
By Sacha Greif
If you’re like me, you probably go through three stages when hearing about a new technology:
1. Dismissal
One more JavaScript library?! Just use jQuery already!
2. Interest
Hmm, maybe I should check out this new library I keep hearing about…
3. Panic
Help! I need to learn this new library right now or I’ll be completely obsolete!
The trick to maintaining your sanity in these fast-moving times is to learn new stuff right between stages two and three, once your interest is piqued but while you’re still ahead of the curve.
Which is why now is the perfect time to learn what exactly this GraphQL thing you keep hearing about really is.
The Basics
In a nutshell, GraphQL is a syntax that describes how to ask for data, and is generally used to load data from a server to a client. GraphQL has three main characteristics:
- It lets the client specify exactly what data it needs.
- It makes it easier to aggregate data from multiple sources.
- It uses a type system to describe data.
So how did GraphQL get started? What does it look like in practice? And how do you start using it? Read on to find out!
The Problem
GraphQL got its start at big old Facebook, but even much simpler apps can often bump into the limitations of traditional REST APIs.
For example, imagine you need to display a list of posts, and under each post a list of likes, including user names and avatars. Easy enough, you tweak your posts API to include a likes array containing user objects:

But now, it’s time to work on your mobile app, and it turns out loading all that extra data is slowing things down. So you now need two endpoints, one with the likes and one without them.
Now add one more factor to the mix: it turns out that while posts are stored in a MySQL database, likes on the other hand live in a Redis store! What do you do now?!
Extrapolate this scenario to however many data sources and API clients Facebook has to manage, and you can imagine why good old REST APIs were starting to show their limits.
The Solution
The solution Facebook came up with is conceptually very simple: instead of having multiple “dumb” endpoints, have a single “smart” endpoint that can take in complex queries, and then massage the data output into whatever shape the client requires.
Practically speaking, the GraphQL layer lives between the client and one or more data sources, receiving client requests and fetching the necessary data according to your instructions. Confused? It’s metaphor time!
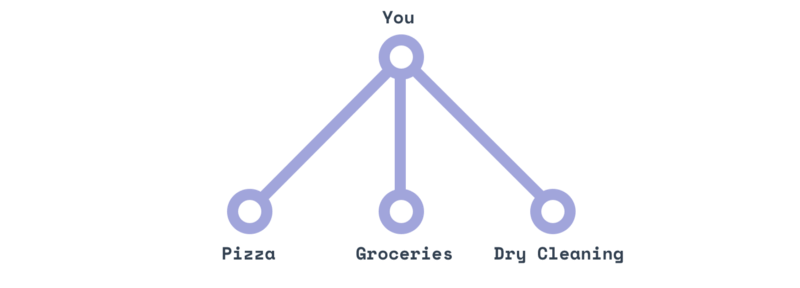
The old REST model is like ordering pizza, then getting groceries delivered, then calling your dry cleaner to get your clothes. Three shops, three phone calls.
GraphQL on the other hand is like having a personal assistant: once you’ve given them the addresses to all three places, you can simply ask for what you want (“get me my dry cleaning, a large pizza, and two dozen eggs”) and wait for them to return.
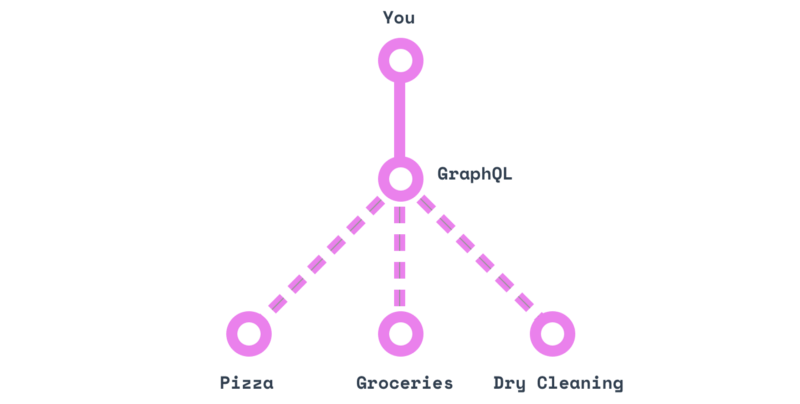
In other words, GraphQL establishes a standard language for talking to this magical personal assistant.

