
By Chris Williams
I've been meaning to get my Terraform associates certification for some time now, but something always got in the way.
Finally I was able to sit down and work my way through the study materials.
Currently Andrew Brown and I are creating two Terraform Bootcamps: one for beginners and the other one for intermediate practitioners. These bootcamps will be similar to Andrew's AWS Cloud Project Bootcamp (YouTube playlist here).
In this guide, I've compiled my live study notes that I've used for prepping to sit the Terraform Certified Associate Exam to help you know what to study.
Here's what I'll cover:
- Preparation Materials
- How to Use This Guide
- Understand Infrastructure as Code (IaC) concepts
- Understand the purpose of Terraform (vs other IaC tools)
- Understand Terraform Basics
- Use Terraform outside the core workflow
- Interact with Terraform modules
- Use the core Terraform workflow
- Implement and maintain state
- Read, generate, and modify configuration
- Understand Terraform Cloud capabilities
Preparation Materials
In getting ready for any exam, I like to list out the study materials and reference resources that I'm going to be using ahead of time. This allows me to schedule my study time with a bit more discipline.
Here are the materials I've used:
This site has a wealth of information:
 https://developer.hashicorp.com/certifications
https://developer.hashicorp.com/certifications
- The Terraform Associate Prep Tutorials (Free)
 https://developer.hashicorp.com/terraform/tutorials/certification-003
https://developer.hashicorp.com/terraform/tutorials/certification-003
The newly updated freeCodeCamp course by Andrew Brown (Free) 😁
Jumppad.dev and their Terraform-workshop repository (Free)
The Terraform Hands On Labs Udemy course by Bryan Krausen (Paid)
How to Use this Guide
Each of the below sections will cover one of the nine domains specified in the Terraform Review Guide. Read through the documentation, complete the tutorials, and dig into the additional links I've provided.
The sections below are the large, important bits of information that I've culled for each domain, but this study guide is not comprehensive. Depending on how comfortable you are with the domain-specific knowledge, you will need to dive into the links provided in each section to round out your understanding of the material.
Understand Infrastructure as Code (IaC) concepts
Domain 1 covers the broad concepts of IaC. Why do we want to use it? What is it good for? Are there any areas where you would NOT want to use it? What are the different kinds of languages that can be used for IaC and how are the approaches different?
Explain what IaC is:
Manually configuring your infrastructure is fine for prototyping, but is prone to human error at scale (or when you need to provision the same env repeatedly). IaC is a blueprint of your infra and allows you to share/version/inventory/document your infra.
There are two main types of infrastructure:
Declarative = What you see is what you get. It's explicit with 0 chance of misconfiguration:
- Azure only -> ARM Templates, Azure Blueprints
- AWS only -> CloudFormation
- GCP only -> Cloud Deployment Manager
- All of the above (& many others) -> Terraform
Imperative = Uses existing programming languages like Python, JS or Ruby:
- AWS only -> AWS CDK
- AWS, Azure, GCP, K8s -> Pulumi
Terraform supports For loops, dynamic blocks, complex data structures – so it's declarative with some imperative benefits.
The Infrastructure Lifecycle is having clearly defined work phases for planning, designing, building, testing, maintaining and retiring your infrastructure.
Idempotent: a property of some operations such that no matter how many times you execute them, you achieve the same result. Terraform is idempotent because, no matter how many times you run the same configuration file, you will end up with the same expected state.
Configuration Drift: an unexpected configuration change away from what is stated in the config file. Can be due to manual adjustment (console access in prod = BAD 😂), evil h@xx0rs, etc... How do we fix it?
Detect: use a compliance tool like AWS Config, or built-in support e.g. AWS CF Drift Detection, TF statefiles
Correct:
- TF refresh & plan commands
- Manually correct (try not to do this)
- Reprovision (comes with it's own risks)
Prevent:
- use immutable infrastructure
- always create & destroy, never reuse
- use GitOps to version control IaC:
- Create tf file
- commit
- Pull Request
- peer review
- commit to main
- GitHub action triggers build
Mutable vs Immutable infrastructure
Think of mutable infrastructure as (1) building a base image (2) Deploying that base image then (3) configuring the software after deploy.
Think if immutable infrastructure as (1) building a fully installed base image (2) deploying then (3) if a change needs to be made, tearing down that infra and rebuilding it with a new fully installed base image
- Mutable = Develop -> Deploy (VM) -> Configure (e.g. cloud-init)
- Immutable = Develop -> Configure (Packer) -> Deploy
Describe advantages of IaC patterns:
Why is Infrastructure as Code important? It allows you to:
- Build & manage your infra in (relatively 😅) safe, consistent & repeatable ways
- Share & reuse your configurations more easily
- Manage infra on multiple cloud platforms
- Track resource changes
- Use version control (Git, GitHub, etc..) to collaborate with team members
Understand the Purpose of Terraform (vs other IaC tools)
Domain 2 spells out the differences between Terraform and the other IaC offerings available in the market. Agnostic vs Cloud Specific IaC tools each have their own place in the market and you will choose between them based upon your (and your companies) needs.
Explain multi-cloud and provider agnostic benefits:
- Increases fault-tolerance
- Allows for more graceful recovery from cloud provider outages
- Reduces complexity because each provider has its own interfaces, tools, and workflows that Terraform abstracts for you
- Use the same workflow to manage multiple providers and handle cross-cloud dependencies
- Unified resource view
- A technology agnostic approach/workflow
Explain the benefits of state
- State (a statefile) is necessary for Terraform to function
- It is a map referencing a resource in the tf file to an actual resource that is deployed
- For example resource
"aws_instance" "webserver" {}mapping to known instance"i-0dfcf96cceba9bc77"
- For example resource
- Metadata tracking
- resource dependencies
- build/delete order tracking
- Ordering within one provider and across multiple providers -> complexity quickly ramps up
- For larger environments use
-refresh=falseand-targetflags- querying every resource can take too long
- cached state is treated as record of truth
- Use remote state when working in teams
- remote locking prevents 2 admins making simultaneous changes
Understand Terraform Basics
Domain 3 gets into the commands and processes that you will need to understand to leverage Terraform. It covers the installation of Terraform itself, the providers, what modules are, and the basic workflow that you will do when building IaC environments.
Some helpful Terraform CLI cheat codes: terraform -help and terraform (command) -help.
