By Dmitri Zimine
The (Emit) conference last week featured a lineup of excellent talks, an engaging panel discussion, and plenty of time to meet and exchange notes with the awesome fellows of the serverless community.
Cost is unanimously cited as the key driver for serverless adoption. On-demand execution and built-in elasticity optimizes utilization while keeping uptime and reliability even higher. Pay-per-use billing makes cost directly quantifiable. The savings can be insane. Anne Thomas, a Gartner analyst, shared at the panel discussion that her enterprise clients are attracted to serverless by “cost” benefits.
But there is no free lunch in a closed system: to gain a benefit something must be sacrificed. In technology, the most common currency to pay for benefits is “complexity”.
When microservices replaced monoliths to gain the benefit of scale reliably under massive load, it was not a free lunch. Dealing with eventual consistency, handling asynchronicity, latency and fault tolerance, managing APIs and message schemas, load balancing, running rolling upgrades — we paid with a great deal of extra complexity for the gains.
Where does the complexity reside, and how do we manage it?
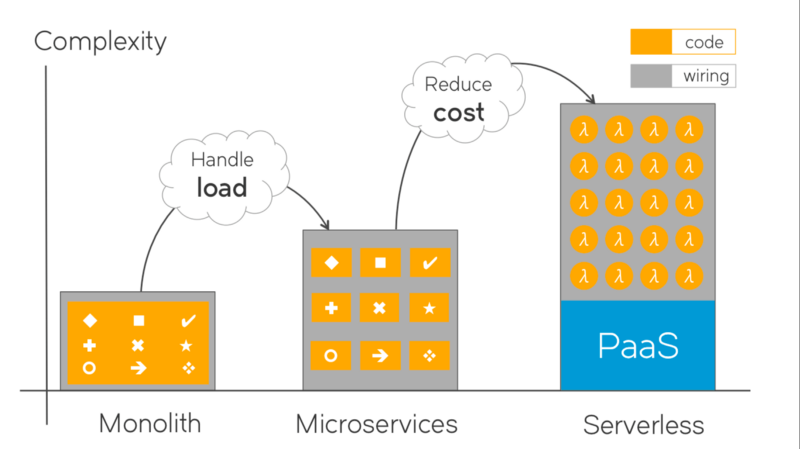
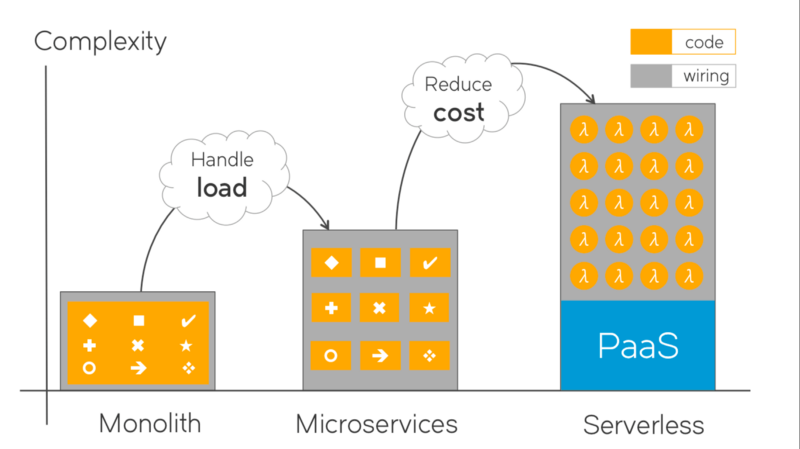
Take a look at the picture. The orange blocks represents the code. As we move to micro-services to serverless, the individual blocks of code become smaller and simpler, while the total complexity grows. Much of this extra complexity is “wiring”: configurations, deployment scripts, devops tooling artifacts — templates, recipes, playbooks, dockerfiles… All the stuff used to forklift the solution up to the cloud, and keep it there. The gray stuff between the orange code blocks. This reminds me of an old Russian joke:
- What is air made of?
- Well, it’s made from molecules!
- And what is between the molecules?
- Well, of course air!
This wiring between the code: it better be code! And this is what DevOps was all about with it’s “Infrastructure as code” mantra. Devops — to give yet another definition — is a framework and tooling to tame the extra wiring complexity introduced by micro services.
When Serverless replaces micro-services, it is not going to be free lunch either. We are paying by introducing more complexity, now for the benefit of massive cost savings.
Some parts of the serverless system do become simpler. Not dealing with virtual machines, networking, storage, and operation systems is a huge relief from the massive operational burden of provisioning, configuring, monitoring and remediating infrastructure. Functions provide a simple programming model and mostly focus on business logic. The execution environment is tight, controlled and under “continuous X-Ray”. Chris Anderson, a PM for @AzureFunctions, highlighted how much easier it became to pinpoint problems with function executions.
But the law of conservation still applies, and when function are simplified, the released complexity moves somewhere else. Where does the complexity go, and how do we manage it?
