
By Faith Oyama
Indexing in PostgreSQL is a process that involves creating data structures that are optimized to efficiently search and retrieve data from tables.
An index is a copy of a portion of a table, arranged in a way that enables PostgreSQL to quickly locate and retrieve rows that match a particular query condition.
When a query is executed, PostgreSQL looks at the indexes available to determine if any of them can be used in satisfying the query condition. If it finds a relevant index, PostgreSQL employs it to quickly identify the corresponding rows in the table. This results in significantly speedy queries, especially in situations where tables are large or the conditions are complex.
PostgreSQL provides support for several index types, including B-tree, hash, GiST, SP-GiST, and BRIN. Each index type is tailored to cater to distinct query types and data access patterns.
Apart from the standard index types, PostgreSQL permits users to define custom indexes utilizing user-defined functions.
It's important to note that creating an index requires additional disk space and can impact the performance of write operations, such as INSERT, UPDATE, and DELETE. Because of this, it's essential to consider the trade-offs and carefully choose which columns to index based on the queries you frequently execute and the access patterns of your data.
B-tree Index
B-tree index is the most commonly used type of index to efficiently store and retrieve data in PostgreSQL. It's the default index type. Whenever we use the CREATE INDEX command without specifying the type of index we want, PostgreSQL will create a B-tree index for the table or column.
A B-tree index is organized in a tree-like structure. The index starts with a root node, with pointers to child nodes. Each node in the tree typically contains multiple key-value pairs, where the keys are used for indexing, and the values point to the corresponding data in the table.
To create a B-tree index in PostgreSQL, use the CREATE INDEX statement. Here’s the syntax:
CREATE INDEX index_name ON table_name;
Single-column indexing
To create a single B-tree index based on one table column instead of creating an index on the entire table, the syntax is as follows.
CREATE INDEX index_name ON table_name (column_name);
index_name is the name you want to give to the index.
table_name is the name of the table on which you want to create the index.
column_name is the name of the column(s) on which you want to create the index.
Example:
Let’s create a table called “sales_info” and insert some dummy data.
CREATE TABLE sales_info (
sales_id integer NOT NULL, email VARCHAR,
location VARCHAR, item_purchased VARCHAR,
price VARCHAR
);
Insert values into the table using the INSERT statement:
INSERT INTO sales_info (
sales_id, email, location, item_purchased,
price
)
VALUES
(
1, 'halie46@gmail.com', 'London',
'Headphone', '$50'
),
(
2, 'romaine21@gmail.com', 'Australia',
'Webcam', '$50'
),
(
3, 'frederique19@gmail.com', 'Canada',
'iPhone 14 pro', '$1259'
),
(
4, 'kenton_macejkovic80@hotmail.com',
'London', 'Wireless Mouse', '$20'
),
(
5, 'alexis62@hotmail.com', 'Switzerland',
'Dell Charger', '$15'
),
(
6, 'concepcion_kiehn@hotmail.com',
'Canada', 'Longitech Keyboard',
'$499'
);
If we create a B-tree index on the sales_id column by running this statement:
CREATE INDEX idx_sales_id ON sales_info (sales_id);
When we run the SELECT statement, we get the total query runtime below.
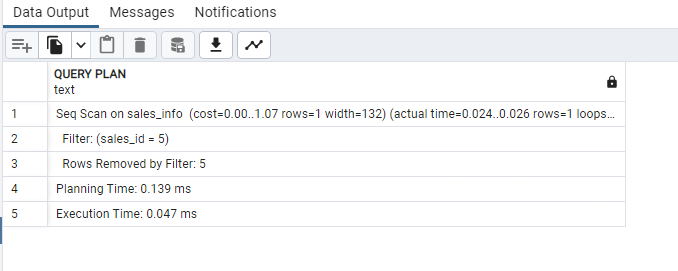
The time displayed might look insignificant, as the table we are working with is small. But when working with a large amount of data, this will significantly improve the performance of your queries.
To learn more about the B-Tree index and the behaviors of B-Tree operator classes, see the official documentation here.
Hash Indexes
Hash indexes are designed for fast key-value lookups. When a query condition requires equality checks on indexed columns, hash indexes can provide extremely fast retrieval, as the hash function directly determines the location of the desired data. Hash indexes are most suitable for equality comparisons, such as = or IN operations.
Like other index types, hash indexes need to be maintained during data modifications (inserts, updates, and deletes) to ensure data consistency. But hash index maintenance can be more expensive than B-tree indexes due to the need to resolve collisions and rehash data.
To create a hash index in PostgreSQL, you can use the CREATE INDEX statement with the USING HASH clause. For example:
CREATE INDEX hash_name ON table_name USING HASH (column_name);
This statement creates a hash index named "hash_name" on the specified column of the table.
Point to note here: while hash indexes are available in PostgreSQL, they are not suitable for range queries or sorting. B-tree indexes are typically preferred for such scenarios. Again, B-tree indexes are the default and commonly used index type.
