
By John Mosesman
In this article, I'm going to share with you my two biggest production mistakes.
Luckily, there's only two of them.
It's not that I haven't made a ton of mistakes in production—I have—but these two in particular required me and the rest of the team to put our heads together and work to revert the damage.
When your mistake takes a team of five the rest of the day to fix it tends to stick in the 'ol memory bank.
I'm not ashamed of these mistakes – it was a little embarrassing in the moment sure – but they were honest mistakes and mistakes happen.
I'm sharing these stories with you so you can know what to do when you inevitably break something in production. And if you stick around in the development world long enough, you will.
But, no one has to lose their heads. [Spoiler alert] I wasn't fired from either job, and I wasn't even really reprimanded either. People make mistakes and the other people on your team and in your company understand that.
Test, hope, and pray
Over time, the development world has adopted practices to help reduce the chance and severity of mistakes.
We write automated tests. We test changes in a staging environment. We do code reviews. We systematize or script our deployment processes.
All of these practices catch or squash a countless number of bugs every day.
But, regardless of all of these practices and processes, mistakes still happen. In the end we're still human, and humans make mistakes.
We miss edge cases. We forget to check the layout in IE9. We delete the wrong record. We bring down half of the internet by passing the wrong parameter to a deploy script.
The mistakes I'm sharing with you fall somewhere in the middle of these, and the first one starts with my very first development job.
First job – first mistake.
I made the first of these mistakes during my very first development job.
I had only been at this job for maybe a year or so, and the team I was on built internal applications to help power the rest of the work the company was doing.
We built customer support and management tooling, but we also setup and managed the databases and web services built on top of those databases that powered the company's products.
In short, we were in charge of a lot of really important and (too) complex SQL queries and databases.
This was my first developer job, and I was scrapping to learn SQL as fast as I could.
We had a QA environment ("quality assurance") aka a test environment with a copy of every database to test against, and new developers like myself were not given write permissions to the production databases (and rightfully so).
To get a change made in production, I first had to write and test the query against my local database.
After I believed it was good locally, I had to then request a "code" review from a more experienced team member who would review the query and, if it was solid, run any structural migrations in the QA environment. After that I could then test again in QA.
Once I was confident that my query worked in QA, I had to then request another code review and ask that the query be executed in production.
All well and good right? Lots of room to practice and lots of checkpoints to make sure things that went into production were solid.
Putting on my big boy pants
After a while of repeating this process successfully, I began to get production write access to a couple of these databases—ones that I was familiar with and were directly relevant to my work.
I had proven I was careful and I could be trusted with production access (you already know where this is going).
If you aren't familiar with SQL, there are a few different types of queries you can run.
Sometimes you just want to retrieve information, and sometimes you want to insert, update, or delete information.
The majority of the queries you write are SELECT – queries to retrieve information. Only occasionally do you do an INSERT, UPDATE, or DELETE.
So, most of the time your queries are harmless. A SELECT doesn't change any data, and there's no risk of something going wrong.
But, sometimes you do need to change that data—and that's when you have to be really really careful.
An UPDATE gone wrong
I don't even remember what task I was doing or why I was doing it.
The only thing I remember now was that blasted UPDATE statement.
I was updating something that involved customer information—updating something like their name, email, or address.
I had written a statement that I believed was correct, and I was testing it as a SELECT:
--UPDATE users SET name = 'blah', ...
SELECT * FROM users
WHERE ...
Notice the UPDATE statement that is commented out above the SELECT. This was a handy format I learned at this job that helped reduce errors in running your queries.
First you write a commented out UPDATE statement with the values you want to set. Next, you write a SELECT below that statement and use the SELECT to test and finalize the result of the query.
By commenting out the first statement you eliminate the possibility of accidentally running the UPDATE before you're ready. The only way to run the statement is to either uncomment it (which takes an action), or by highlighting the text after the comment along with the rest of the query and then running it (which is also a deliberate action).
This little technique prevents many mistakes. But back to my query writing.
When I was ready, all I had to do was uncomment the UPDATE line, comment out the SELECT line, and hit run.
Now the example statement I showed above is greatly simplified compared to the query I had written back then.
The statement I had written back then was a decently complex statement. It had a lot of joins, subqueries, and it was checking some range of orders or products or something else—not just a simple WHERE id = blah kind of thing.
It probably looked more like this:
--UPDATE users SET name = 'blah', ...