Terraform lifecycle:
- code - create or edit your terraform config file
terraform init- Initialize workspace, pull providers and modulesterraform plan- see what changes will be made (or generate an execution plan) also known as a "dry-run"terraform validate- ensure types, values, and required attributes are valid and presentterraform apply- make the things!terraform destroy- unmake the things! 😱
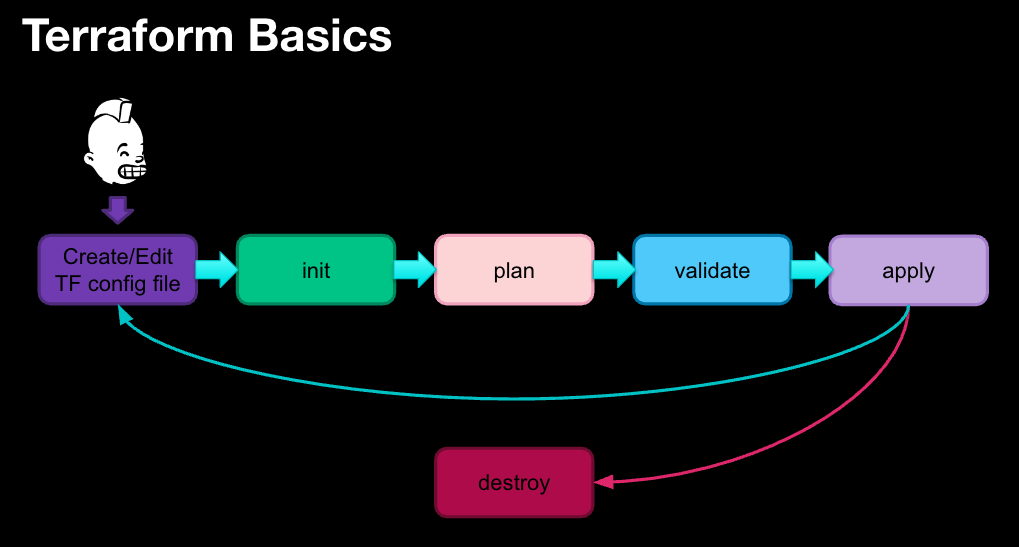 Diagram showing a basic Terraform workflow
Diagram showing a basic Terraform workflow
HCL Syntax:
The syntax of the Terraform language consists of a few standard elements:
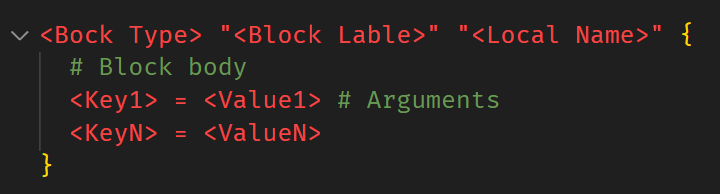 Standard Elements of HCL
Standard Elements of HCL
For example, this is a basic resource block that will spin up an EC2 instance:
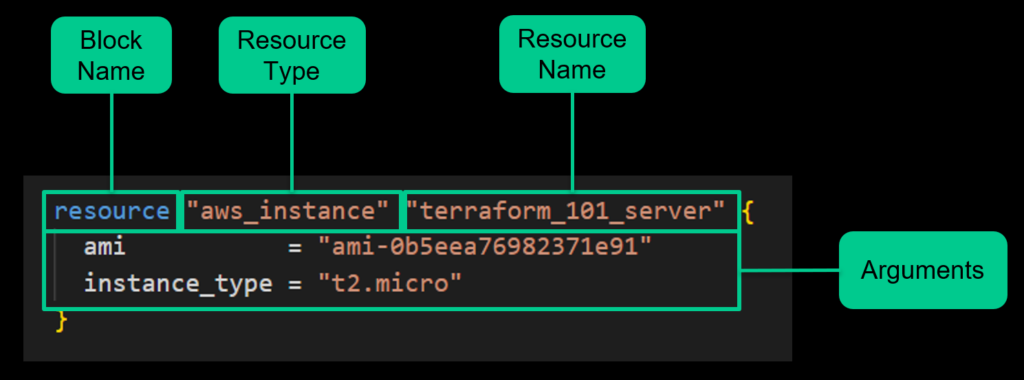 HCL Example with standard elements highlighted
HCL Example with standard elements highlighted
resource "aws_instance" "terraform_101_server"{
ami = "ami-0b5eea76982371e91"
instance_type = "t2.micro"
- Blocks are containers for other content and usually represent the configuration of some kind of object (like a resource). Blocks have a block type, can have zero or more labels, and have a body that contains any number of arguments and nested blocks. There are several types of blocks:
- Terraform block - settings for the execution environment of Terraform itself (required terraform version, backend settings, and so on.)
- Provider block - details of the provider(s) being used. Includes information like access mechanisms, regional options, profile to use, and so on...
- Resource block - specifies a single uniquely named resource managed by terraform. Includes resource type, name, and config options Data block - data sources that can be queried (cloud provider, local list, etc.)
- Module block - reusable set of resources that can be leveraged across multiple terraform configs
- Output block - Resources managed by Terraform each export attributes whose values can be used elsewhere in configuration. Output values are a way to expose some of that information to the user of your module. (For example, the IP address of an EC2 instance).
- Variable block - Defines variables to be used in the Terraform config. Input variables let you customize aspects of Terraform modules without altering the module's own source code. This functionality allows you to share modules across different Terraform configs, making your module composable and reusable. Variable names have to be unique 😉
- order of precedence: defaults < env vars < terraform.tfvars file < terraform.tfvars.json file < .auto.tfvars < command line (-var & -var-file)
- Locals block - A local value assigns a name to an expression, so you can use the name multiple times within a module instead of repeating the expression.
Install and version Terraform providers
Terraform relies on Providers to allow Terraform to interact with remote systems (CSPs, SaaSs, APIs, and so on).
Some providers require additional config info (endpoints, regions used, etc..) to work.
You must declare which providers are needed in your Terraform configs. They go in the root module (child modules get their provider configs from the root module) in a required_providers block (see Requiring Providers for more details)
Use the alias meta-argument to define multiple configs for the same provider (that is, to support multiple regions for a cloud platform)
The required_providers block defines all of the providers needed by the current module
To ensure that multiple users run the same Terraform config (with the same provider versions), you:
- Specify provider version constraints
- Use the dependency lock file:
- named .terraform.lock.hcl
- updates when you run the
terraform initcommand - should be included in version control repo!
- if a provider is in the lock file, TF will always use that version unless you
terraform init -upgrade
- If it does upgrade, review the changes 😉:
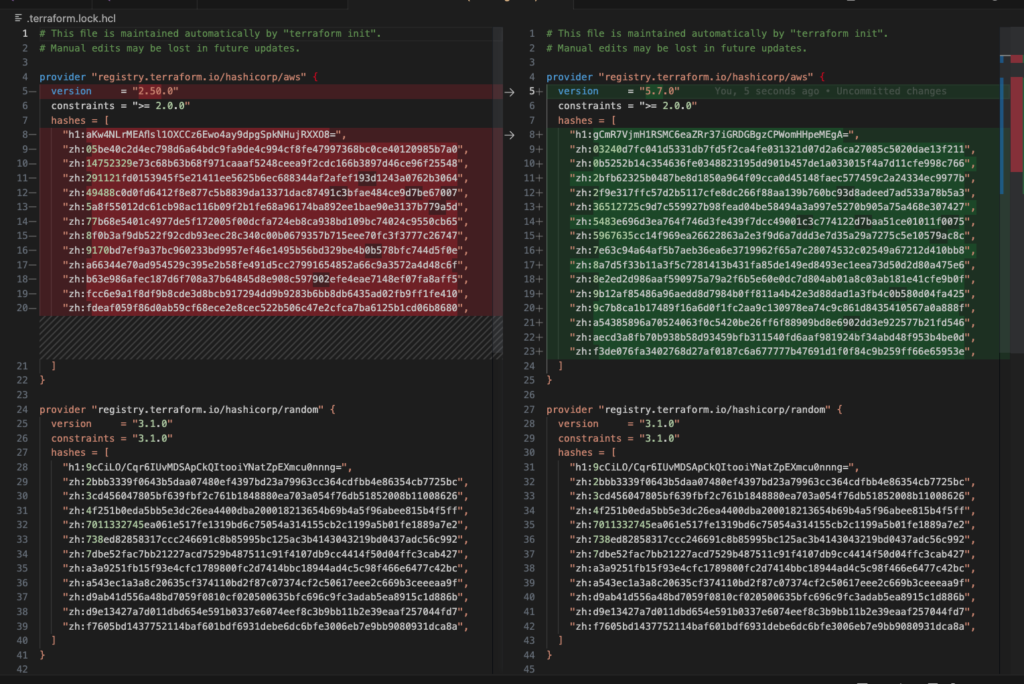 Example of a lockfile change of the AWS provider version
Example of a lockfile change of the AWS provider version
Describe plugin-based architecture
Terraform is split into 2 main parts:
- Terraform Core: a statically compiled binary (written in Go). When you type
terraformin the CLI you are invoking the core functionality:- reading and interpolating config files and modules
- state mgmt
- building a resource graph
- plan execution
- talking to plugins
Terraform Plugins: executable binaries invoked by Terraform Core over RPC.