Hash indexes have specific use cases and limitations, and it's essential to assess your requirements and query patterns before deciding on the appropriate index type for your PostgreSQL database.
Example:
Create a Hash index on the table sales_info using HASH for the column sales_id:
CREATE INDEX idx_sales_id ON sales_info USING HASH(sales_id);
Select and filter the data using the WHERE clause:
EXPLAIN (ANALYZE)
Select
*
from
sales_info
WHERE
sales_id = 5;
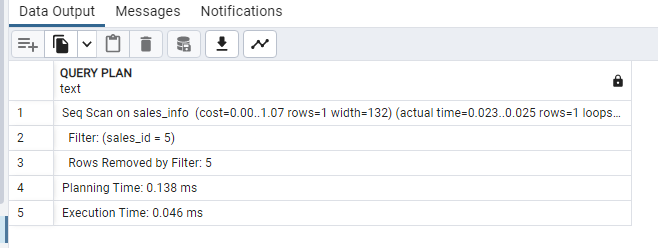
Check out the official documentation if you want to dive deeper into Hash Indexes.
GiST and SP-GiST Indexes
GiST (Generalized Search Tree) and SP-GiST (Space-Partitioned Generalized Search Tree) indexes are advanced index types in PostgreSQL that provide support for a wide range of data types and search operations.
They are particularly useful for handling complex data structures and spatial data, GiST indexes are what you use if you want to speed up full-text searches.
Creating GiST and SP-GiST Indexes:
To create a GiST or SP-GiST index in PostgreSQL, you can use the CREATE INDEX statement with the USING GIST or USING SPGIST clause, respectively.
Here's an example of creating a GiST index on a geometry column:
CREATE INDEX index_geometry ON table_name USING GIST (geometry_column);
And here's an example of creating an SP-GiST index on a tsvector column:
CREATE INDEX index_text_search ON table_name USING SPGIST (tsvector_column);
Here's an overview of GiST and SP-GiST indexes in PostgreSQL:
GiST Index:
- Generalized Search Tree (GiST) indexes are versatile index structures that support various data types beyond simple scalar values.
- GiST indexes enable efficient searching and retrieval for complex data structures such as geometric objects, text documents, arrays, and more.
- They are based on the concept of multidimensional trees, allowing for flexible search operations.
- GiST indexes can handle different search predicates, including equality, range, and spatial operations like overlaps, containment, and distance-based searches.
SP-GiST Index:
- Space-Partitioned Generalized Search Tree (SP-GiST) indexes are an extension of GiST indexes that further enhance indexing capabilities.
- SP-GiST indexes are designed for data types with space-filling characteristics, such as multi-dimensional data, time-series data, and network data.
- They partition the index space into non-overlapping regions, optimizing search performance for specific access patterns.
- SP-GiST indexes provide support for various data types, including geometric objects, text search, and more.
- They are particularly efficient for spatial indexing and can handle complex spatial queries, including intersection, nearest-neighbor, and clustering operations.
See the official documentation GiST and SP-GiST indexes for more information.
BRIN Indexes
BRIN, or Block Range Index, is an index type in PostgreSQL designed to provide efficient indexing for large tables with sorted data. BRIN index contains the minimum and maximum in a group of database pages.
BRIN index makes is the easiest way to optimize for speed. It is particularly useful for data that exhibits sequential or sorted characteristics, such as time series data or data with a natural ordering.
Here’s an overview of the BRIN Index:
- BRIN indexes divide the table into logical blocks and store summary information about each block.
- Each block contains a range of values, and the index stores the minimum and maximum values within each block.
- Instead of storing individual index entries for each row, BRIN indexes store block-level summaries, making them smaller in size compared to other index types.
- BRIN indexes work well when the data is sorted or when sequential scans are more efficient than index scans.
To create a BRIN index in PostgreSQL, you use the CREATE INDEX statement with the USING BRIN clause.
Here's an example of creating a BRIN index on a timestamp column:
CREATE INDEX timestamp ON table_name USING BRIN (column);
The above statement creates a BRIN index on the specified timestamp column of the table.
Here are some things to consider when creating a BRIN Index:
- BRIN indexes are most effective when the data is sorted or exhibit natural ordering.
- They may not be suitable for tables with highly unsorted or non-sequential data.
- BRIN indexes are generally used for read-intensive workloads where sequential scans are prevalent.
- Regular maintenance and periodic reindexing may be necessary to ensure optimal performance.
To read more on BRIN Indexes, you can check out the official documentation.
Conclusion
In this quick guide, we have seen other types of indexes supported by PostgreSQL other than the B-Tree index.
It is not recommended to create an index on the fly just before running a one-off query. Creating a well-designed index requires careful planning and testing.
It's important to consider that indexes consume disk space. Also, whenever new data rows are inserted or existing rows are updated, the database automatically updates the corresponding index entries.