
By Alfarhan Zahedi
Recently, I published my first Django application on Heroku.
The application is fairly simple — it lists the score associated with every classical problem on SPOJ.
SPOJ — Sphere Online Judge — is a problemset archive, online judge and contest hosting service accepting solutions in many languages.
You can find the application live here.
The application uses the Python libraries [bs4](https://www.crummy.com/software/BeautifulSoup/bs4/doc/) and [requests](http://docs.python-requests.org/en/master/) to scrape the contents of the aforementioned website, obtain the required details for every problem (namely — problem code, problem name, users and score), and store them in a database.
Now, the score associated with the problems on SPOJ is dynamic. It is calculated using the following formula:
80 / (40 + number_of_people_who_have_solved_the_problem)
So, the score associated with the problems on SPOJ changes as number_of_people_who_have_solved_the_problem changes.
Hence, the data collected by my application will be rendered useless after a certain interval of time. I need to set up a scheduler to keep my database updated.
Now, it’s a dead simple application. So I wanted to set up the scheduler with the least amount of configuration and code possible.
Custom Django Management Commands and Heroku Scheduler to the rescue!
Let us understand our two saviors.
1. Custom Django Management Commands
Custom Django Management Commands are structured as Python classes that inherit their properties and behavior from django.core.management.base.BaseCommand class.
They are used to add a manage.py action for a Django app. runserver or migrate are two such actions.
A typical example of such a class would be:
from django.core.management.base import BaseCommand
class Command(BaseCommand): help = "<appropriate help text here>" def handle(self, *args, **options): self.stdout.write("Hello, World!")
The class must be named Command, and subclass BaseCommand.
help should hold a short description of the command, which will be printed in help messages.
handle(self, *args, **options) defines the actual logic of the command. In this case, we are just writing the string Hello, World! into the standard output. In my case, handle(self, *args, **options) performs the task of scraping the website — spoj.com and updating the database if the score associated with any of the problem changes.
handle(self, *args, **options) is automatically run whenever the following command is used:
python manage.py <name of the python script containing the management class>
If the name of the script is, say, script.py, then the command would be:
python manage.py script
Notice the handle method declares three input argument: self to reference the class instance, *args to reference arguments of the method itself, and **option to reference arguments passed as part of the management command.
Where in the project structure does this script.py go?
(Here, script.py refers to the name of the script containing the custom Django management command.)
It’s quite simple. The official documentation explains it well:
Just add a
**management/commands**directory to the application. Django will register a**manage.py**command for each Python module in that directory whose name doesn’t begin with an underscore.For example:
polls/ __init__.py models.py management/ __init__.py commands/ __init__.py _private.py closepoll.py tests.py views.py
_In this example, the
**closepoll**command will be made available to any project that includes the**polls**application in[**INSTALLED_APPS**](https://docs.djangoproject.com/en/2.0/ref/settings/#std:setting-INSTALLED_APPS).__The
**_private.py**module will not be available as a management command._The
**closepoll.py**module has only one requirement – it must define a class**Command**that extends[**BaseCommand**](https://docs.djangoproject.com/en/2.0/howto/custom-management-commands/#django.core.management.BaseCommand)or one of its subclasses.And so, if we run the following command in our terminal:
_python manage.py closepoll_,
_handle(self, *args, **options)_insideclosepoll.pywill be run, and any logic/tasks contained inside the aforementioned function will be executed.
My project structure is as follows:
spojscore│ .gitignore│ manage.py│ Procfile│ README.md│ requirements.txt│ runtime.txt│├───core│ │ admin.py│ │ apps.py│ │ models.py│ │ tests.py│ │ views.py│ │ __init__.py│ ││ ├───management│ │ │ __init__.py│ │ ││ │ ├───commands│ │ script.py│ │ __init__.py│ │ │ ││ ├───static│ │ └───core│ │ ├───css│ │ │ style.css│ │ ││ │ └───img│ │ favicon.png│ │ logo.png│ ││ ├───templates│ └───core│ core.html│└───spojscore settings.py urls.py wsgi.py __init__.py
Here, script.py contains the custom management command — Python code to scrape spoj.com, collect details of all the classical problems, and update the database accordingly.
If you see, it’s situated inside core\management\commands.