SELECT * FROM users
JOIN something
ON something.user_id = users.id
JOIN another_thing
ON another_thing.something_id = something.id
WHERE 1=1
AND something.blah = 'bleh'
AND another_thing.bleh = 'blah'
OR (
users.name <> 'Karen'
AND thing = thing
);
(This is not a "the fish was this big" story I swear.)
I checked that the users I got back were the users I was expecting. I had verified it locally, tested it in QA, and I had gotten approval by a team member to run it in production (see it wasn't my fault (I'm kidding)).
Here's where the problem comes in. And before I tell you what it is I'll give you a little pro tip that will prevent it from ever happening to you.
When running a query that will do a write to the database: drag your cursor from the bottom of the query to the top of the query.
Why drag it from the bottom to the top you say? Good question.
Bottom to top
Let's say I start at the bottom of this query and drag my cursor up halfway and run the query:
 Dragging bottom to top but incomplete
Dragging bottom to top but incomplete
What happens?
Well, nothing.
I didn't select a valid query. The query parser will throw an error and say silly John this isn't a valid query you silly goose.
Oh thanks query parser! No big deal. I'll try again:
 Dragging bottom to top complete
Dragging bottom to top complete
Now I've selected the full query, and it runs. Yay!
All good right?
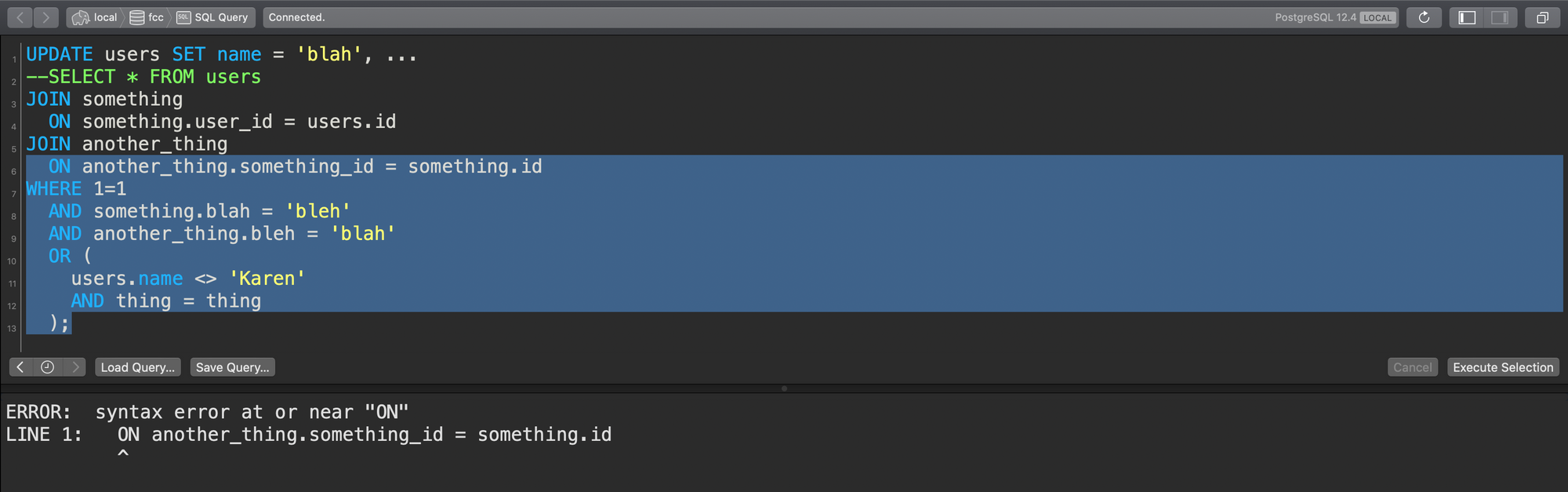
Now what if you're working on this query and due to the size of your window or the scroll position of your query tool you start at the top of the query and drag to the bottom...
 Dragging top to bottom with what you think is the full query
Dragging top to bottom with what you think is the full query
This query runs—but oops! The rest of the query was outside of my viewable area, and I've only included half of my WHERE clause!
