
By Kirill Dubovikov
Inference
Statistical Inference is a very important topic that powers modern Machine Learning and Deep Learning algorithms. This article will help you to familiarize yourself with the concepts and mathematics that make up inference.
Imagine we want to trick some friends with an unfair coin. We have 10 coins and want to judge whether any one of them is unfair — meaning it will come up as heads more often than tails, or vice versa.
So we take each coin, toss it a bunch of times — say 100 — and record the results. The thing is we now have a subset of measurements from a true distribution (a sample) for each coin. We’ve considered the condition of our thumbs and concluded that collecting more data would be very tedious.
It is uncommon to know parameters of the true distribution. Frequently, we want to infer true population parameters them from the sample.
So now we want to estimate the probability of a coin landing on Heads. We are interested in the sample mean.
By now you’ve likely thought, “Just count number of heads and divide by the total number of attempts already!” Yep, this is the way to find an unfair coin, but how could we come up with this formula if we didn’t know it in the first place?
Frequentist Inference
Recall that coin tosses are best modeled with Bernoulli distribution, so we are sure that it represents our data well. Probability Mass Function (PMF) for Bernoulli distribution looks like this:
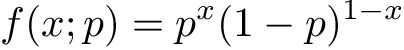
x is a random variable that represents an observation of a coin toss (assume 1 for Heads and 0 for Tails) and p is a parameter — probability of Heads. We will refer to all possible parameters as θ onward. This function represents how probable each value of x is according to the distribution law we have chosen.
When x is equal to 1 we get f(1; p) = p, and when it is zero f(0; p) = 1-p. Thus, Bernoulli distribution answers the question ‘How probable is it that we get a heads with a coin that lands on heads with probability p?’. Actually, it is one of the simplest examples of a discrete probability distribution.
So, we are interested in determining parameter p from the data. A frequentist statistician will probably suggest using a Maximum Likelihood Estimation (MLE) procedure. This method takes approach of maximizing likelihood of parameters given the dataset D:
![]()
This means that likelihood is defined as a probability of the data given parameters of the model. To maximize this probability, we will need to find parameters that help our model to match the data as close as possible. Doesn’t it look like learning? Maximum Likelihood is one of the methods that make supervised learning work.
Now let’s assume all observations we make are independent. This means that joint probability in the expression above may be simplified to a product by basic rules of probability:
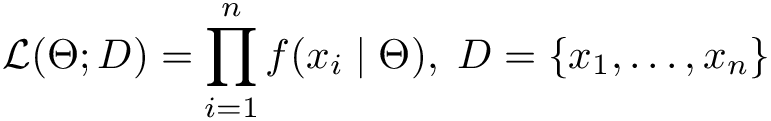
Now goes the main part: how do we maximize a likelihood function? We call calculus for help, differentiate likelihood function in respect to model parameters θ, set it to 0 and solve the equation. There is a neat trick that makes differentiation much easier most of the times — logarithms do not change function’s extrema (minimum and maximum).
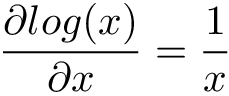
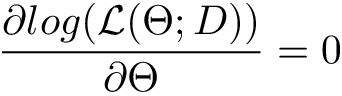
Maximum Likelihood Estimation has immense importance and almost every machine learning algorithm. It is one of the most popular ways to formulate a process of learning mathematically.
And now let’s apply what we’ve learned and play with our coins. We’ve done n independent Bernoulli trials to evaluate the fairness of our coin. Thus, all probabilities can be multiplied and likelihood function will look like this:
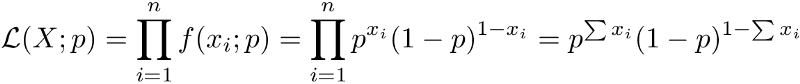
Taking the derivative of the expression above won’t be nice. So, we need to find the log-likelihood:
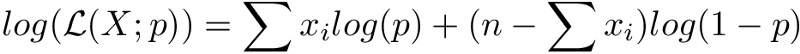
That looks easier. Moving on to differentiation
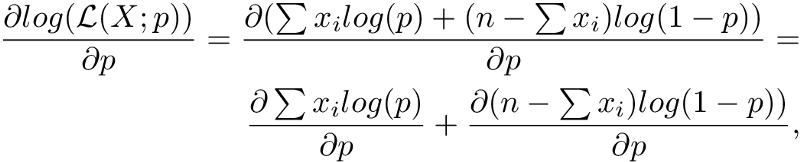
Here we split derivatives using standard d(f + g) = df + dg. Next, we move the constants out and differentiate logarithms:
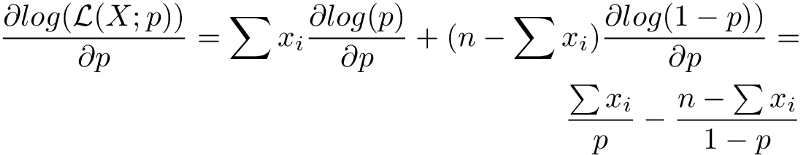
The last step might seem funny because of the sign flip. The cause is that log(1-p) is actually a composition of two functions and we must use the chain rule here:
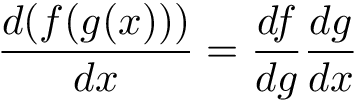 By the way, try to get familiar with the chain rule. It is a very useful tool. And it has vast importance in neural networks.
By the way, try to get familiar with the chain rule. It is a very useful tool. And it has vast importance in neural networks.