- Each plugin is geared towards a specific service (like AWS).
- All Providers and Provisioners used in Terraform configs are plugins
- Provider plugin are responsible for:
- Initializing libraries for making API calls
- Authentication with the infra provider
- Defining resource maps to specific services
Write a Terraform configuration using multiple providers
Sometimes you'll need to reference the same provider for multiple reasons. In the below example we're using multiple regions within AWS, therefore we need a mechanism for distinguishing between the two providers. Enter the alias argument. With it you can assign resources to specific environments:
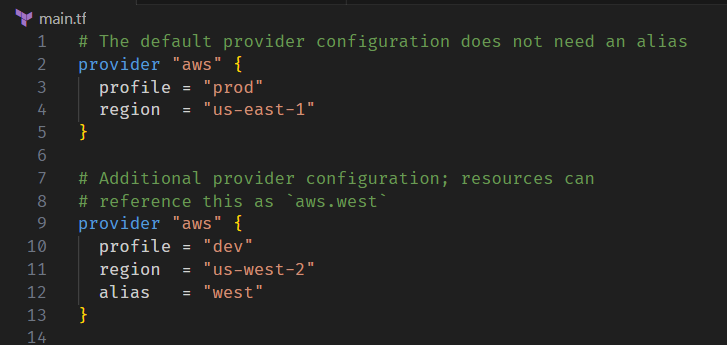 Example of using multiple providers with the alias argument
Example of using multiple providers with the alias argument
provider "aws" {
profile = "prod"
region = "us-east-1"
}
provider "aws" {
profile = "prod"
region = "us-west-2"
alias = "west"
}
Describe how Terraform finds and fetches providers
Required providers are specified in the (surprise!) required_providers block nested inside the top-level terraform block:
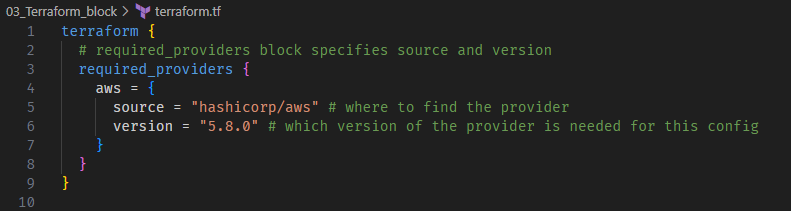 Example usage of the required providers block
Example usage of the required providers block
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.8.0"
}
}
}
The source value specifies the primary location where Terraform can download it (see link for specifics around syntax).
Use the commands terraform version (what version of core and what plugins are installed) and terraform providers (what providers are required by the configuration) to get more information about config requirements:
 Output of the terraform version command
Output of the terraform version command
 Output of the terraform providers command
Output of the terraform providers command
Use Terraform Outside the Core Workflow
Now that we've learned the basics of Terraform, Domain 4 gets into more workflows that you will see very often in the real world.
This domain answers questions like "If you built an environment without using Terraform, how would you move those resources over to a Terraform managed state?" and "What happens when everything breaks?"
Describe when to use terraform import to import existing infra into your Terraform state (note: can only import 1 resource at a time)
- Write a resource block for it in your configuration
- resource name must be unique (like any regular resource block)
- Run terraform import with the syntax
terraform import [options] <address id>- address id is the resource id of the provider
- each remote object must be bound to only one resource block in the terraform config
- Run terraform plan & review how the config compares to the imported resource
- Make adjustments to the config to reach desired state
Use terraform state to view Terraform state
- Use this instead of modifying the statefile directly
- Never modify the statefile directly ever ever ever EVER
- Used for advanced state mgmt
- Works with both local and remote statefiles
- Creates a backup that cannot be disabled
terraform state -helpto get startedterraform state listto get a less-cluttered view of resources under mgmtterraform state list [resource]to get granular resource data (very handy):
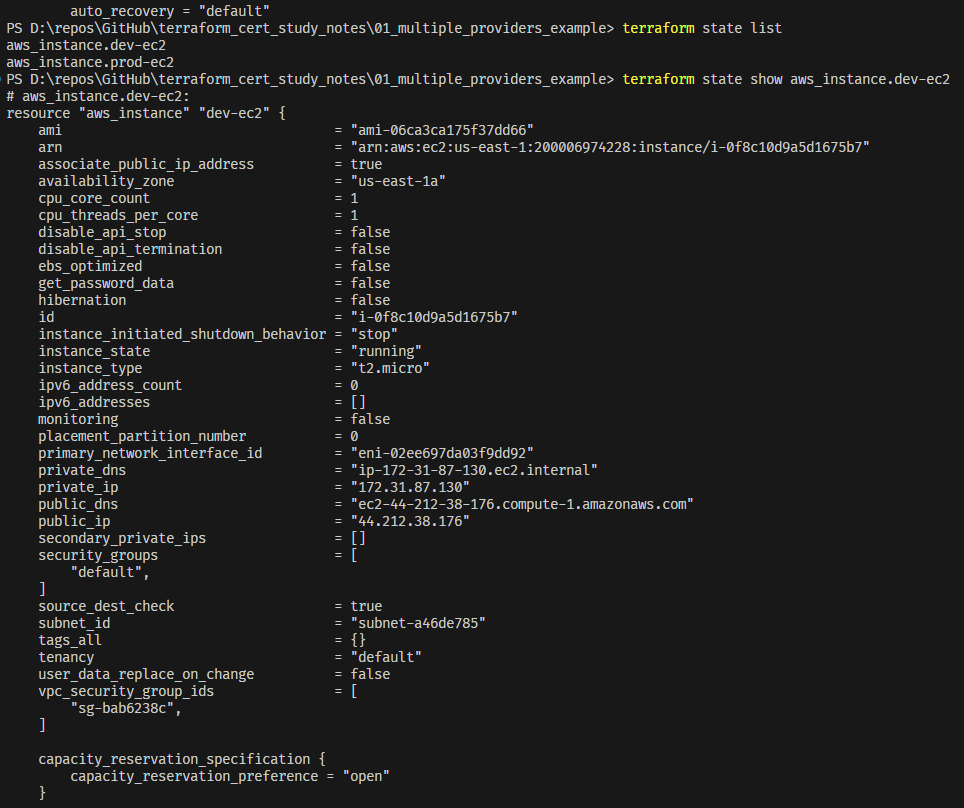 Output of the terraform state command
Output of the terraform state command
Describe when to enable verbose logging and what the outcome/value is
You can generate logs for Terraform Core and Providers separately.
- log levels =
TRACE>DEBUG>INFO>WARN>ERROR - To enable core logging, set env var
TF_LOG_CORE=(log level)- linux example
export TF_LOG_CORE=TRACE - powershell example
$env:TF_LOG_CORE=TRACE
- linux example
- To enable provider logging, set env var
TF_LOG_PROVIDER=(log level)- linux example
export TF_LOG_PROVIDER=TRACE - powershell example
$env:TF_LOG_PROVIDER=TRACE
- linux example
- To persist logs, set env var:
- linux
export TF_LOG_PATH=logs.txt - powershell
$env:TF_LOG_PATH=logs.txt
- linux
- To undo env var, reset values to null:
export TF_LOG_CORE=""export TF_LOG_PROVIDER=""export TF_LOG_PATH=""
 Output of the terraform refresh command
Output of the terraform refresh command
Interact with Terraform Modules
Domain 5 expands your knowledge of Terraform by introducing the concept of modules. A lot of people are using Terraform and they are creating modules to help make it easier for everyone to provision resources. Don't recreate the wheel, use modules!
