By Janeth Ledezma
A web scraper is a tool that allows us to select and transform a website’s unstructured data into a structured database. So where would a web scraper come in handy? I have listed my favorite use cases to get you excited about launching your own!
- Scrape real estate listings — businesses are using web scraping to gather already listed properties
- Scrape products/product reviews from retailer or manufacturer websites to show in your site, provide specs/price comparison
- Scrape news websites to apply custom analysis and curation (manual or automatic), provide better-targeted news to your audience
- Gathering email addresses for lead generation
You can read other handy use cases for a web scraper here.
Now Let’s get started! As a simple example — we’ll scrape the front page of Hacker News to fetch the titles of links.
_If you’re not familiar with Standard Library yet, you’re in for a treat! Standard Library is an API development and publishing platform that can help you build and ship code in record time using the in-browser API editor —Code on Standard Library._
Step One: Sign in to Code on Standard Library
The first step is to head over to https://code.stdlib.com/ and create a free account. Code on Standard Library is an online API editor built by the team at Standard Library — an embeddable development environment for quickly building APIs, webhooks, and workflow automation tasks.
On the bottom left corner click (sign in). If you have a Standard Library account click, Already Registered, and sign in using your Standard Library credentials. A modal will pop up prompting you to claim a namespace (this is your username). Input your e-mail and choose a password.
After you create your account, a different module will appear listing the subscription plans. A free account is all you need to get started, but you can read more about Standard Library’s pricing packages here.
Once you click Subscribe + Earn Credits, you should see a confirmation message pop up.
Click Continue to return to the landing page.
Step Two: Select the Web Scraper Sourcecode
Select API from sourcecode button. Standard Library Sourcecodes are designed to streamline the creation of different types of projects. Sourcecodes provide defaults for things like boilerplate code and directory setup so you can get right to the development and implementation of more complex functionality.
You should see a list of published sourcecodes. Scroll down and select @nemo/web -scraper. Make sure to enter your desired name for your API and hit Okay (or press enter)
You will then see your endpoint’s code under: functions/__main__.js
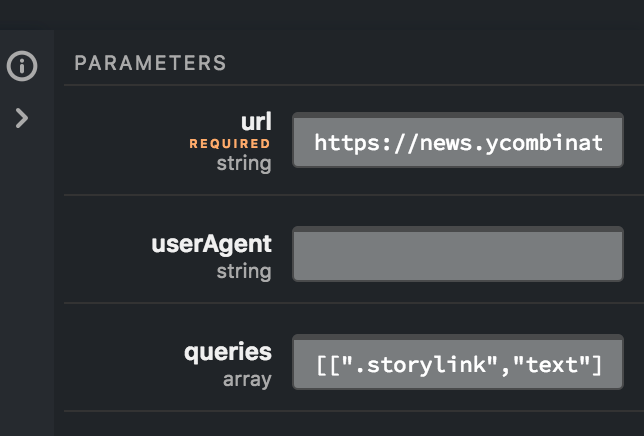
On the right side you will notice a parameters box.
In the URL required parameter type:
[https://news.ycombinator.com/](https://news.ycombinator.com/)
In the queries type:
[[".storylink", "text"]]
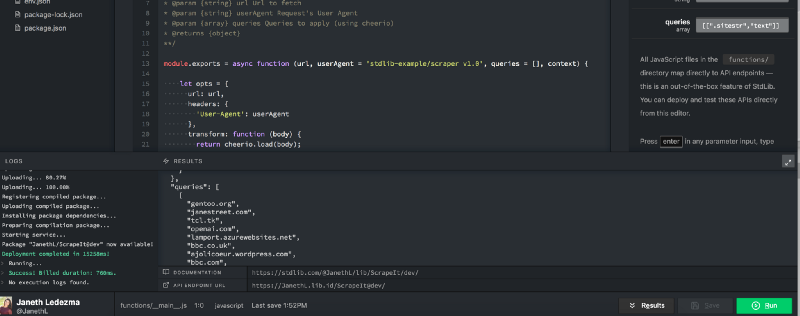
Select the green “Run” button.