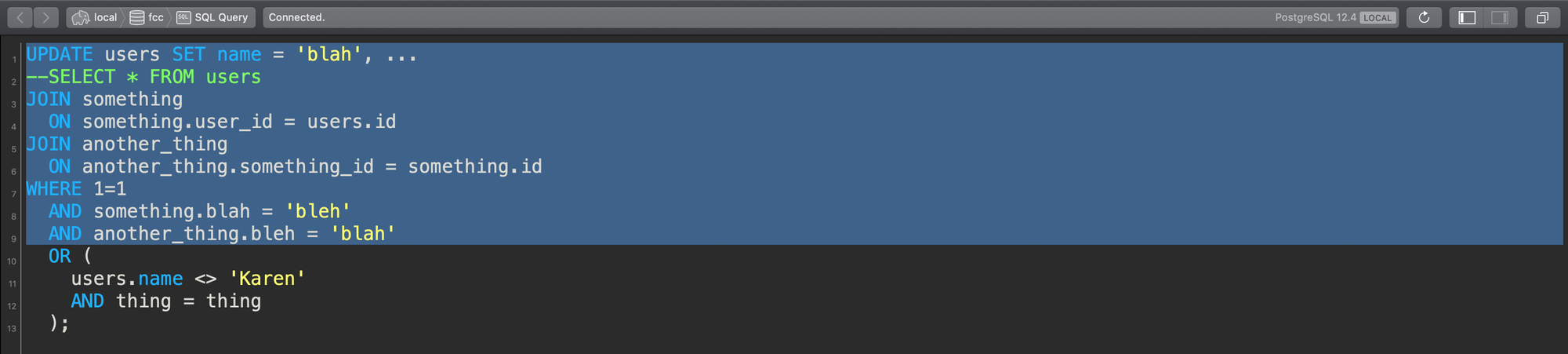 Dragging top to bottom but missing part of the query!
Dragging top to bottom but missing part of the query!
And just like that, it happens. The UPDATE goes awry.
This is exactly what I did.
I ran part of the query, and it was missing some of the filtering conditions to properly limit the result set I was acting on, and I ended up updating the entire users table to one person's information.
Every single user in our system was now "John Smith at 1234 Main Street Ave".
I had goofed, and I realized the problem too late.
So what did I do?
"Secret secrets are no fun. Secret secrets hurt someone." - The Office S03E15
Here's the first major takeaway (aside from that sweet bottom to top query tip): if you make a mistake—tell someone. Immediately.
It can be very tempting to try and hide or ignore the mistake you made—especially if it's serious. I've been there. I've felt those impulses.
You realize your mistake and the dread sets in. Oh no what have I done.
When this happens, there's a few things to remember:
- Every developer of reasonable experience has made production mistakes
- Many of these mistakes are time-sensitive
- I don't know anyone that's been fired over an honest mistake
Every developer has made production mistakes. I've made them, and I'll make them again (but hopefully not the same ones). Anyone who would criticize you for it is either inexperienced or a jerk. Either way you shouldn't care.
Many of these mistakes are also "time-sensitive." This means that the sooner you can fix the problem or revert the change the less damage will be done. Waiting to acknowledge the problem can result in a more difficult process fixing it.
Of all the mistakes I've made and all of the mistakes I've seen others make, I don't know of a single person that has been fired or even seriously scolded over an honest mistake.
I think this is because programming is hard and anyone who's made it into leadership has done something similar or worse.
So here's what you do:
- Own up to it
- Own up to it quickly
- Work to help fix it
Own up to the mistake. Don't shift blame or make excuses—just explain what went wrong and what you've seen or done.
Alert your boss or team lead as soon as you recognize the issue. The severity of the alarm you raise is probably proportional to the size of the mistake.
"Oops I messed up the validation for that field, I went ahead and made another PR to fix it."
If it's a small thing, maybe you can just make a new PR fixing it and tell someone to review it. Small issue, small fix—no biggie.
If, per chance, you update a production table with one value across the entire table—you raise the alarm quickly.
Updating an entire table
As soon as the oh no set in, I grabbed my team lead and told him what happened.
Thankfully he was cool about it, and we set to work trying to undo it.
The unfortunate thing about a bad database update is there's not really an easy way to revert that change. You can't just revert some commits and re-deploy—a database is persistent storage for a reason.
When something goes wrong with the data you have a couple options:
- Write a new query to undo the data (if possible)
- Load up a database backup and find the correct data, pull it out, and run a new update
- Head to Mexico
As enticing as #3 sounds, we went with #2.
Now this happened almost ten years ago, so devops was a bit different back then.
