
By Vikash Singh
When developers work with text, they often need to clean it up first. Sometimes it’s by replacing keywords. Like replacing “Javascript” with “JavaScript”. Other times, we just want to find out whether “JavaScript” was mentioned in a document.
Data cleaning tasks like these are standard for most Data Science projects dealing with text.
Data Science starts with data cleaning.
I had a very similar task to work on recently. I work as a Data Scientist at Belong.co and Natural Language Processing is half of my work.
When I trained a Word2Vec model on our document corpus, it started giving synonyms as similar terms. “Javascripting” was coming as a similar term to “JavaScript”.
To resolve this, I wrote a regular expression (Regex) to replace all known synonyms with standardized names. The Regex replaced “Javascripting” with “JavaScript”, which solved 1 problem but created another.
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
The above quote is from this stack-exchange question and it came true for me.
It turns out that Regex is fast if the number of keywords to be searched and replaced is in the 100s. But my corpus had over 20K keywords and 3 Million documents.
When I benchmarked my Regex code, I found it was going to take 5 days to complete one run.
 oh the horror
oh the horror
The natural solution was to run it in parallel. But that won’t help when we reach 10s of millions of documents and 100s of thousands of keywords. There had to be a better way! And I started looking for it…
I asked around in my office and on Stack Overflow — a couple of suggestions came up. Vinay Pandey, Suresh Lakshmanan and Stack Overflow pointed towards the beautiful algorithm called Aho-Corasick algorithm and the Trie Data Structure approach. I looked for existing solutions but couldn’t find much.
So I wrote my own implementation and FlashText was born.
Before we get into what is FlashText and how it works, let’s have a look at how it performs for search:
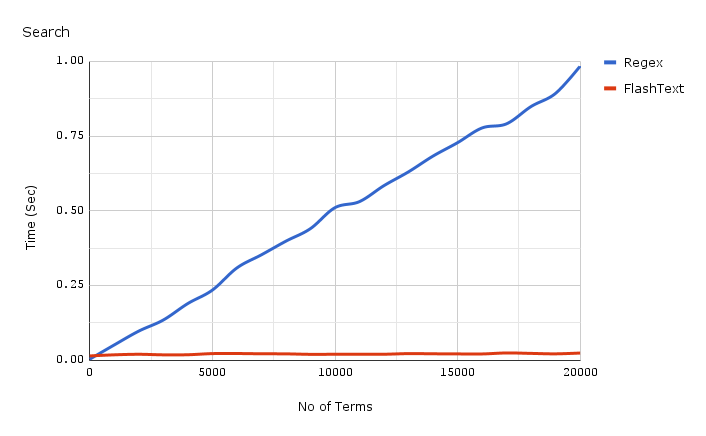 Red Line at the bottom is time taken by FlashText for Search
Red Line at the bottom is time taken by FlashText for Search
The chart shown above is a comparison of Complied Regex against FlashText for 1 document. As the number of keywords increase, the time taken by Regex grows almost linearly. Yet with FlashText it doesn’t matter.
FlashText reduced our run time from 5 days to 15 minutes!!
 we are good now :)
we are good now :)
This is FlashText timing for replace:
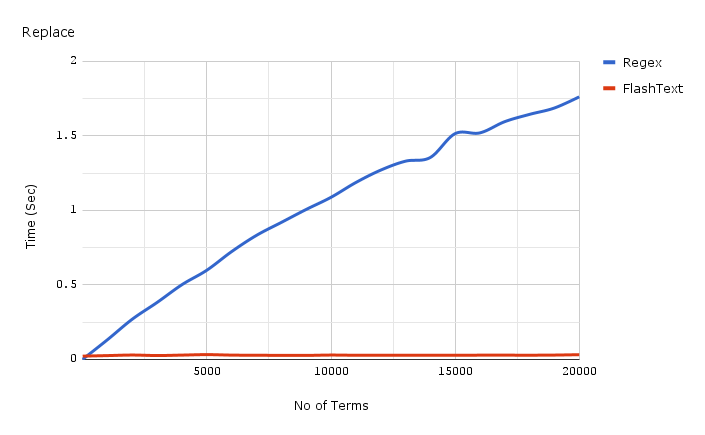 Red Line at the bottom is time taken by FlashText for Replace
Red Line at the bottom is time taken by FlashText for Replace
Code used for the benchmark shown above is linked here, and results are linked here.
So what is FlashText?
FlashText is a Python library that I open sourced on GitHub. It is efficient at both extracting keywords and replacing them.
To use FlashText first you have to pass it a list of keywords. This list will be used internally to build a Trie dictionary. Then you pass a string to it and tell if you want to perform replace or search.
For **replace** it will create a new string with replaced keywords. For **search** it will return a list of keywords found in the string. This will all happen in one pass over the input string.
Here is what one happy user had to say about the library:
Why is FlashText so fast ?
Let’s try and understand this part with an example. Say we have a sentence which has 3 words I like Python, and a corpus which has 4 words {Python, Java, J2ee, Ruby}.
If we take each word from the corpus, and check if it is present in sentence, it will take 4 tries.
is 'Python' in sentence? is 'Java' in sentence?...
If the corpus had n words it would have taken n loops. Also each search step is <word> in sentence? will take its own time. This is kind of what happens in Regex match.
There is another approach which is reverse of the first one. For each word in the sentence, check if it is present in corpus.
is 'I' in corpus?is 'like' in corpus?is 'python' in corpus?