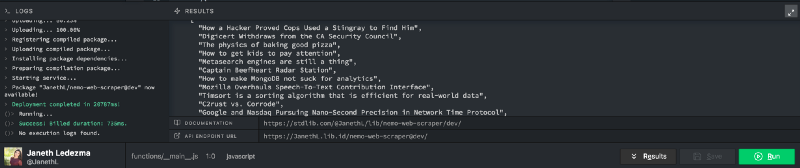
Within seconds you should have a list of link titles from the front page of Hacker News under the Results section of Code on Standard Library. You will notice a documentation portal — copy and paste the Documentation URL into a new tab in your browser to see your API’s information on Standard Library.
How It Works ?
The web scraper makes a simple GET request to a URL, and runs a series of queries on the resulting page and returns it to you. It uses the powerful cheerio DOM (Document Object Model) processor, enabling us to use CSS-selectors to grab data from the page! CSS selectors are patterns used to select the element(s) you want to organize.
How to Query Using CSS Selectors
Web pages are written in markup languages such as HTML An HTML element is one component of an HTML document or web page. Elements define the way information is displayed to the human eye on the browser- information such as images, multimedia, text, style sheets, scripts etc.
For this example, we used the “.class” selector (class = “.storylink” ) to fetch the titles of all hyperlinks from all elements in the front page of Hacker News.
If you are wondering how to find the names of the elements that make up a website - allow me to show you!
Fire up Google Chrome and type in our Hacker News URL address [https://news.ycombinator.com/](https://news.ycombinator.com/). Then right-click on the title of any article and select “inspect.” This will open the Web Console on Google Chrome. Or you can use command key (⌘) + option key (⌥ ) + J key.
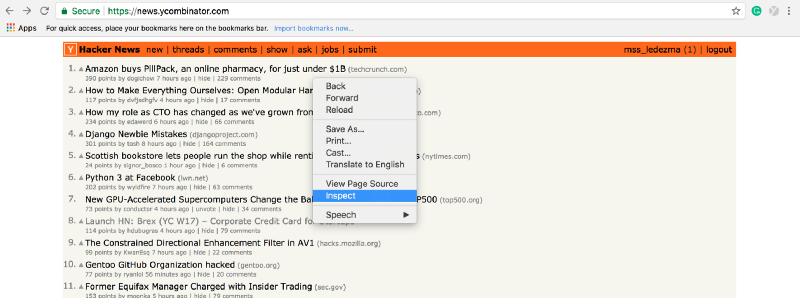
The web-developer console will open to the right of your screen. Notice that when you selected the title of a link a section on the console is also highlighted. The highlighted element has “class” defined as “storylink.” And now you know how to find the names of elements on any site!
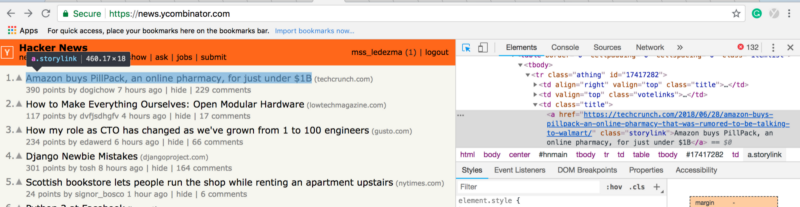
If you want to query different metadata on Hacker News, hover your cursor over it. Below you can see how that I found the .class selector = “sitestr” to query a link’s URL by hovering my mouse over that element on Hacker News.

That’s It, and Thank You!
Thanks for reading! I would love for you to comment here, e-mail me at Janeth [at] stdlib [dot] com, or follow Standard Library on Twitter, @StdLibHQ . Let me know if you’ve built anything exciting that you would like Standard Library team to feature or share — I’d love to help!
_Janeth Ledezma is a Developer Advocate for Standard Library and Berkeley grad— go bears! ? When she isn’t learning the Arabic language, or working out, you can find her riding her CBR500R. ?? Follow her journey with Standard Library on Twitter @mss_ledezma._