Voilà, we are done with the log-likelihood! Now we are close to find the maximum likelihood statistic for the mean of Bernoulli distribution. The last step is to solve the equation:
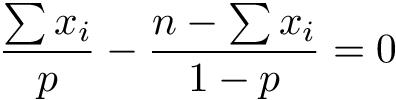
Multiplying everything by p(1-p) and expanding parenthesis we get
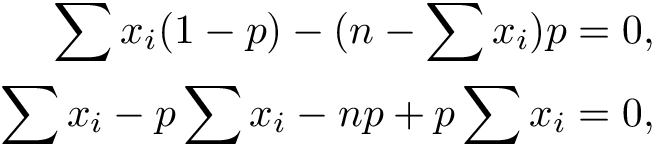
Canceling out the terms and rearranging:
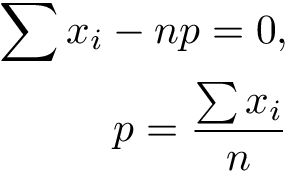
So, here is the derivation of our intuitive formula ?. _Y_ou may now play with Bernoulli distribution and its MLE estimate of the mean in the visualization below
Congratulations on your new awesome skill of Maximum Likelihood Estimation! Or just for refreshing your existing knowledge.
Bayesian Inference

Recall that there exists another approach to probability. Bayesian statistics has its own way to do probabilistic inference. We want to find the probability distribution of parameters THETA given sample — P(THETA | D). But how can we infer this probability? Bayes theorem comes to rescue:
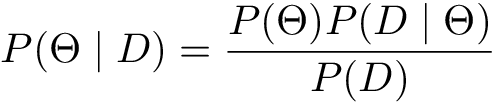
- P(θ) is called a prior distribution and incorporates our beliefs in what parameters could be before we have seen any data. The ability to state prior beliefs is one of the main differences between maximum likelihood and Bayesian inference. However, this is also the main point of criticism for the Bayesian approach. How do we state the prior distribution if we do not know anything about the problem in interest? What if we choose bad prior?
- P(D | θ) is a likelihood, we have encountered it in Maximum Likelihood Estimation
- P(D) is called evidence or marginal likelihood
P(D) is also called normalization constant since it makes sure that results we get are a valid probability distribution. If we rewrite P(D) as
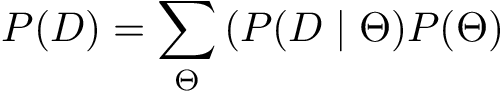
We will see that it is similar to the numerator in the Bayes Theorem, but the summation goes over all possible parameters θ. This way we get two things:
- The output is always valid probability distribution in the domain of [0, 1].
- Major difficulties when we try to compute P(D) since this requires integrating or summing over all possible parameters. This is impossible in most of the real word problems.
But does marginal likelihood P(D) make all things Bayesian impractical? The answer is not quite. In most of the times, we will use one of the two options to get rid of this problem.
The first one is to somehow approximate P(D). This can be achieved by using various sampling methods like Importance Sampling or Gibbs Sampling, or a technique called Variational Inference (which is a cool name by the way ?).
The second is to get it out of the equation completely. Let’s explore this approach in more detail. What if we concentrate on finding one most probable parameter combination (that is the best possible one)? This procedure is called Maximum A Posteriori estimation (MAP).
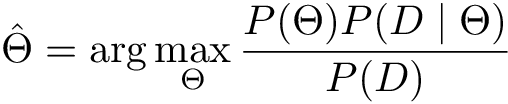
The equation above means that we want to find θ for which expression inside arg max takes its maximum value — the _arg_ument of a maximum. The main thing to notice here is that P(D) is independent of parameters and may be excluded from arg max:
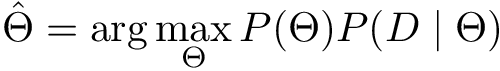
In other words, P(D) will always be constant with respect to model parameters and its derivative will be equal to 1.
This fact is so widely used that it is common to see Bayes Theorem written in this form:
![]()
The wired incomplete infinity sign in the expression above means “proportional to” or “equal up to a constant”.
Thus, we have removed the most computationally heavy part of the MAP. This makes sense since we basically discarded all possible parameter values from probability distribution and just skimmed off the best most probable one.
A link between MLE and MAP
And now consider what happens when we assume the prior to be uniform (a constant probability).
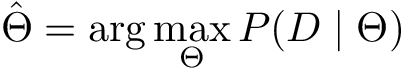
We have moved out constant C out of the arg max since it does not affect the result as it was with the evidence. It certainly looks alike to a Maximum Likelihood estimate! In the end, the mathematical gap between frequentist and Bayesian inference is not that large.
We can also build the bridge from the other side and view maximum likelihood estimation through Bayesian glasses. In specific, it can be shown that Bayesian priors have close connections with regularization terms. But that topic deserves another post (see this SO question and ESLR book for more details).
Conclusion
 XKCD comic on Frequentist vs Bayesian
XKCD comic on Frequentist vs Bayesian
Those differences may seem subtle at first, but they give a start to two schools of statistics. Frequentist and Bayesian approaches differ not only in mathematical treatment but in philosophical views on fundamental concepts in stats.
If you take on a Bayesian hat you view unknowns as probability distributions and the data as non-random fixed observations. You incorporate prior beliefs to make inferences about events you observe.
As a Frequentist, you believe that there is a single true value for the unknowns that we seek and it’s the data that is random and incomplete. Frequentist randomly samples data from unknown population and makes inferences about true values of unknown parameters using this sample.
In the end, Bayesian and Frequentist approaches have their own strengths and weaknesses. Each has the tools to solve almost any problem the other can. Like different programming languages, they should be considered as tools of equal strength that may be a better fit for a certain problem and fall short at the other. Use them both, use them wisely, and do not fall into the fury of a holy war between two camps of statisticians!
Learned something? Click the ? to say “thanks!” and help others find this article.