Contrast & use different module source options including the public Terraform Registry
 Browse module section of the Terraform registry
Browse module section of the Terraform registry
A Terraform module is just a set of Terraform configuration files inside a folder – nothing to be afraid of. 😊
Every Terraform config has at least one module, the root module. If you have child modules, the root module can make calls to them.
Child modules are just files outside of the working directory. They can be a folder on your system, up in a GitHub repo, S3 bucket, and so on. Check out all the options here
The source arg in the module block tells Terraform where to find the source code for the module. The xyntax for registry modules required source argument is <namespace>/<name>/<provider>
- example:
terraform-aws-modules/vpc/aws
Use the Terraform Registry to find and use 'public' modules
terraform initwill download and cache modules ref'ed in a config- By default, only verified modules are shown in the Terraform registry. You can change that with filters.
- Modules in the registry are versioned using the
versionargument - Private Registry Module Sources syntax =
<hostname>/<namespace>/<name>/<provider>
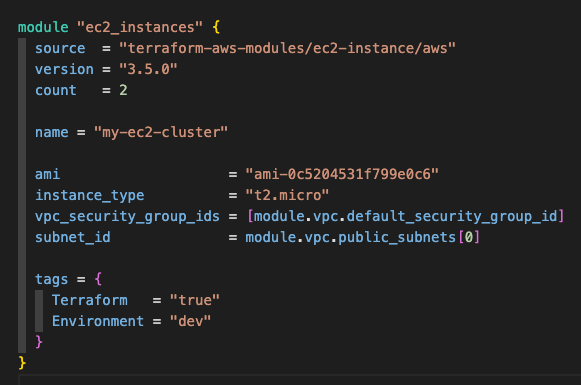 Example of using a Terraform module
Example of using a Terraform module
module "ec2_instance" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "3.5.0"
count = 2
name = "my-ec2-cluster"
instance_type = "t2.micro"
vpc_security_group_ids = ["sg-12345678"]
subnet_id = module.vpc.public_subnets[0]
tags = {
Terraform = "true"
Environment = "dev"
}
}
Interact with module inputs and outputs
Input variables let you customize aspects of Terraform modules without altering the module's own source code
- Each input variable accepted by a module must be declared using a
variableblock. As always, variable names must be unique w/in the module - If a variable doesn't have a default value assigned to it, it's required
Output blocks provide back information from the resources generated by the module.
- to use output information in the 'calling module' (normally the root module), use interpolation syntax of the output block in the 'sending module'
 child module output being called by calling module
child module output being called by calling module
Describe variable scope w/in modules/child modules
Deciding what is in and out of scope for a module can be challenging. Don't overuse a module by putting too many resources into one.
A good rule is to limit it to one resource type offered by a provider.
You can group infrastructure that is always deployed together. You can also group resources with the same set of privledges where possible to minimize blast radius.
Try to seperate long-running resources from short-lived resources: don't put your production database in the same module as your dev lambdas. 😂
Variables are declared in the child module. If you want information from the child module, you must create an output block for that info in the child module & then call it using interpolation syntax. You cannot access child module resource information otherwise.
If you are building a module, it is good practice to create output blocks for all resource info availalbe, even if you don't see an immediate use for it:
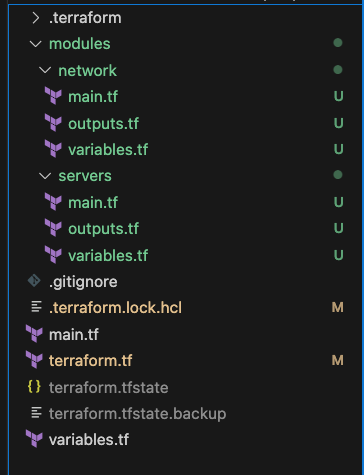 Example layout of root and child modules
Example layout of root and child modules
Set module version
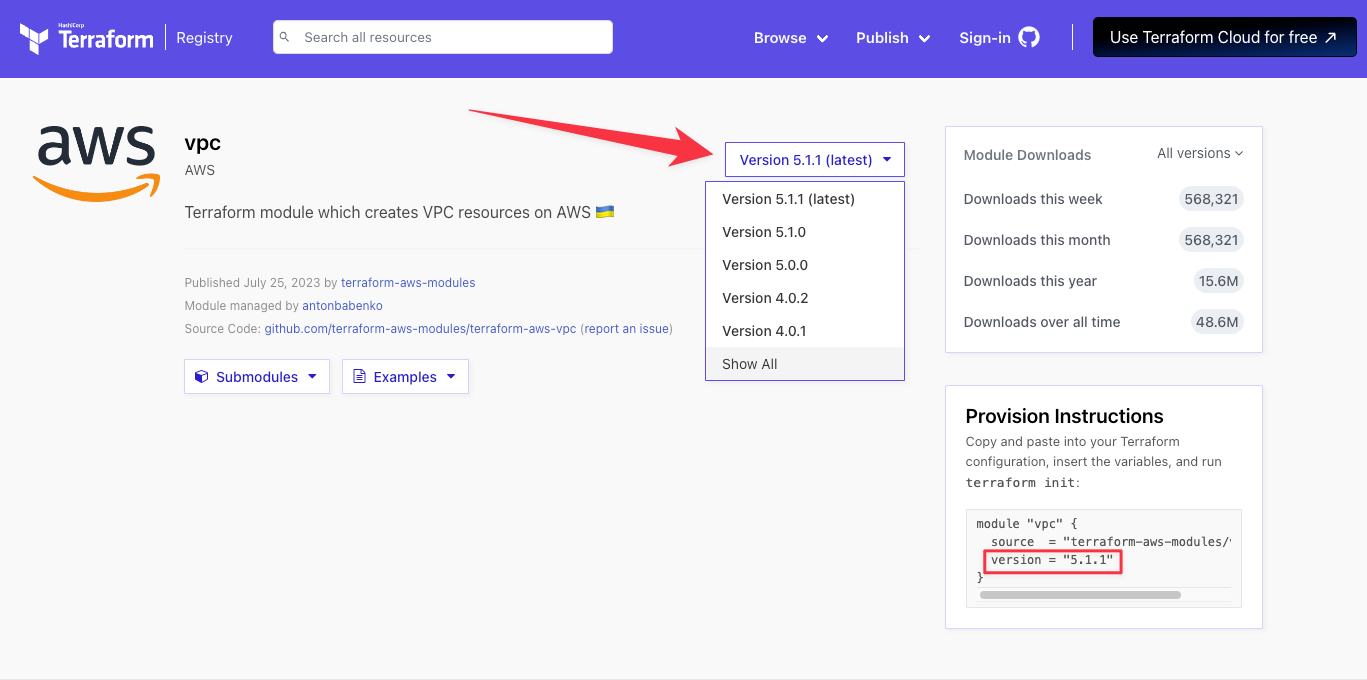 Where to check module versions
Where to check module versions
Much like other blocks, modules can be versioned. If you change the module version, you will need to run terraform init again.
