
By Alex Moldovan
How does your front-end application scale? How do you make sure that the code you’re writing is maintainable 6 months from now?
Redux took the world of front-end development by storm in 2015 and established itself as a standard — even beyond the scope of React.
At the company where I work, we recently finished refactoring a fairly large React codebase, adding redux instead of reflux.
We did it because moving forward would have been impossible without a well structured application and a good set of rules.
The codebase is more than two years old, and reflux was there from the beginning. We had to change code that wasn’t touched in more than a year and was pretty tangled with the React components.
Based on the work we did on the project, I put together this repo, explaining our approach in organizing our redux code.
When you learn about redux and the roles of actions and reducers, you start with very simple examples. Most tutorials available today don’t go to the next level. But if you’re building something with Redux that’s more complicated than a todo list, you’ll need a smarter way of scaling your codebase over time.
Someone once said that naming things is one of the hardest jobs in computer science. I couldn’t agree more. But structuring folders and organizing files is a close second.
Let’s explore how we approached code organization in the past.
Function vs Feature
There are two established approaches of structuring applications: function-first and feature-first.
One the left below you can see a function-first folder structure. On the right you can see a feature-first approach.
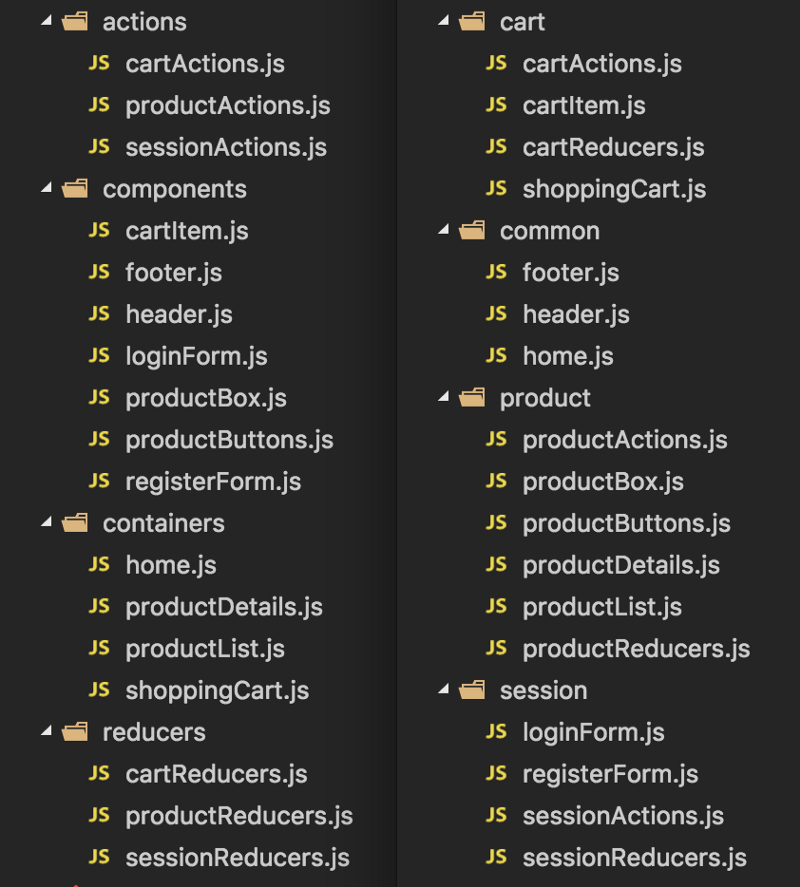
Function-first means that your top-level directories are named after the purpose of the files inside. So you have: containers, components, actions, reducers, etc.
This doesn’t scale at all. As your app grows and you add more features, you add files into the same folders. So you end up with having to scroll inside a single folder to find your file.
The problem is also about coupling the folders together. A single flow through your app will probably require files from all folders.
One advantage of this approach is that it isolates — in our case — React from redux. So if you want to change the state management library, you know which folders you need to touch. If you change the view library, you can keep your redux folders intact.
Feature-first means that the top-level directories are named after the main features of the app: product, cart, session.
This approach scales much better, because each new feature comes with a new folder. But, you have no separation between the React components and redux. Changing one of them on the long run is a very tricky job.
Additionally you have files that do not belong to any feature. You end up with a folder common or shared, because you want to reuse code across many features in your app.
The best of two worlds
Although not in the scope of this article, I want to touch this single idea: always separate State Management files from UI files.
Think about your application on the long run. Imagine what happens with the codebase when you switch from React to another library. Or think how your codebase would use ReactNative in parallel with the web version.
Our approach starts from the need to isolate the React code into a single folder — called views — and the redux code into a separate folder — called redux.
This first level split gives us the flexibility to organize the two separate parts of the app completely different.
Inside the views folder, we prefer a function-first approach in structuring files. This feels very natural in the context of React: pages, layouts, components, enhancers etc.
To not go crazy with the number of files in a folder, we may have a feature based split inside each of these folders.
Then, inside the redux folder…
Enter re-ducks
Each feature of the application should map to separate actions and reducers, so it makes sense to go for a feature-first approach.
The original ducks modular approach is a nice simplification for redux and offers a structured way of adding each new feature in your app.
Yet, we wanted to explore a bit what happens when the app scales. We realized that a single file for a feature becomes too cluttered and hard to maintain on the long run.