Part of complexity is delegated to cloud PaaS services (may I call it JPaaS? [3]) . AWS API Gateway, S3, Kinesis, SNS, DynamoDB, StepFunctions, or their Azure and GCP siblings — are at play with any serverless solution. They are readily available, fully managed, feature rich, “infinitely” scalable, and pay-per use. To gain their benefits, we happily trade control — another common tech currency — to be liberated from infrastructure and boilerplate concerns. Note the return from micro-services’ “Smart endpoints and dumb pipes” back to “dumb endpoints and smart pipes” and even the workflows; spend a minute to reflect on this pendulum sway.
Sometimes, the surrender of control backfires and complexity unexpectedly spikes where things used to be simple. Setting up binary headers in AWS API Gateway via CloudFormation templates makes you miss the clarity of handling it in your microservice’s code. Using feature-rich JPaaS services requires deep expertise, and unlike regular programming and CS this expertise doesn’t translate between platforms: knowing DymanoDB will be little help in learning BigTable.
Nevertheless, the delegation to JPaaS is a net positive and covers a good part of complexity. But not all of it. The other part of complexity lies, again, in “wiring”.
Functions are smaller, but there are an order of magnitude more relations to understand and dependencies to manage. Functions are simpler, but they no longer contain the logical flow. The logic and the flow of the end-to-end solution is driven by events. It no longer resides in any coding artifacts, and becomes very difficult to reason about.
How is this side of complexity handled today? Not too well. It takes uber-architect(s) to keep it under control. The processes and tools are yet to catch up. Serverless frameworks are growing like mushrooms after the rain but are mostly stuck with FaaS — with slight variations on the same, an already solved problem. Even the most advanced ‘serverless’ framework, and the one that recognizes that Serverless is more than FaaS, and provides plugins and native resource support for other services — even ‘serverless’ doesn’t cover the end-to-end wiring complexity of a serverless solution. Take the canonical HelloRetail serverless project code and inspect how much complexity is left-out. The “project”, the services’ dependencies on JPaaS and each other, the deployment order, event types and schemas and many more are not covered by the framework. They are partially scripted, partially documented, but mainly residing in the heads of the “uber-architects” or as tribal knowledge (which, in software, is also known as “trouble knowledge”).
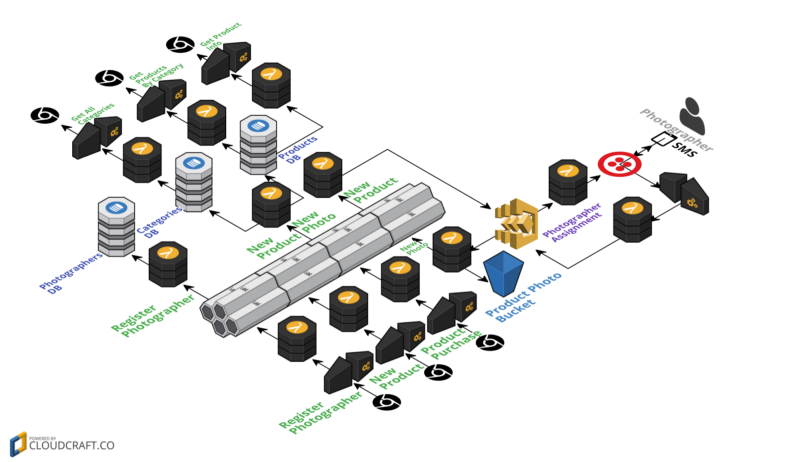
What about DevOps? Shouldn’t it help? The answer is NO, or, at least, not entirely. For one thing, DevOps folks obviously don’t flock around serverless nearly as much as they do around kubernetes. Why so? Maybe our maker-persona DevOps friends just don’t have enough infrastructure knobs and levers to tinker with? Or maybe the reason is more fundamental: DevOps is a response to another problem space — microservices — and not fully applicable to serverless as many microservice assumptions no longer hold. Taking away “ssh to the box” alone retires half of DevOps tooling. Even Terraform, built to codify cloud infrastructures, is somehow not nearly in as much favor in the Serverless community as it is in microservices DevOps.
As the result, serverless today lacks the established operational frameworks, patterns, and tooling that are required to tame it’s complexity. It requires an uber-architect to invent the end-to-end solution and tame complexity. These uber-architects are blazing the path and show success and helping the patterns emerge. But as Anne from Gartner pointed out at the (Emit) conference panel, there will be no widespread serverless adoption until the frameworks and tooling catch up.
Like many times before, challenge is an opportunity. DevOps came to tame complexity of micro-services and made cloud apps “possible”. Something is coming to tame complexity of serverless and make cloud apps “economical”. Whatever it is, it’s gonna be big. When it comes to $, economical forces work flawlessly. The cost saving benefits of serverless are so clear and so substantial, and the push from all major cloud vendors towards serverless is so strong, that it won’t be long before the complexity is tamed and serverless becomes mainstream in all the areas where it applies.
Thanks for reading. Please share your comments and your thoughts on the future of serverless here and on Twitter. And if you enjoyed reading this and want me to write more articles like it, just tap the “clap” button.
PS. You may be insterested in Hackernews discussion and comments on this article.