
By K. Delphino
Recently, after watching the Recommender Systems class of Prof. Andrew Ng’s Machine Learning course, I found myself very discomforted not understanding how Matrix Factorization works.
I know sometimes the math in Machine Learning is very obscure. It’s better if we think about it as a black box, but that model was very “magical” for my standards.
In such situations, I usually try to search on Google for more references to better grasp the concept. This time I got even more confused. While Prof. Ng called the algorithm as (Low Factor) Matrix Factorization, I found a different nomenclature on the internet: Singular Value Decomposition.
What confused me the most was that Singular Value Decomposition was very different from what Prof. Ng had taught. People kept suggesting they were both the same thing.
In this text, I will summarize my findings and try to clear up some of the confusion those terms can cause.
Recommender Systems
Recommender Systems (RS) are just automated ways to recommend something to someone. Such systems are broadly used by e-commerce companies, streaming services and news websites. It helps to reduce the friction of users when trying to find something they like.
RS are definitely not a new thing: they have been featured since at least 1990. In fact, part of the recent Machine Learning hype can be attributed to interest in RS. In 2006, Netflix made a splash when they sponsored a competition to find the best RS for their movies. As we will see soon, that event is related to the nomenclature mess that followed.
The matrix representation
There are a lot of ways a person can think of recommending a movie to someone. One strategy that turned out to be very good is treating movie ratings as a Users x Movies matrix like this:
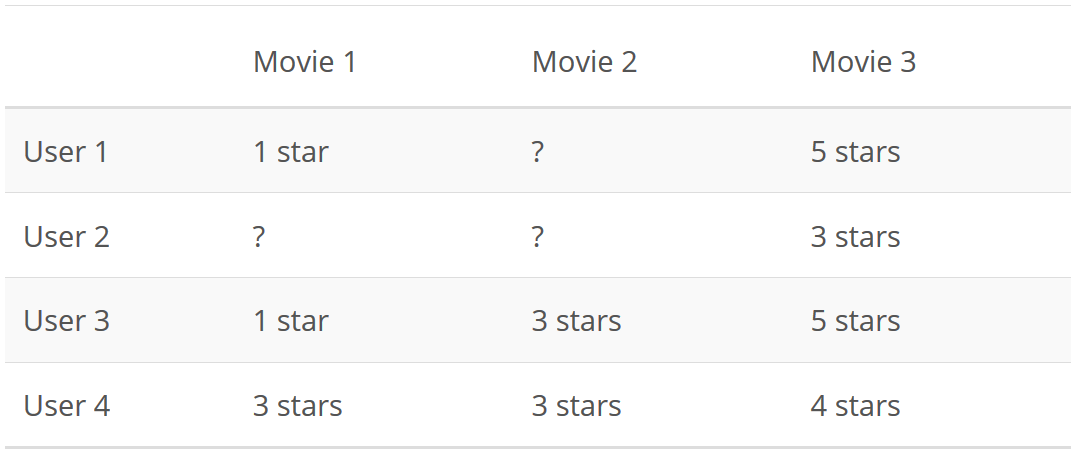
Created with https://sheetsu.com/
In that matrix, the question marks represent the movies a user has not rated. The strategy then is to predict those ratings somehow and recommend to users the movies they will probably like.
Matrix Factorization
A really smart realization made by the guys who entered the Netflix’s competition (notably Simon Funk) was that the users’ ratings weren’t just random guesses. Raters probably follow some logic where they weight the things they like in a movie (a specific actress or a genre) against things they don’t like (long duration or bad jokes) and then come up with a score.
That process can be represented by a linear formula of the following kind:
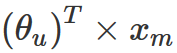
where xₘ is a column vector with the values of the features of the movie m and θᵤ is another column vector with the weights that user u gives to each feature. Each user has a different set of weights and each film has a different set of values for its features.
It turns out that if we arbitrarily fix the number of features and ignore the missing ratings, we can find a set of weights and features values that create a new matrix with values close to the original rating matrix. This can be done with gradient descent, very much like the one used in linear regression. Instead of that now we are optimizing two sets of parameters (weights and features) at the same time.