In practice, a GraphQL API is organized around three main building blocks: the schema, queries, and resolvers.
Queries
The request you make to your GraphQL personal assistant is the query, and it looks something like this:
query { stuff}
We’re declaring a new query using the query keyword, then asking for a field named stuff. The great thing about GraphQL queries is that they support nested fields, so we can go one level deeper:
query { stuff { eggs shirt pizza }}
As you can see, the client making the query doesn’t need to care which “shop” the data is coming from. Just ask for what you need, and let the GraphQL server take care of the rest.
It’s worth noting that query fields can also point to arrays. For example, here’s a common pattern when querying for a list of posts:
query { posts { # this is an array title body author { # we can go deeper! name avatarUrl profileUrl } }}
Query fields also support arguments. If I want to display a specific post, I can add an id argument to the post field:
query { post(id: "123foo"){ title body author{ name avatarUrl profileUrl } }}
Finally, if I want to make that id argument dynamic, I can define a variable and then reuse it inside the query (note that we’re also naming the query here):
query getMyPost($id: String) { post(id: $id){ title body author{ name avatarUrl profileUrl } }}
A good way to put all this in practice is to use GitHub’s GraphQL API Explorer. For example, give the following query a try:
query { repository(owner: "graphql", name: "graphql-js"){ name description }}
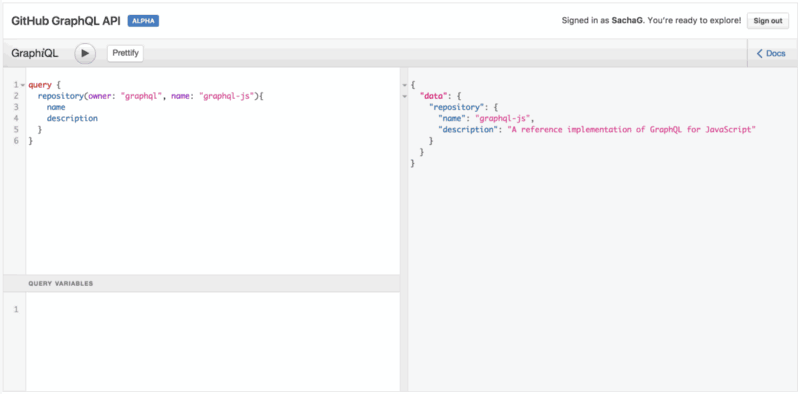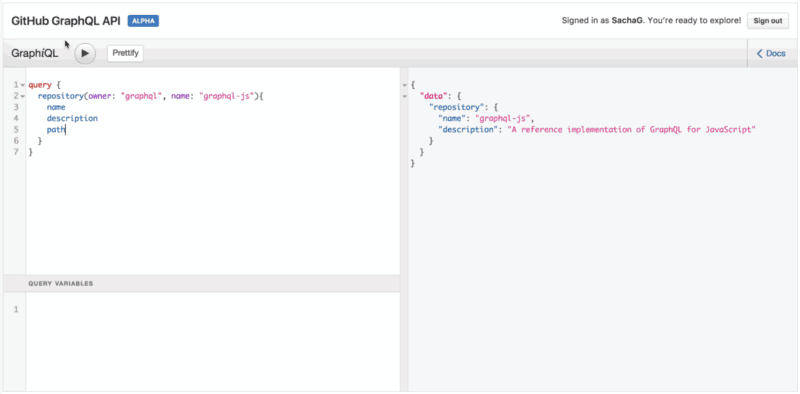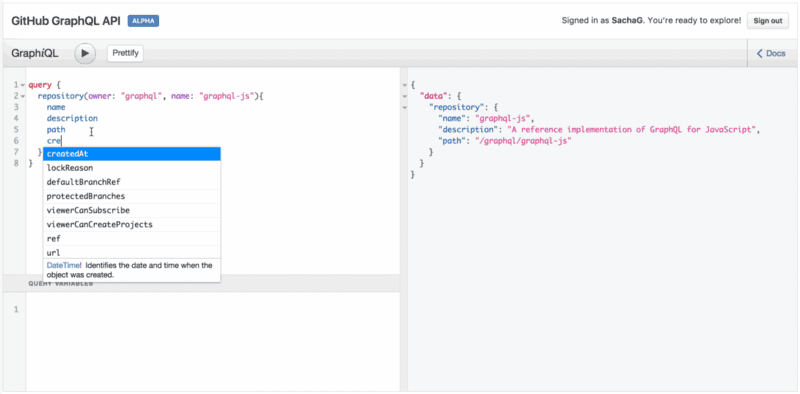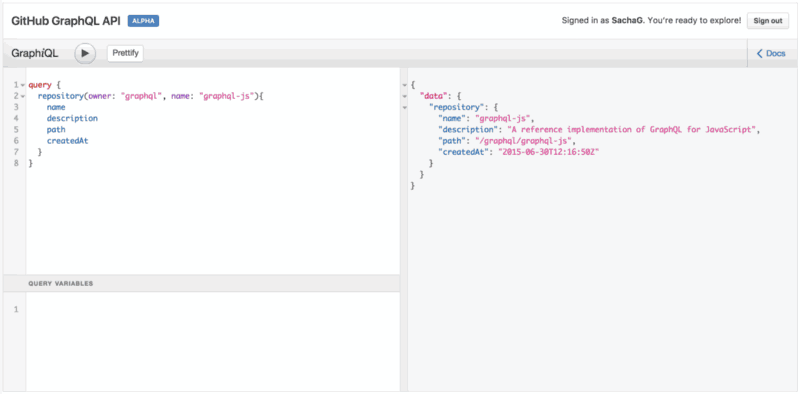
Notice that as you try typing a new field name below description, the IDE will automatically offer possible field names directly auto-completed from the GraphQL API itself. Neat!