If the sentence had m words it would have taken m loops. In this case the time it takes is only dependent on the number of words in sentence. And this step, is <word> in corpus? can be made fast using a dictionary lookup.
FlashText algorithm is based on the second approach. It is inspired by the Aho-Corasick algorithm and Trie data structure.
The way it works is:
First a Trie dictionary is created with the corpus. It will look somewhat like this:
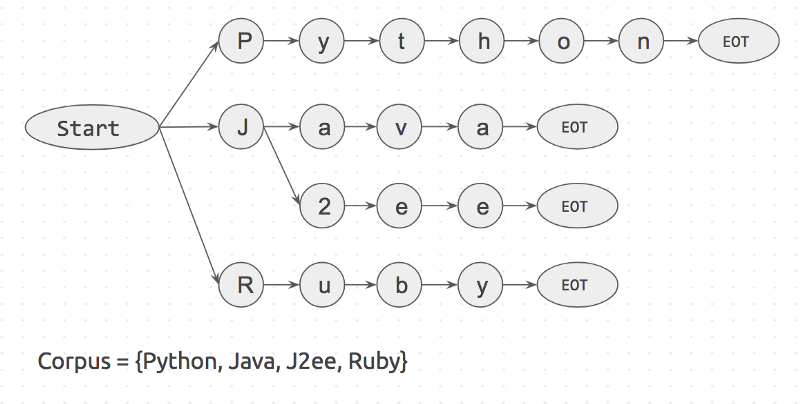 Trie dictionary of the corpus.
Trie dictionary of the corpus.
Start and EOT (End Of Term) represent word boundaries like space, period and new_line. A keyword will only match if it has word boundaries on both sides of it. This will prevent matching apple in pineapple.
Next we will take an input string I like Python and search it character by character.
Step 1: is <start>I<EOT> in dictionary? NoStep 2: is <start>like<EOT> in dictionary? NoStep 3: is <start>Python<EOT> in dictionary? Yes
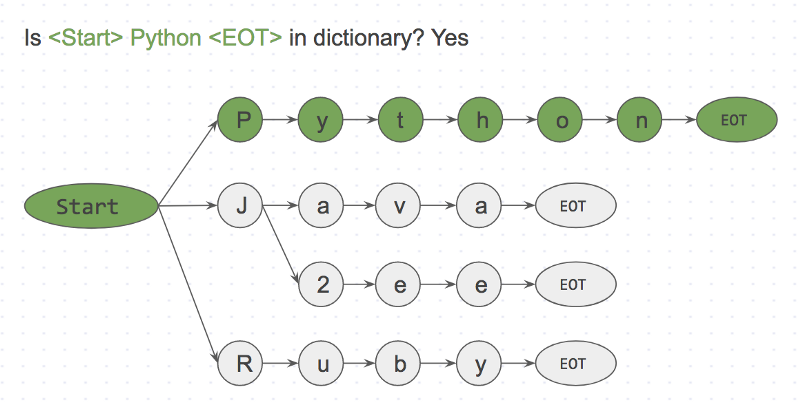 <Start> Python <EOT> is present in dictionary.
<Start> Python <EOT> is present in dictionary.
Since this is a character by character match, we could easily skip <start>like<;EOT> at l because l is not connected to start. This makes skipping missing words really fast.
The FlashText algorithm only went over each character of the input string ‘I like Python’. The dictionary could have very well had a million keywords, with no impact on the runtime. This is the true power of FlashText algorithm.
So when should you use FlashText?
Simple Answer: When Number of keywords > 500
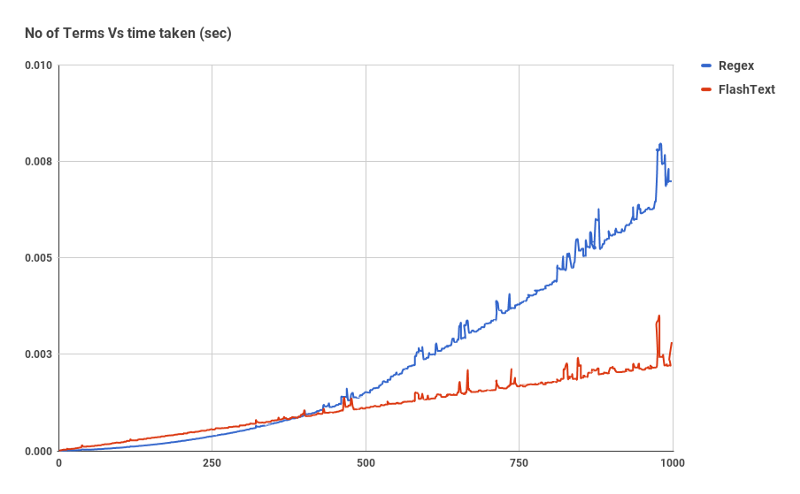 For search FlashText starts outperforming Regex after ~ 500 keywords.
For search FlashText starts outperforming Regex after ~ 500 keywords.
Complicated Answer: Regex can search for keywords based special characters like ^,$,*,\d,. which are not supported in FlashText.
So it’s no good if you want to match partial words like word\dvec. But it is excellent for extracting complete words like word2vec.
FlashText for finding keywords
FlashText for replacing keywords
Instead of extracting keywords you can also replace keywords in sentences. We use this as a data cleaning step in our data processing pipeline.
If you know someone who works with text data, Entity recognition, natural language processing, or Word2vec, please consider sharing this blog with them.
This library has been really useful for us, and I am sure it would be useful for others too.
So long, and thanks for all the claps ?