If you are interested, you can find script.py here.
I think its clear now that I can scrape spoj.com and obtain the desired data by simply running python manage.py script from the terminal.
So, to keep my database updated, I just need to run the above command at least once a day.
2. Heroku Scheduler
As per Heroku’s website:
Scheduler is a free add-on for running jobs on your app at scheduled time intervals, much like
cronin a traditional server environment.A dashboard allows you to configure jobs to run every 10 minutes, every hour, or every day, at a specified time. When invoked, these jobs will run as one-off dynos and show up in your logs as a dyno named like
scheduler.X.
Once you’ve deploying the application, install the Heroku Scheduler add-on.
To schedule a frequency and time for a job, open the Heroku Scheduler dashboard by finding the app in My Apps, clicking “Overview”, then selecting “Heroku Scheduler” from the Installed add-ons list.
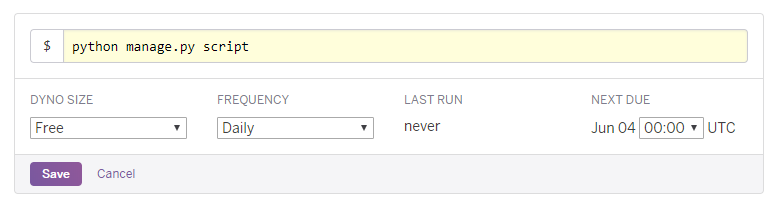
On the Scheduler Dashboard, click “Add Job…”, enter a task, select a frequency, dyno size, and next run time.
In my case, the task is python manage.py script, which is to be executed daily (frequency) using my free dynos (dyno size) at 00:00 UTC (next run time).
That’s it!
My database will be updated at 00:00 UTC every day, and I didn’t have to install any extra Python libraries, or write any extra pieces of code. Yay!
If you get stuck anywhere, drop a comment and I will try my best to help you.
Some final notes:
- Heroku’s official website says that — “Scheduler job execution is expected but not guaranteed. Scheduler is known to occasionally (but rarely) miss the execution of scheduled jobs. If scheduled jobs are a critical component of your application, it is recommended to run a custom clock process instead for more reliability, control, and visibility.” This point should be kept in mind while using Heroku Scheduler.
Mine is dead simple application which uses the Heroku Scheduler to run a simple script just once a day. So, I guess it would do a great job! - My application, I suppose, is useful for competitive programmers. Why? I have explained it in great detail here.
- You can find the source code of my application here.
A piece from my personal musings:
I am just another self-taught programmer.
I have being writing code for a couple of years now, and have always wanted to write about my experiences, endeavors, failures and successes.
But alas, I could not.
I thought that my endeavors were not exciting enough or that my experiences were not going to help anyone. And so I restrained myself from writing about them.
To be honest, I think the same now.
So, how come I wrote this article?
Well, this is going to be my first of many articles.
And the reason for the change, you ask?
A newsletter.
Last week, as usual, I received the weekly newsletter from CSS-Tricks — “This week in Web Design and Development”.
Here, is an excerpt from the same:
It’s buck wild to have so many helpful resources available to help us at any moment: from blog posts and books to random node.js conference talks that only have 8 views and 7 of them are now mine. So I think this weekend has reinforced my faith in blogging and sharing what you know, where random notes left on some developer’s old blog have helped me tremendously.
Anywho, on a similar note, I’ve been thinking a bunch about how social networks prioritize fame over value. If you publish something on Medium for example and it only gets a single clap then it makes you feel like, why bother? What’s the point if no-one’s reading this thing? But I think we have to fight that inclination to be woo’d with fame and social-network notoriety because I wonder how many helpful blog posts and videos weren’t made simply because someone thought they weren’t going to get half a million likes or retweets from it.
My advice after learning from so many helpful people this weekend is this: if you’re thinking of writing something that explains something you struggled with, do it! Don’t worry about the views and likes and Internet hugs. If you’ve struggled with figuring out this one weird thing then jot it down, even if it’s unedited and it uses too many commas and you don’t like the tone of it.
That’s because someone like me is bound to find what you’ve written and it’ll make their whole weekend a lot less stressful than it could’ve been.
That’s it. Those few lines inspired me to write about my endeavors and experiences.
Maybe, you should too.