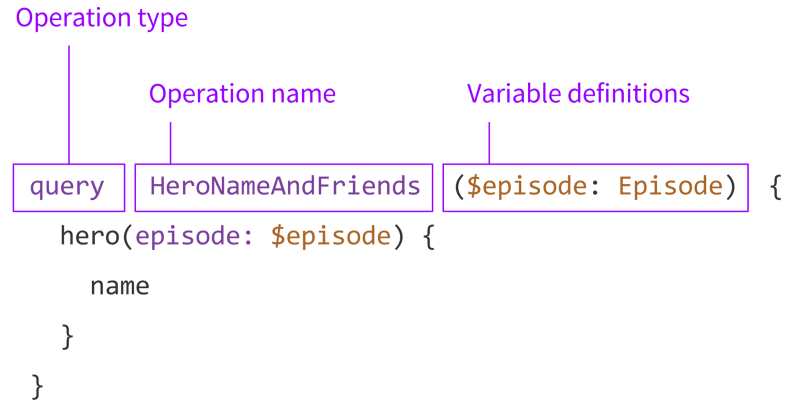
You can learn more about GraphQL queries in the excellent Anatomy of a GraphQL Query article.
Resolvers
Even the best personal assistant in the world can’t go and get your dry cleaning unless you give them an address.
Similarly, your GraphQL server won’t know what to do with an incoming query unless you tell it using a resolver.
A resolver tells GraphQL how and where to fetch the data corresponding to a given field. For example, here’s what a resolver for the post field above could look like (using Apollo’s GraphQL-Tools schema generator):
Query: { post(root, args) { return Posts.find({ id: args.id }); }}
We’re putting the resolver on Query because we want to query for post directly at the root level. But you can also have resolvers for sub-fields, such as a post's author field:
Query: { post(root, args) { return Posts.find({ id: args.id }); }},Post: { author(post) { return Users.find({ id: post.authorId}) }}
And note that your resolvers are not limited to returning database documents. For example, maybe you want to add a commentsCount to your Post type:
Post: { author(post) { return Users.find({ id: post.authorId}) }, commentsCount(post) { return Comments.find({ postId: post.id}).count() }}
The key concept to understand here is that with GraphQL, your API schema and your database schemas are decoupled. In other words, there might not be any author and commentsCount fields in our database, but we can “simulate” them through the power of resolvers.
As you’ve seen you can write any code you want inside a resolver. Which is why you can also make them modify the contents of your database, in which case they’re known as mutation resolvers.
Schema
All this good stuff is made possible by GraphQL’s typed schema system. My goal today is to give you a quick overview more than an exhaustive introduction, so I won’t go into details here.