- It is recommended to version constrain your module usage to prevent unexpected changes from occurring
- Versioning is supported for the public Terraform Registry & TFCs private module registry
- Local file modules do not support versioning
Use the Core Terraform Workflow
Domain 6 gets much more granular into the core Terraform workflow. In the real world, this is the process that you will do again and again and again (and again!), so it's important that you understand all of the little details.
Especially pay attention to how the processes interact with each other and exactly WHAT is happening when you use a particular command.
Describe Terraform workflow (write -> plan -> create)
Write:
- Author your IaC in your editor of choice (like VS Code😉)
- Written in Hashicorp Configuration Language (HCL)
- Store your work in VCS (like Git + GitHub)
Plan:
- Initialize the working directory with
terraform init - Preview changes before you apply with
terraform plan - Do this repeatedly as you are building your config to fix errors and have a tight feedback loop
- Can output and save for later with
terraform plan -out [plan name]
Create:
terraform applyto deploy the infra that you've written- Can apply a previous saved plan with
terraform apply [plan name] - Recommended: push your config to remote repo for redundancy/safekeeping
Initialize a Terraform directory (terraform init)
initializes (get it?) a working directory that contains .tf files- This is the first command that should be run after writing/cloning a new config. You can find Command Options here
- Root config directory is checked for backend config data
- to update backend, use
-reconfigureor-migrate-state
- to update backend, use
- Sources and downloads the providers and modules used in the config
- Creates a lock file .terraform.lock.hcl to pin provider verions
- Reasons to re-initialize a config:
- adding a new provider
- upgrading/downgrading the version of a provider with
terraform init -upgrade - adding a new module
- upgrading/downgrading the version of a module with
terraform init -upgrade - changing the location of the backend (statefile)
Validate a Terraform config (terraform validate)
Know the limitations! It DOES:
- Validate local configuration files
- Check syntactic validity
- Check internal consistency
- Check correctness of attribute names, value types, and expected argument types
It DOES NOT:
- Access remote services (remote state, provider APIs, upstream dependencies, etc...)
- Check with backend provider to insure external consistency
Generate & review an execution plan ([terraform plan](https://developer.hashicorp.com/terraform/cli/commands/plan))
This creates an execution plan to preview changes Terraform wants to make to your env.
Here are the steps:
- Reads the current state (if any) of remote objects under mgmt to make sure state is up to date
- Compares current config to prior state & notes changes
- Proposes changes that will make the remote env match the config
You can use terraform plan -help to see all the options, and terraform plan -out [plan name] to create a file to be reviewed/used later.
- Use
terraform plan -refresh-onlyto detect drift between your config and the actual environment - Doesn't change the env, you can run multiple times
- + resource will be created
- - resource will be destroyed
- ~ resource will update in place
- -/+ resource will be destroyed & recreated
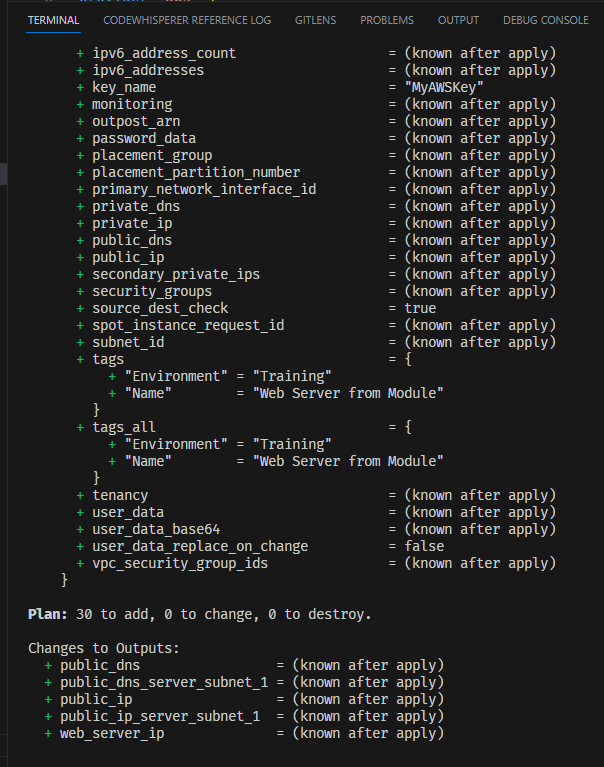 creating 30 new resources
creating 30 new resources
Execute changes to infra (terraform apply)
- Provisions, changes, and destroys (recreates) resources in an environment
- Executes the proposed actions of a
terraform plan - Will only affect the resources under mgmt
- Running it without a plan causes it to automatically run a plan, then execute it
- You can pass in a previously generated plan with
terraform apply -out=[plan name] terraform apply -auto-approvebypasses the post-plan manual 'yes' checkterrafrom apply [plan name]to execute a previously saved plan
Destroy Terraform managed infra (terraform destroy)
- You'll never guess what this command does 😂
- Destroys all infrastructure under management by Terraform (nothing else)
- Automated cleanup is better because you always forget to delete something when you build it manually
- Be careful with
terraform destroy -auto-approve terraform apply -destroyalso does the same thing
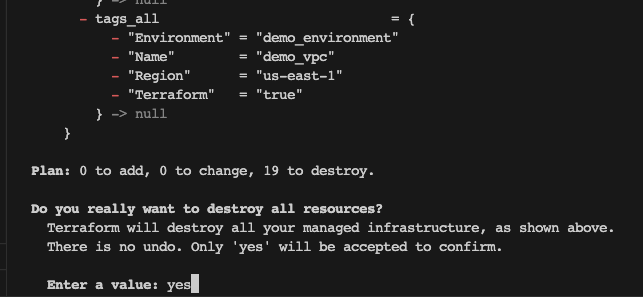 Are you really REALLY sure?!?!
Are you really REALLY sure?!?!
Apply formatting & style adjustments to a config (terraform fmt)
- Formats and styles your code for better readability
- Does NOT fix your errors
- Lists which files it updates
- Very useful 😁
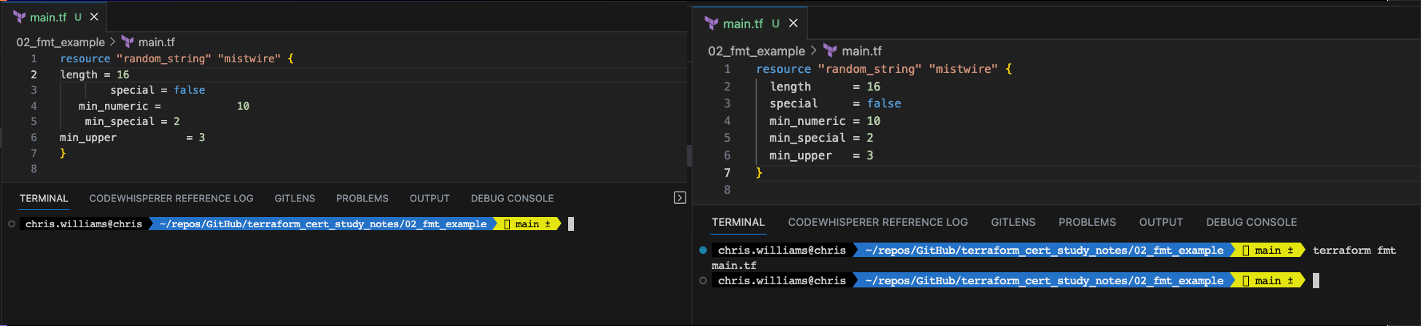 How terraform fmt works
How terraform fmt works
Implement and Maintain State
State is THE MOST IMPORTANT THING in any given Terraform managed environment. Without your statefile, you're going to have a bad day.