This company managed their own servers and databases and had "tape backups." They also only kept daily backups, so at best we could get data from early the previous day.
Needless to say, this was going to be painful.
To make a long story short, we tried to see if there was a way to re-create the original data and re-update it. After a couple hours we had the data back to its original state—but that's not the important part of the story.
The important part is to admit the mistake. Try to fix it. Learn and don't let it happen again.
If you make a mistake, your teammates will greatly appreciate you actively working to try and fix it. Even if that's just pairing and watching them fix the issue, dive in and take part.
Finally, learn from that mistake and don't make that same mistake twice.
(Drag bottom to top.)
Mistake #2: 7 years later...
After that period I enjoyed a long mistake-free period of about seven years—at least for major mistakes.
Now seven years later, instead of the title Junior Developer I was wearing the shiny hat of Senior Software Engineer (wooOoOo).
It was just like any normal day. Writing code, pushing it up, code reviews, deploying—just an all-around general crushing of the codes.
I got a ping in Slack about a bunch of background workers that were failing. My coworker said that it looked related to my last PR I had recently merged.
"Ok thanks I'll check it out", I replied.
Yep, there were definitely a good amount of jobs failing and they were piling up.
I wasn't too alarmed. Background jobs are generally written in an "idempotent" way—they're generally safe to just re-run when they fail. Most background queueing systems also have a built-in way to automatically retry the jobs after they fail.
It wasn't long after that, however, that things took a turn for the worse.
The alarm bells began to ring—or more realistically—the Slack notifications in the on-call room began sounding off.
Timeouts after timeouts after timeouts. Database usage was reaching 100%. The whole system was coming to a deadlock. All of the companies' products were coming to a standstill.
Oh no.
I didn't know why this was happening, but I knew it was bad.
And so I did the only thing I knew to do: log off and head for Mexi—I mean tell someone immediately.
We jumped into a Zoom call (before Zoom was well-known to the entire world thanks 2020).
As we investigated the matter, we noticed that a particular query was taking a really long time to complete.
Each instance of this query was taking several minutes to run, and there were an ever-growing number of them being kicked off every minute.
We began to look at recent commits in the area of the codebase where the problem seemed to be coming from and we found something suspicious: my last pull request.
In this pull request I updated a background job and changed its behavior.
This project was a Ruby on Rails codebase, and the change I made was something like this—but if you've never seen Rails before, don't worry, I'll explain each line:
def run(some_status)
items = Item.where(status: some_status).all
items.each do |item|
# do some database querying and updating
end
end
This background job calls a function, run, and a status value is passed in as a parameter (some_status).
The first line of the function queries some records from the database.
This line uses methods from the ActiveRecord portion of the Rails framework, but it's really just some nice wrappers around basic SQL queries.
items = Item.where(status: some_status).all
This line is really just a simple SQL statement:
SELECT *
FROM items
WHERE status = ?
When the query is run the value of some_status is bound to the placeholder (?) in the query and then executed.
After the database returns the results of the query, Rails takes these records and creates nice and neat Ruby objects out of them.
So in summary, we query the items table where the status is a certain value.
(Again this is probably not exactly what I was doing but it's close enough to illustrate the scenario.)
The next few lines are a simple loop over the items we retrieved, and for each item we do some more database querying and then update some information on the item.
items.each do |item|
# do some database querying
# then update the item
end
Pretty simple right? Get the stuff. Loop over the stuff. Update the stuff.
However, there's one thing I didn't realize here—and it's a big one.
Little 'ol NULL—or nil
The status field doesn't have a NOT NULL constraint. This means that the status field can be NULL—or in Ruby land: nil (or null in other languages).
It's easy to get used to querying based on things like IDs which you know will always be present. A similar line like...
items = Item.where(id: list_of_ids).all
...would not have produced the same problem. A query looking up records by their ID with a blank list of IDs returns nothing, and so nothing is done.
But in this case, here's the problem. This part of the code:
items = Item.where(status: some_status).all
Is looking up all Item records by a specific status—the one passed in via the some_status parameter.
But, this column value can be NULL (or nil).
So, if the some_status parameter happens to be passed in as nil, it would try to look up all of the Item records where status = nil.
Ok, but that doesn't sound so bad right?
Well, the next layer in this onion of awful is the fact that this items table contained 40 million rows—and most of them didn't have a status.