That being said, I encourage you to check out the GraphQL documentation if you’d like to learn more.

Frequently Asked Questions
Let’s take a break to answer a few common questions.
You there, in the back. Yes, you. I can see you want to ask something. Go ahead, don’t be shy!
What’s the relation between GraphQL and graph databases?
Not much, really, GraphQL doesn’t have anything to do with graph databases like Neo4j. The “graph” part comes from the idea of crawling across your API graph by using fields and subfields; while “QL” stands for “query language”.
I’m perfectly happy with REST, why should I switch to GraphQL?
If you haven’t yet bumped into the REST pain points that GraphQL is meant to address, then I would say that’s a good thing!
Using GraphQL over REST probably won’t affect your app’s overall user experience that much, so switching to it isn’t a matter of life or death by any means. That being said, I’d definitely recommend trying out GraphQL on a small side project if you ever get the chance.
Can I use GraphQL without React/Relay/insert library here?
Yes you can! Since GraphQL is just a specification, you can use it with any library on any platform, either with a client (for example, Apollo has GraphQL clients for the web, iOS, Angular, etc.) or by making your own calls to a GraphQL server.
GraphQL was made by Facebook, and I don’t trust Facebook
Again, GraphQL is a specification, meaning you can use GraphQL implementations without running a single line of code written by Facebook.
And while having Facebook’s support is definitely a nice plus for the GraphQL ecosystem, at this point I believe the community is big enough for GraphQL to thrive even if Facebook were to stop using it.
This whole “let the client ask for the data they need” business doesn’t sound very secure to me…
Since you write your own resolvers, it’s up to you to address any security concerns at that level.
For example, if you let the client specify a limit parameter to control the number of documents it receives, you’ll probably want to cap that number to avoid denial-of-service-style attacks where clients requests millions of documents over and over.
So what do I need to get started?
Generally speaking, you’ll need at least two components to run a GraphQL-powered app:
- A GraphQL server that serves your API.
- A GraphQL client that connects to your endpoint.
Read on to learn more about the various options available.

Now that you have a fair idea of how GraphQL works, let’s talk about some of the main players in the space.
GraphQL Servers
The first brick you’ll need is a GraphQL server. GraphQL itself is just a specification after all, so this leaves the door open to a few competing implementations.
GraphQL-JS (Node)
This is the original reference implementation of GraphQL. You can use it together with express-graphql to create your API server.
GraphQL-Server (Node)
The Apollo team also has their own all-in-one GraphQL server implementation. It’s not as widespread as the original yet, but is very well documented and supported and quickly gaining ground.
Other Platforms
GraphQL.org has a list of GraphQL implementations for various other platforms (PHP, Ruby, etc.).
GraphQL Clients
Although you can technically query your GraphQL API directly without the need for a dedicated client library, it can definitely make your life easier.
Relay
Relay is Facebook’s own GraphQL toolkit. I haven’t used it myself, but from what I’ve heard it’s mainly tailored to Facebook’s own needs, and might be a bit over-engineered for most usages.
Apollo Client
The new entrant in this space is Apollo, and it’s quickly taken over. The typical Apollo client stack is composed of two bricks:
- Apollo-client, which lets you run GraphQL queries in the browser and store their data (and also has its own devtools extension).
- A connector for your front-end framework of choice (React-Apollo, Angular-Apollo, etc.).
Note that by default, Apollo-client stores its data using Redux, which is great since Redux is itself a pretty established state management library with a rich ecosystem.
Open-Source Apps
Even though GraphQL is fairly new, there are already some promising open-source apps making use of it.
VulcanJS

First, a disclaimer: I’m the lead maintainer of VulcanJS. I created VulcanJS to let people take advantage of the power of the React/GraphQL stack without having to write so much boilerplate. You can think of it as “Rails for the modern web ecosystem”, in that it lets you build CRUD apps (such as an Instagram clone) in a matter of hours.
Gatsby
Gatsby is a React static site generator, which is now powered by GraphQL as of version 1.0. While that might seem like an odd combination at first, it’s actually quite powerful. During its build process, Gatsby can fetch data from multiple GraphQL APIs, and then use them to create a fully static client-only React app.