This is how re-ducks was born. The solution was to split each feature into a duck folder.
duck/
├── actions.js
├── index.js
├── operations.js
├── reducers.js
├── selectors.js
├── tests.js
├── types.js
├── utils.js
A duck folder MUST:
- contain the entire logic for handling only ONE concept in your app, ex: product, cart, session, etc.
- have an
index.jsfile that exports according to the original duck rules. - keep code with similar purpose in the same file, such as reducers, selectors, and actions
- contain the tests related to the duck.
For this example, we haven’t used any abstraction built on top of redux. When building software, it’s important to start with the least amount of abstractions. This way, you make sure that the cost of your abstractions doesn’t outweigh the benefits.
If you need to convince yourself that abstractions can be bad, watch this awesome talk by Cheng Lou.
Let’s see what goes into each file.
Types
The types file contains the names of the actions that you are dispatching in your application. As a good practice, you should try to scope the names based on the feature they belong to. This helps when debugging more complex applications.
const QUACK = "app/duck/QUACK";
const SWIM = "app/duck/SWIM";
export default {
QUACK,
SWIM
};
Actions
This file contains all the action creator functions.
import types from "./types";
const quack = ( ) => ( {
type: types.QUACK
} );
const swim = ( distance ) => ( {
type: types.SWIM,
payload: {
distance
}
} );
export default {
swim,
quack
};
Notice how all the actions are represented by functions, even if they are not parametrized. A consistent approach is more than needed in a large codebase.
Operations
To represent chained operations you need a redux middleware to enhance the dispatch function. Some popular examples are: redux-thunk, redux-saga or redux-observable.
In our case, we use redux-thunk. We want to separate the thunks from the action creators, even with the cost of writing extra code. So we define an operation as a wrapper over actions.
If the operation only dispatches a single action — doesn’t actually use redux-thunk — we forward the action creator function. If the operation uses a thunk, it can dispatch many actions and chain them with promises.
import actions from "./actions";
// This is a link to an action defined in actions.js.
const simpleQuack = actions.quack;
// This is a thunk which dispatches multiple actions from actions.js
const complexQuack = ( distance ) => ( dispatch ) => {
dispatch( actions.quack( ) ).then( ( ) => {
dispatch( actions.swim( distance ) );
dispatch( /* any action */ );
} );
}
export default {
simpleQuack,
complexQuack
};
Call them operations, thunks, sagas, epics, it’s your choice. Just find a naming convention and stick with it.
At the end, when we discuss the index, we’ll see that the operations are part of the public interface of the duck. Actions are encapsulated, operations are exposed.
Reducers
If a feature has more facets, you should definitely use multiple reducers to handle different parts of the state shape. Additionally, don’t be afraid to use combineReducers as much as needed. This gives you a lot of flexibility when working with a complex state shape.
import { combineReducers } from "redux";
import types from "./types";
/* State Shape
{
quacking: bool,
distance: number
}
*/
const quackReducer = ( state = false, action ) => {
switch( action.type ) {
case types.QUACK: return true;
/* ... */
default: return state;
}
}
const distanceReducer = ( state = 0, action ) => {
switch( action.type ) {
case types.SWIM: return state + action.payload.distance;
/* ... */
default: return state;
}
}
const reducer = combineReducers( {
quacking: quackReducer,
distance: distanceReducer
} );
export default reducer;
In a large scale application, your state tree will be at least 3 level deep. Reducer functions should be as small as possible and handle only simple data constructs. The combineReducers utility function is all you need to build a flexible and maintainable state shape.
Check out the complete example project and look how combineReducers is used. Once in the reducers.js files and then in the store.js file, where we put together the entire state tree.
Selectors
Together with the operations, the selectors are part of the public interface of a duck. The split between operations and selectors resembles the CQRS pattern.
Selector functions take a slice of the application state and return some data based on that. They never introduce any changes to the application state.
function checkIfDuckIsInRange( duck ) {
return duck.distance > 1000;
}
export default {
checkIfDuckIsInRange
};
Index
This file specifies what gets exported from the duck folder. It will:
- export as default the reducer function of the duck.
- export as named exports the selectors and the operations.
- export the types if they are needed in other ducks.
import reducer from "./reducers";
export { default as duckSelectors } from "./selectors";
export { default as duckOperations } from "./operations";
export { default as duckTypes } from "./types";
export default reducer;
Tests
A benefit of using Redux and the ducks structure is that you can write your tests next to the code you are testing.
Testing your Redux code is fairly straight-forward:
import expect from "expect.js";
import reducer from "./reducers";
import actions from "./actions";
describe( "duck reducer", function( ) {
describe( "quack", function( ) {
const quack = actions.quack( );
const initialState = false;
const result = reducer( initialState, quack );
it( "should quack", function( ) {
expect( result ).to.be( true ) ;
} );
} );
} );
Inside this file you can write tests for reducers, operations, selectors, etc.
I could write a whole different article about the benefits of testing your code, there are so many of them. Just do it!
So there it is
The nice part about re-ducks is that you get to use the same pattern for all your redux code.
The feature-based split for the redux code is much more flexible and scalable as your application codebase grows. And the function-based split for views works when you build small components that are shared across the application.
You can check out a full react-redux-example codebase here. Just keep in mind that the repo is still under active development.
How do you structure your redux apps? I’m looking forward to hearing some feedback on this approach I’ve presented.
If you found this article useful, click on the green heart below and I will know my efforts are not in vain.