Domain 7 walks through the different types of state, how to move it around, and how to protect it.
Describe default local backend
Terraform stores and references the state of all terraform managed environments.
The configuration file is what we want the environment to look like, the statefile one to one mapping of the resources provisioned to the config file.
- The
localbackend:- stores state on the local filesystem
- locks that state using system APIs
- performs operations locally
Default statefile is named terraform.tfstate and lives in the working directory. If you don't specify a backend, terraform uses the default local backend.
You CAN explicitly specify local backend if you want to have greater control over statefile location, future state migration considerations, and so on.
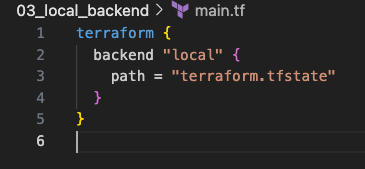 Explicitly defined default local state
Explicitly defined default local state
terraform {
backend "local" {
path = "terraform.tfstate"
}
}
Describe state locking
State data (the statefile) is the source of truth for Terraform and therefore is very important. As such it needs to be protected from several file corruption and data loss scenarios.
Backends are responsible for storing state and providing an API for state locking. State locking is optional but highly recommended in multi-user environments.
- You can manually retrieve remote state with
terraform state pull - You can manually write state with
terraform state push.... but don't ever ever ever do this without proper supervision and guidance and backups.
State locking prevents multiple users from making changes to a managed environment simultaneously (potentially corrupting state). Locking happens automatically on all potential state writing operations.
- You can ignore state locking with
-forcebut don't 😅 - You can also
terraform force-unlock [LOCK_ID]if unlocking fails, but this is a break glass emergency use case
Not all backends support locking! Local, TFC, AWS S3 (with some tweaks), and several others do (see docs for which ones do/don't).
Handle backend and cloud integration auth methods
When you have state backend stored somewhere other than local, you'll need to have some form of authentication - this is very sensitive information that needs to be protected!
Each backend has it's own auth mechanism (for example, access keys for AWS).
Some other things to keep in mind:
- Arguments used in the block body are specific to the chosen back end type
- If you want to change backend location you'll need to start with
terraform init -reconfigure terraform login [hostname]is used to obtain and save an API token from TFC, TFE, or other host that offers Terraform services- If you don't explicitly provide a hostname, cmd defaults to TFC at
app.terraform.io - By default Terraform pulls & saves API token in plain text to
credentials.tfrc.json- this can be modified for other secrets mgmt systems - To configure a backend block, add a nested
backendinto the top-levelterraformblock:
 Defined remote state
Defined remote state
terraform {
backend "remote" {
organization = "example_corp"
workspaces {
name = "my-app-prod"
}
}
}
Differentiate remote state backend options
Terraform has a built-in selection of backends and the configured backend must be available in the version of Terraform you are using. This is why it's important to version everything in your configs!
You don't need to configure a backend when using TFC because it auto-manages state in the workspaces assoc. to the config. If your config includes a cloud block it cannot have a backend block.
Manage resource drift and Terraform state
terraform plan -refresh-only
- Creates a plan that updates state to match changes made outside of terraform
- Good for drift detection
- Does not propose any actions to undo changes
terraform apply -refresh-only
- Updates the statefile to accept the changes made manually in the environment
- Does NOT change the config file! If you don't update the config with the new changes, then the next
terraform applyof that config will revert environment back to the original state
Describe backend block and cloud integration configuration
- Defines where terraform stores the statefile for a working directory
- The statefile is the source of truth for resources under terraform management and therefore is extremely important (I might have said this before 😉)
- By default terraform uses
localwhich stores statefile on local disk remoteis the other backend type which covers everything else (TFC, S3, and so on...)- Limitations:
- 1 config, 1
backendblock - Cannot use interpolation (so we can't use variables)
- 1 config, 1