Using the table I gave as an example above, the result of the optimization problem would generate the following new matrix:
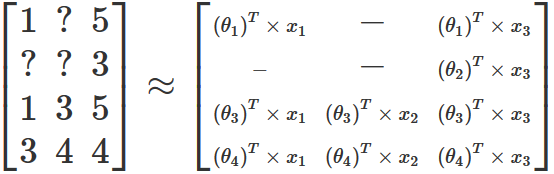
Notice that the resulting matrix can’t be an exact copy of the original one in most real datasets because in real life people are not doing multiplications and summations to rate a movie. In most cases, the rating is just a gut feeling that can also be affected by all kinds of external factors. Still, our hope is that the linear formula is a good way to express the main logic that drives users ratings.
OK, now we have an approximate matrix. But how the heck does that help us to predict the missing ratings? Remember that to build the new matrix, we created a formula to fill all the values, including the ones that are missing in the original matrix. So if we want to predict the missing rating of a user on a movie, we just take all the feature values of that movie, multiply by all the weights of that user and sum everything up. So, in my example, if I want to predict User 2’s rating of Movie 1, I can do the following calculation:
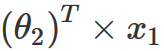
To make things clearer, we can disassociate the _θ’_s and _x’_s and put them into their own matrices (say P and Q). That is effectively a Matrix Factorization, hence the name used by Prof. Ng.
That Matrix Factorization is basically what Funk did. He got third place in Netflix’s competition, attracting a lot of attention (which is an interesting case of a third place being more famous than the winners). His approach has been replicated and refined since then and is still in use in many applications.
Singular Value Decomposition
Enter Singular Value Decomposition (SVD). SVD is a fancy way to factorizing a matrix into three other matrices (A = UΣVᵀ). The way SVD is done guarantees those 3 matrices carry some nice mathematical properties.
There are many applications for SVD. One of them is Principal Component Analysis (PCA), which is just reducing a dataset of dimension n to dimension k (k < n).
I won’t give you any further detail on SVDs because I don’t know myself. The point is that it’s not the same thing as we did with Matrix Factorization. The biggest evidence is that SVD creates 3 matrices while Funk’s Matrix Factorization creates only 2.
So why SVD keeps popping up every time I search for Recommender Systems? I had to dig a little bit, but eventually, I found some hidden gems. According to Luis Argerich:
The matrix factorization algorithms used for recommender systems try to find two matrices: P,Q such as P*Q matches the KNOWN values of the utility matrix.
This principle appeared in the famous SVD++ “Factorization meets the neighborhood” paper that unfortunately used the name “SVD++” for an algorithm that has absolutely no relationship with the SVD.
For the record, I think Funk, not the authors of SVD++, first proposed the mentioned matrix factorization for recommender systems. In fact, SVD++, as its name suggests, is an extension of Funk’s work.
Xavier Amatriain gives us a bigger picture:
Let’s start by pointing out that the method usually referred to as “SVD” that is used in the context of recommendations is not strictly speaking the mathematical Singular Value Decomposition of a matrix but rather an approximate way to compute the low-rank approximation of the matrix by minimizing the squared error loss. A more accurate, albeit more generic, way to call this would be Matrix Factorization. The initial version of this approach in the context of the Netflix Prize was presented by Simon Funk in his famous Try This at Home blogpost. It is important to note that the “true SVD” approach had been indeed applied to the same task years before, with not so much practical success.
Wikipedia also has similar information buried in its Matrix factorization (recommender systems) article:
The original algorithm proposed by Simon Funk in his blog post factorized the user-item rating matrix as the product of two lower-dimensional matrices, the first one has a row for each user, while the second has a column for each item. The row or column associated with a specific user or item is referred to as latent factors. Note that, despite its name, in FunkSVD no singular value decomposition is applied.
To summarize:
SVD is a somewhat complex mathematical technique that factorizes matrices intro three new matrices and has many applications, including PCA and RS.
Simon Funk applied a very smart strategy in the 2006 Netflix competition, factorizing a matrix into two other ones and using gradient descent to find optimal values of features and weights. It’s not SVD, but he used that term anyway to describe his technique.
The more appropriate term for what Funk did is Matrix Factorization.
Because of the good results and the fame that followed, people still call that technique SVD because, well, that’s how the author named it.
I hope this helps to clarify things a bit.