Other GraphQL Tools
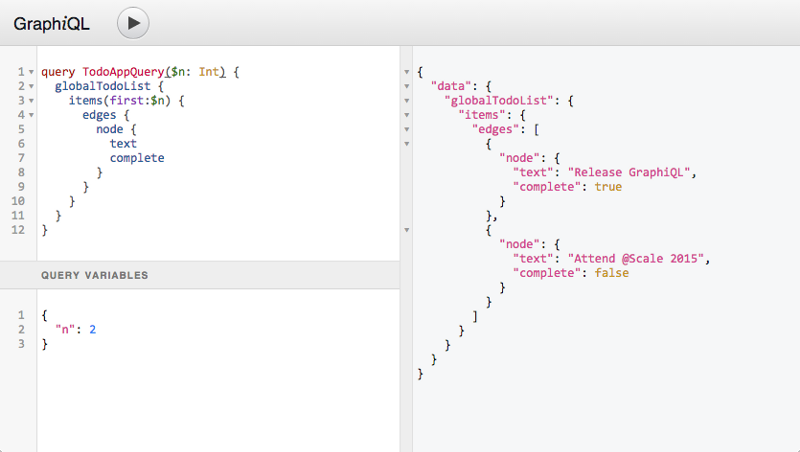
GraphiQL
GraphiQL is a very handy in-browser IDE for querying GraphQL endpoints.
DataLoader
Due to the nested nature of GraphQL queries, a single query can easily trigger dozens of database calls. To avoid taking a performance hit, you can use a batching and caching library such as DataLoader, developed by Facebook.
Create GraphQL Server
Create GraphQL Server is a command line utility that makes it easy to quickly scaffold a GraphQL server powered by a Node server and a Mongo database.
GraphQL-up
Similar to Create GraphQL Server, GraphQL-up lets you quickly bootstrap a new GraphQL back-end powered by GraphCool’s service.
GraphQL Services
Finally, there are also a number of “GraphQL-backend-as-a-service” companies that take care of the whole server side of things for you, and might be a nice way to dip your toes in the GraphQL ecosystem.
Graphcool
A flexible backend platform combining GraphQL and AWS Lambda, with a free developer plan.
Scaphold
Another GraphQL backend as a service, which also has a free plan. It offers a lot of the same features as Graphcool.
There are already quite a few places where you can brush up on GraphQL.
GraphQL.org
The official GraphQL site has some great documentation to get you started.
LearnGraphQL
LearnGraphQL is an interactive course put together by the folks at Kadira.
LearnApollo
A good follow-up to LearnGraphQL, LearnApollo is a free course made by Graphcool.
The Apollo Blog
The Apollo blog has tons of detailed, well-written posts about Apollo and GraphQL in general.
GraphQL Weekly
A newsletter about all things GraphQL curated by the Graphcool team.
Hashbang Weekly
Another great newsletter, which also covers React and Meteor in addition to GraphQL.
Freecom
A tutorial series teaching you how to build an Intercom clone using GraphQL.
Awesome GraphQL
A pretty exhaustive list of GraphQL links and resources.
So how do you put your newly acquired GraphQL knowledge in practice? Here are a few recipes you can try:
Apollo + Graphcool + Next.js
If you’re already familiar with Next.js and React, this example will let you set up your GraphQL endpoint using Graphcool, and then query it using Apollo.
VulcanJS
The Vulcan tutorial will take you through setting up a simple GraphQL data layer, both on the server and client. Since Vulcan is an all-in-one platform, it’s a nice way to get started without any setup. If you need help, don’t hesitate to drop by our Slack channel!
GraphQL & React Tutorial
The Chroma blog has a six-part tutorial on building a React/GraphQL app following a component-driven development approach.

Conclusion
GraphQL might seem complex at first because it’s a technology that reaches across many areas of modern development. But if you take the time to understand the underlying concepts, I think you’ll find out that a lot of it just makes sense.
So whether you end up actually using it or not, I believe it’s worth taking the time to familiarize yourself with GraphQL. More and more companies and frameworks are adopting it, and it might very well end up becoming one of the key building blocks of the web over the next few years.
Agree? Disagree? Questions? Just let me know here in the comments. And if you’ve enjoyed this article, please consider ?ing and sharing it!