aggressive factor” to apply when computing this score!
Another spoiler alert — better values exist.
But what if we come up with a heuristic score that takes a lot of time to compute? What if the tree is huge? Will our AI agent have enough time to find its next best moves, while still being responsive enough during game play?
Iterative Deepening
Now we know that our AI agent can model all possible moves using a search tree and its nodes’ corresponding heuristic score. But unfortunately, when playing Isolation our tree will be massive. It would take more time to search the tree and compute these values than there are years since the big bang!

Enter iterative deepening — the go-to time management strategy for game playing agents. By using this method, we can cut the compute and search time down to a maximum time of our choosing. This way our AI agent can respond at least as fast as a human could.
But how does iterative deepening work?
It allows minimax to move level by level and compute heuristic scores until a certain time limit. Once this time limit is reached, the AI agent is forced to use the best move it discovered while having moved deeper and deeper down the tree.
Now this provides some insight into how difficult it can be. Creating an AI agent that is smart and responsive enough for strategy games, can be quite tricky, even for AI wizards. Especially if such games contain a world of possibilities.
Unfortunately, the number of moves the AI agent can “imagine” going forward is limited. So it’s possible it could make a decision that leads to its demise. This is a well-known phenomenon called the horizon effect. But we still need to look at arguably the most effective time slashing algorithm used when searching trees.
Alpha-Beta Pruning

Okay, those are raisins and not prunes, but still — how were these ever a thing? I mean, seriously, a raisin blues group?
You might have already guessed alpha-beta pruning has nothing to do with prunes, and more about reducing the size (pruning) of our search tree. When we have a very large search tree, it turns out that it’s not always necessary to traverse every node when using minimax.
We need to give minimax the ability to stop searching a particular region of the tree when it finds the guaranteed minimum or maximum of that particular level.
If we can do that, this can greatly reduce our AI agent’s response time and improve performance.
How does alpha-beta pruning work?
The minimax algorithm moves through the tree using depth-first search. Meaning it traverses through the tree going from left to right, and always going the deepest it can go. It then discovers values that must be assigned to nodes directly above it, without ever looking at other branches of the tree.
Alpha-beta pruning allows minimax to make just as good of decisions as minimax could do alone, but with a higher level of performance.
Consider the following image, in which we have a tree with various scores assigned to each node. Some nodes are shaded in red, indicating there’s no need to review them.
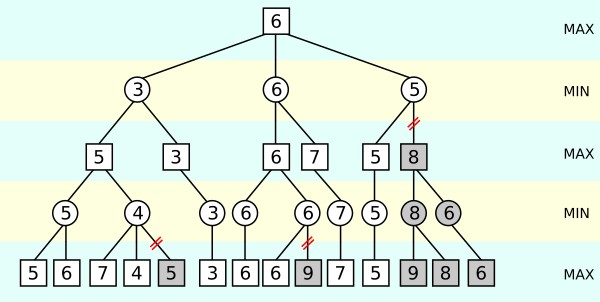
At the bottom left of the tree, minimax looks at the values 5 and 6 on the bottom max level. It determines that 5 must be assigned to the min level right above it. Makes sense.
But, after looking at 7 and 4 of the right max level branch, it realizes that the above min level node must be assigned a maximum value of 4. Since the second max level right above the first min level will take the maximum between 5 and at most 4, it’s clear that it’ll choose 5. Following this, it would continue traversing the tree to perform the same exact set of operations within the tree’s other branches.
Below is the algorithmic representation of minimax with alpha-beta pruning.

Using this method provides an easy way to cut down on our AI agent’s search space. This way, alpha-beta pruning allows minimax to make good decisions that minimax could do alone, but with a higher level of performance.
Isola-ter
We’ve explored how to build our own AI agent that can play the game Isolation at a fairly competitive level. By using the minmax algorithm, we saw how the AI agent can model the game and can make decisions based on a heuristic score. We also learned how to determine a well-defined heuristic for our given task (Isolation).
But we also discovered that it would be far too computationally intense to let minimax run wild. So we had to use techniques like iterative deepening and alpha-beta pruning. These would force our AI agent to come up with the next move within a reasonable amount of time. But what if we want our AI agent to have a higher win rate while at least being as responsive as a human?
Well, there are other techniques we could explore to increase our agent’s win rate as well as response time. We touched on the idea of tweaking our heuristic score’s parameters (remember the “aggressive factor”?). We could even come up with a heuristic score better tailored for playing Isolation.
There are also reflective properties related to the possible moves on the Isolation board. These become evident when we analyze the fully populated search tree, which would allow us to potentially slash a lot of branches from the search tree. Also, if we upgraded our hardware, our AI agent would be faster — and thus be able to explore more possibilities.
If you want to get into the nitty-gritty details of how to implement this yourself, take a look at the code I wrote to solve this problem for my Udacity Artificial Intelligence Nanodegree. You can find it on my GitHub repo.
I’m Grant and I’m a freelance SEO and content professional. If you’re looking to grow your brand's organic search traffic, I can help with your fintech SEO. Cheers!