
According to OpenCV's "Introduction to Support Vector Machines", a Support Vector Machine (SVM):
...is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples.
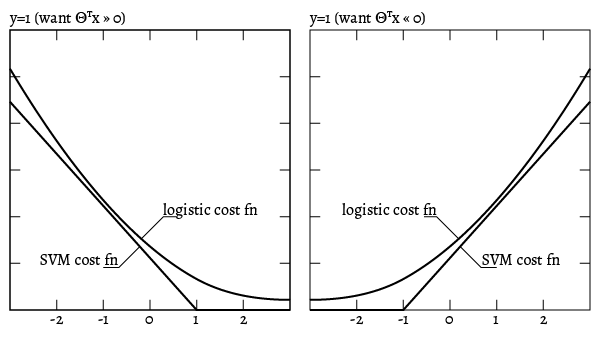
An SVM cost function seeks to approximate the logistic function with a piecewise linear. This machine learning algorithm is used for classification problems and is part of the subset of supervised learning algorithms.
The Cost Function
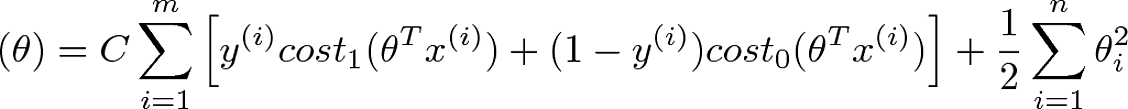
The Cost Function is used to train the SVM. By minimizing the value of J(theta), we can ensure that the SVM is as accurate as possible. In the equation, the functions cost1 and cost0 refer to the cost for an example where y=1 and the cost for an example where y=0. For SVMs, cost is determined by kernel (similarity) functions.
Kernels
Polynomial features tend to be computationally expensive, and may increase runtime with large datasets. Instead of adding more polynomial features, it's better to add landmarks to test the proximity of other datapoints against. Each member of the training set can be considered a landmark, and a kernel is the similarity function that measures how close an input is to said landmarks.
Large Margin Classifier
An SVM will find the line or hyperplane that splits the data with the largest margin possible. Though there will be outliers that sway the line in a certain direction, a C value that is small enough will enforce regularization throughout.
The following is code written for training, predicting and finding accuracy for SVM in Python:
import numpy as np
class Svm (object):
"""" Svm classifier """
def __init__ (self, inputDim, outputDim):
self.W = None
# - Generate a random svm weight matrix to compute loss #
# with standard normal distribution and Standard deviation = 0.01. #
sigma =0.01
self.W = sigma * np.random.randn(inputDim,outputDim)
def calLoss (self, x, y, reg):
"""
Svm loss function
D: Input dimension.
C: Number of Classes.
N: Number of example.
Inputs:
- x: A numpy array of shape (batchSize, D).
- y: A numpy array of shape (N,) where value < C.
- reg: (float) regularization strength.
Returns a tuple of:
- loss as single float.
- gradient with respect to weights self.W (dW) with the same shape of self.W.
"""
loss = 0.0
dW = np.zeros_like(self.W)
# - Compute the svm loss and store to loss variable. #
# - Compute gradient and store to dW variable. #
# - Use L2 regularization #
#Calculating score matrix
s = x.dot(self.W)
#Score with yi
s_yi = s[np.arange(x.shape[0]),y]
#finding the delta
delta = s- s_yi[:,np.newaxis]+1
#loss for samples
loss_i = np.maximum(0,delta)
loss_i[np.arange(x.shape[0]),y]=0
loss = np.sum(loss_i)/x.shape[0]
#Loss with regularization
loss += reg*np.sum(self.W*self.W)
#Calculating ds
ds = np.zeros_like(delta)
ds[delta > 0] = 1
ds[np.arange(x.shape[0]),y] = 0
ds[np.arange(x.shape[0]),y] = -np.sum(ds, axis=1)
dW = (1/x.shape[0]) * (x.T).dot(ds)
dW = dW + (2* reg* self.W)
return loss, dW
def train (self, x, y, lr=1e-3, reg=1e-5, iter=100, batchSize=200, verbose=False):
"""
Train this Svm classifier using stochastic gradient descent.
D: Input dimension.
C: Number of Classes.
N: Number of example.
Inputs:
- x: training data of shape (N, D)
- y: output data of shape (N, ) where value < C
- lr: (float) learning rate for optimization.
- reg: (float) regularization strength.
- iter: (integer) total number of iterations.
- batchSize: (integer) number of example in each batch running.
- verbose: (boolean) Print log of loss and training accuracy.
Outputs:
A list containing the value of the loss at each training iteration.
"""
# Run stochastic gradient descent to optimize W.
lossHistory = []
for i in range(iter):
xBatch = None
yBatch = None
# - Sample batchSize from training data and save to xBatch and yBatch #
# - After sampling xBatch should have shape (batchSize, D) #
# yBatch (batchSize, ) #
# - Use that sample for gradient decent optimization. #
# - Update the weights using the gradient and the learning rate. #
#creating batch
num_train = np.random.choice(x.shape[0], batchSize)
xBatch = x[num_train]
yBatch = y[num_train]
loss, dW = self.calLoss(xBatch,yBatch,reg)
self.W= self.W - lr * dW
lossHistory.append(loss)
# Print loss for every 100 iterations
if verbose and i % 100 == 0 and len(lossHistory) is not 0:
print ('Loop {0} loss {1}'.format(i, lossHistory[i]))
return lossHistory
def predict (self, x,):
"""
Predict the y output.
Inputs:
- x: training data of shape (N, D)
Returns:
- yPred: output data of shape (N, ) where value < C
"""
yPred = np.zeros(x.shape[0])
# - Store the predict output in yPred #
s = x.dot(self.W)
yPred = np.argmax(s, axis=1)
return yPred
def calAccuracy (self, x, y):
acc = 0
# - Calculate accuracy of the predict value and store to acc variable
yPred = self.predict(x)
acc = np.mean(y == yPred)*100
return acc