- Partial configurations
- Omit certain arguments to be supplied at runtime
- Useful for automation scripting & CI scenarios
- When using Terraform Cloud, you don't need to configure a backend because TFC manages state in the workspace associated with the config
cloudblock is nested interraformblock- Limitations:
- 1 config, 1
cloudblock - If the config includes a
cloudblock it cannot also have abackendblock - Cannot use interpolation
- See cloud settings for more information
- 1 config, 1
Understand secret management in state files
- The statefile can contain a lot of secrets!!!
- resource IDs
- DB username/passwords
- private keys
- Andrew Brown's home phone number
So you should treat it like you would your company passwords. By default local state is stored in plaintext as JSON. You can mark sensitive information in your config files as such with the sensitive = true argument.
- redacted from the CLI output, but still is in the statefile as plaintext (that's why it's important to lock down the statefile)
Use a backend that encrypts and protects your statefile from unauthorized access.
- TFC encrypts state at rest & in transit
- Turn on encryption if you are using S3 (& use state locking!)
- Terraform does not persist state to local disk when remote state is being used
Read, Generate, and Modify Configuration
Domain 8 teaches you more about the config files and how to leverage HCL fully. Like any programming language, HCL can be refactored for ease of understanding and keeping your code DRY (Don't Repeat Yourself).
Demonstrate use of variables and outputs
- Programming analogies:
- Input variables = function arguments
- Output values = function return values
- Local values = function local variables
- Each input variable accepted by a module must be declared using a
variableblock: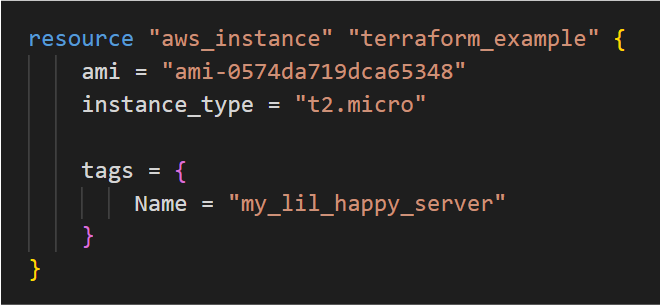
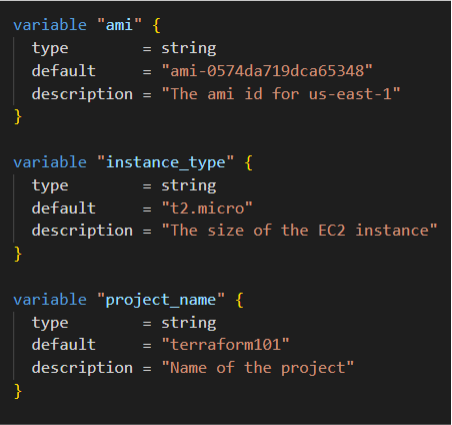
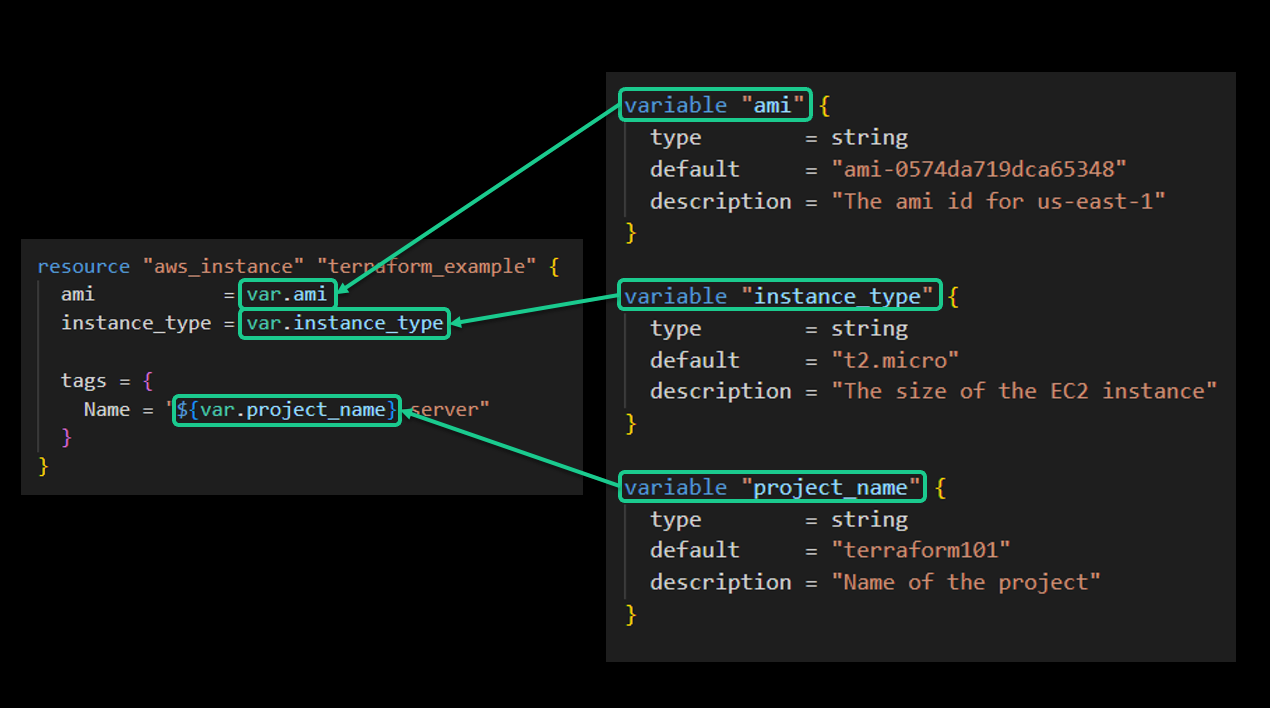
- Variable names can be any valid name except
source,version,providers,count,for_each,lifecycle,depends_on, orlocals - Input order of precedence: defaults < env vars < terraform.tfvars file < terraform.tfvars.json file < .auto.tfvars < command line (-var & -var-file)
- side note: terraform.tfvars is the most popular way for manipulating variables used out in the wild
- Variable names can be any valid name except
- By the same token, each output value must be declared using an
outputblock- In the root module, the output is displayed to the user
- In a child module, the output can be used to access a value by the root module (
module.<MODULE NAME>.<OUTPUT NAME>) - Outputs only render on
terraform apply, notterraform plan terraform outputwill display your outputs without running anapplyterraform output <NAME>to pull a specific value- marking an output value as sensitive suppresses the value in the CLI during a
terraform apply, but NOT in the statefile or aterraform output <NAME> - if you mark an variable as
sensitivebut NOT an output for that variable, it will error out
Describe secure secret injection best practices
- Mark sensitive values as
sensitive - Never put actual secret values into a .tf file as they would be checked into source control
- Passwords, API tokens, access tokens, etc... must be obfuscated
- Never check your statefile to source control (same reason as above)
- Use environment variables by setting
TF_VAR_<NAME>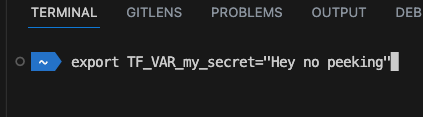
- If you are using Terraform Cloud use the environment variables for the appropriate workspace:
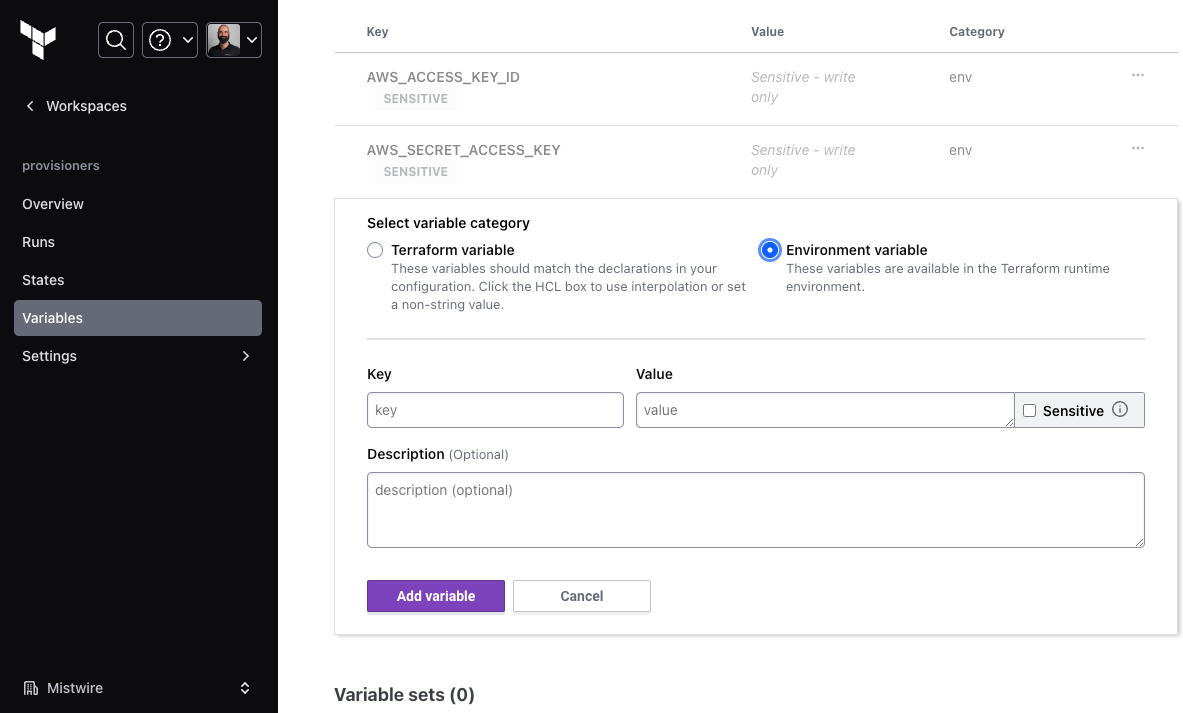
- Use a secrets management solution like Vault
- Run through this tutorial to get a feel for injecting secrets into Terrafrom using Vault
Understand the use of collection and structural types
- Colletion types are a collection of one type of grouping
- All elements of a collection must be of the same type
list(string)is different fromlist(number) - 3 kinds of collection types:
list(...)sequence of ordered elements (starting at 0)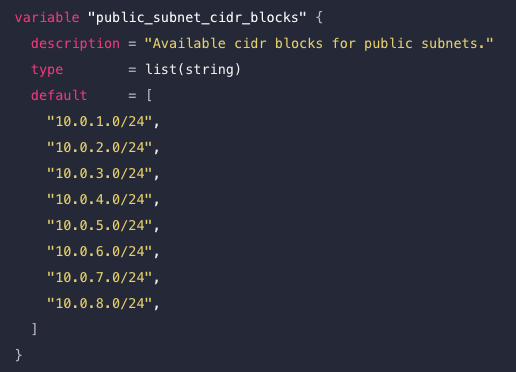
map(...)sequence of key/value pairs separated by a comma. Can confusingly use both = or : as the k/v separator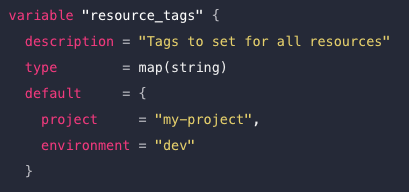
set(...)a collection of unique, unordered, unrepeating vaules
- All elements of a collection must be of the same type
- Structural types allow multiple types of elements to be grouped together
- 2 kinds of structural types:
object({<KEY> = <TYPE>, ...})named attributes where each one has it's own typetuple([<TYPE>, <TYPE>, ...])sequence of ordered elements (starting at 0)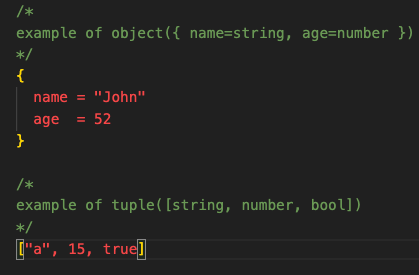
- 2 kinds of structural types:
Create and differentiate resource and data configuration
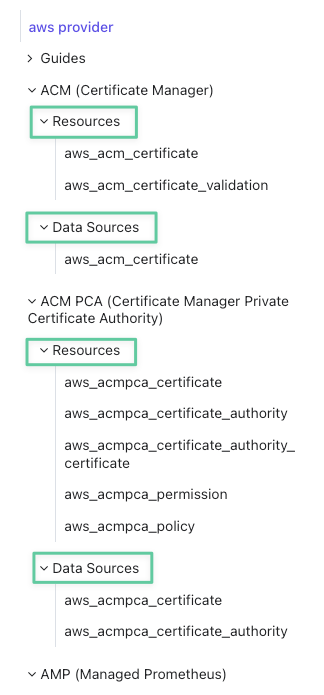
- Providers can access both Resources and Data Sources (examples from the AWS provider:
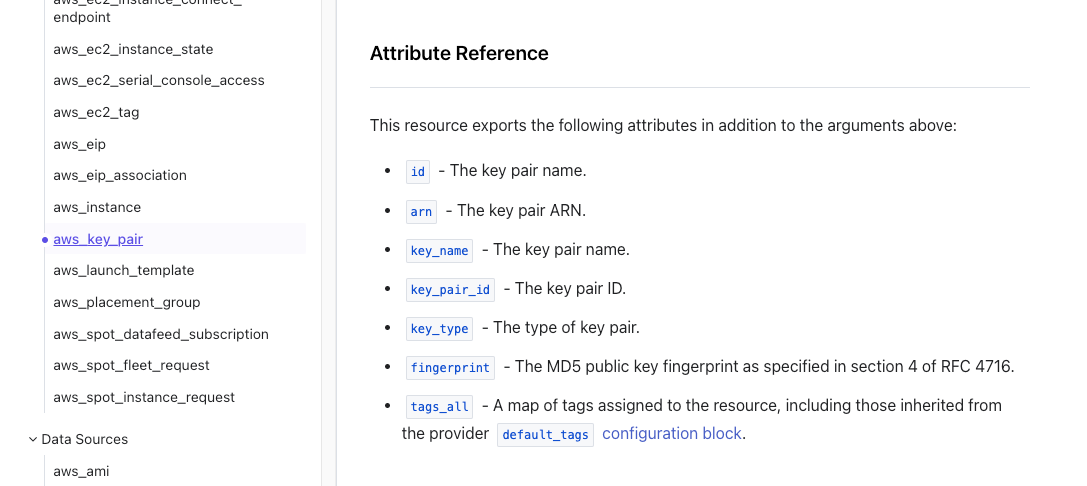
- You can query resources you've created in Terraform (via exporting Attribute References):
- And also do data lookups for existing resources that haven't been made with Terraform
- Do the Query data sources tutorial
Use resource addressing and resource parameters to connect resources together
- Resource path syntax
[module path][resource info]
- Module path syntax
module.<MODULE NAME>[optional module index]
- Resource spec syntax
resource_type.user_defined_name[optional index]
- Types of named values:
- Resources
<RESOURCE TYPE>.<NAME>- if
countis used, ref is a list accessed with [N] - if
for_eachis used, ref is a map accessed with ["key"]
- if
- Input Variables
var.<NAME> - Locals
local.<NAME> - Child module outputs
module.<MODULE NAME>- same
countandfor_eachrules as resources
- same
- Data blocks
data.<DATA TYPE>.<NAME>- same
countandfor_eachrules as resources
- same
- Filesystem/workspace info
path.modulelocation of expression (don't use in write operations)path.rootroot module locationterraform.workspacecurrently selected workspace
- Block 'local' values
count.indexeach.key/each.valueself
- Resources
Use HCL and Terraform functions to write configuration
- Terraform has a number of built-in functions for manipulating values, strings etc...
- Review them here
- Not necessary for the exam (I don't think?) but they will make your life easier when actually using HCL
- Do the dynamic operations with functions and create dynamic expressions tutorials
Describe built-in dependency management (order of execution based)
- Terraform generates a dependency graph for determining which resources need to be built 1st, 2nd, 3rd, etc...
depends_oncan be used to alter dependencies- The
lifecycleblock along withcreate_before_destroyandprevent_destroyare additional tools in the lifecycle toolbelt
- Items with no dependencies are built in parallel to speed up the provisioning process
- By default, up to 10 concurrent operations can be run at the same time
- This can be changed with the
-parallelismflag onplan,apply, &destroycommands
- You can see this dependency map using the
terraform graphcommand and a viewer like Graphviz (or http://www.webgraphviz.com/ if you are lazy like me)
Understand Terraform Cloud Capabilities
Domain 9 (the last domain!) is all about Terraform Cloud. This is the HashiCorp managed remote backend and offers a free tier (up to 500 managed resources when I wrote this article).
Every production-level environment will use a state-locking remote back end, so knowing how Terraform Cloud works is great not only for the exam, but for real world job experience as well.
Explain how Terraform Cloud helps to manage infra
Terraform Cloud - is a SaaS offering that:
- Manages Terraform runs in a consistent & reliable environment
- Includes easy access to shared state and secret data
- Access controls for approving changes to infrastructure
- A private registry for sharing Terraform modules
- Detailed policy controls for governing the contents of Terraform configurations
- Remote state storage
- Version control integrations
- Custom workspace permissions
- Flexible workflows - CLI, UI, VCS, or the API
- Collaboration - review/comment on plans prior to executing infra changes
- Audit logs - who broke it
Terraform Enterprise is a self-hosted distribution of Terraform Cloud. It's not on the exam, but here are the docs for requirements, ref architectures, and install guides.
Describe how Terraform Cloud enables collaboration and governance
Terraform Cloud uses Teams as its grouping paradigm. Teams are comprised of Users in a given Organization. Each Team can have an API token that is not associated with a specific user.
The Organization grants workspace permissions to Users and Teams. The Owners Team:
- Is the 1st team created
- Cannot be deleted the Owners Team or left empty
- Can create/delete other Teams
- Manages Org-level permissions to other Teams
- Can view the full list of teams (Visible and Secret)
Terraform Cloud enforces Policies on runs using the Sentinel Policy Language. After defining a policy, they are added to policy sets that Terraform Cloud can then enforce.
- Do the Enforce a policy with Sentinel tutorial.
Conclusion
That's it! 😂 I feel confident that if you review all of the material here, do the tutorials specified in the exam prep, and attend our Terraform Beginner Bootcamp, you will be well prepared to sit and pass the Terraform Associate Exam.
Good luck!