This little function that was originally trying to load a few records, loop over them, and do some work was now looping through the entire table.
So, when every one of these hundreds or thousands of jobs that were getting kicked off on a steady interval (if I remember correctly about every 15min) started up, each of them started performing very expensive queries for almost every record in the table.
That alone was probably enough to sink the system, but it actually got worse.
You see, I wasn't expecting a nil value to be passed in. This nil value also broke some of the code that the job was supposed to be doing, and so each of these jobs started to fail in turn.
Normally this wouldn't be a big deal, but in most systems when a background job fails it is re-enqueued a short time later.
So not only are all of these very expensive jobs failing, but they're all failing and starting up again a short time later—and they just kept stacking up.
The failing ones eventually would be met with a fresh batch of new jobs starting on their own interval, and the system just ground to a halt.
The final straw is that the work that this background job was supposed to be doing was updating all of those records.
That meant that I was looping through every record in this table and again updating the entire table with bad data.
By pure luck, I had one saving grace here.
The result of this query wasn't ordered. That means that by default the oldest (or first) records of the table were returned first.
That may not seem relevant, but the first and oldest records were effectively legacy data—so updating these records wasn't nearly as bad as records the customers are interacting with every day.
Also, the job kept crashing early in its execution and restarting—which resulted in the jobs only updating the same small and old portion of the table over and over again.
This meant that these jobs never reached the more newer, more relevant rows of the table.
Basically the job only updated a small, insignificant portion of the table before shutting down and trying it again (if I remember correctly only a few thousand rows out of the ~40 million).
It was like I had metaphorically tripped and fallen while walking up to a crosswalk—which kept me from being hit by the car that was going to run the stop sign.
A simple fix
As we reviewed my PR on the Zoom call someone eventually found the error and pointed to the offending line (the query looking up the records by their status).
Even after they said the problem out loud, I still didn't see it. After they tried to explain it again (and maybe even again another time), it finally clicked.
It's a deceptive line of code like this one:
items = Item.where(status: some_status).all
Look up the item by its status—sure seems good. If you're not careful you'll do like I did and miss the lookup with the critical nil case.
Luckily, the fix for this is really easy. Guard the function and do a quick-return like this if the status is nil:
def run(some_status)
return if some_status.nil?
items = Item.where(status: some_status).all
...
end
If you're not familiar with Ruby and Rails, that one-liner is just some syntactic sugar for this:
def run(some_status)
if some_status == nil
return
end
items = Item.where(status: some_status).all
...
end
Basically, if some_status is nil just return early from the function and get the heck out of there man.
This is the fix we ended up deploying, and after some server restarts and stopping the mounting queue of background jobs and long-running queries, things eventually returned to normal.
Since it was 2019 we had better backup solutions in place. We loaded up a recent backup and (carefully) made an update statement to revert the data to its previous state.
UpdateGate2019™ was finally over.
What we can learn from this
There's a few key lessons from these stories.
The first is update statements are scary.
Both of my mistakes were update statements. When updating (or deleting) records take extra caution to ensure the records you're going to update are the correct ones.
If you're executing a raw SQL query, be sure to drag "bottom to top" to ensure you run the entire statement. If you're doing an update through code, be extra careful of the parameters and dynamic pieces of your query. Check for nil, NULL, or null depending on your language.
The second important takeaway is if something goes wrong—tell someone immediately.
Hiding or ignoring the problem will only make things worse. The sooner you can surface an issue to your team the sooner you can stop damage from continuing to be done, and it will save you a ton of pain in the long run.
Third: I don't know anyone that was fired from making a mistake.
In both cases my team realized it was an honest mistake.
Afterwards we did a little retrospective to determine how it happened and what we could do to avoid this same mistake in the future.
Mistakes often come from the same root cause: rushing to get work done.
Looming deadlines, tired minds, and not reviewing PRs with enough scrutiny can cause many mistakes to slip through the cracks.
Onward
I'm glad to know I have six more good years in me before I make another terrible mistake (kidding).
I know I'll make another mistake again—mistakes happen.
But, these mistakes didn't destroy my career or fill me with shame. It's just a mistake. I tried to learn from it, and I hope by reading this you will also learn from my mistakes without having to experience them yourself.
If you enjoyed this post, you can follow me on Twitter where I talk about stuff like this—career development and how to succeed as a developer. I also write about these same topics on my site.
Thanks for reading!
John