
By Nandhini Saravanan
A beginner’s guide to the NoSQL world
Organizing data is a very difficult task. When we say organise, we are actually categorising stuff depending on its type and function.
 _[Source](https://bitnine.net/wp-content/uploads/2016/12/SQL-vs.-NoSQL-Comparative-Advantages-and-Disadvantages.jpg" rel="noopener" target="blank" title=")
_[Source](https://bitnine.net/wp-content/uploads/2016/12/SQL-vs.-NoSQL-Comparative-Advantages-and-Disadvantages.jpg" rel="noopener" target="blank" title=")
One option is RDBMS is like an Excel Sheet — you categorise data in the form of tables. You can form relationships between the tables.
A query questions the database, which gives you a relevant answer in return. This querying language is SQL or Structured Query Language.
For example,
select * from Employee_Data;
selects all the Employee Data from the Employee_Data table.
Relational databases follow a schema, a detailed blueprint of how your tables work.
You use Amazon, Facebook and so many networking applications. They release updates, add new functionalities and even extra modules. So how does one change the schema each time? Isn’t it time consuming for such huge companies to devote their time and labour to changing the schema?
This is where SQL could not work.
The Cons of RDBMS
Relational databases aren’t as bad as people portray these days. They are still in use by plenty of organisations. The introduction of NoSQL into the picture is to fill up the spaces where RDBMS can’t be of use anymore.
I am going to show you examples so that you have a clear understanding.
1. RDBMS can not handle ‘Data Variety’.
The amount of unstructured data continues to increase yearly and managing it is hard. RDBMS can’t force all types of data under a unified schema of tables.
Data Silos are also a problem for developers.
According to Tech Target, a data silo is a repository of data that remains under the control of one department. It is isolated from the rest of the organisation.
This means that when more silos exist for the same data, their contents are likely to differ. It creates confusion on which repository represents the most up-to-date version.
The increase of data from the year 2013 to 2020 is visible in the image below.
About 44 Zeta bytes of data will be generated in the year 2020.
Handling such diverse data which aren’t related to each other could be much harder in RDBMS.
 _[Source](https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm" rel="noopener" target="blank" title=")
_[Source](https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm" rel="noopener" target="blank" title=")
Example: It is difficult to store the details of a patient, who has varying body conditions. Categorisation of such diverse data is difficult in RDBMS.
2. Difficult to change tables and relationships.
Alteration of the relationships between tables or addition of a new table could affect the existing relations. This means changing the schema.
Change of the schema would be like eliminating the existing one and devising a new schema.
Addition of a new functionality would need all the elements to support the new structure. Change is inevitable.
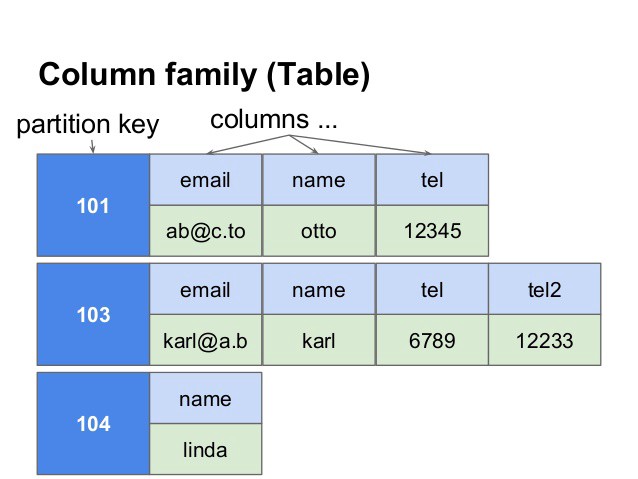
Example: Each extra column needs all the prior rows to have values for that column. Whereas in Cassandra (a NoSQL database), you can add a column to specific row partitions.
3. RDBMS follow the ACID properties of the database.
The ACID properties of a database are Atomicity, Consistency, Isolation and Durability.
Atomicity — An “all or nothing” approach. If any statement in the transaction fails, the entire transaction is rolled back.
Consistency — The transaction must meet all protocols defined by the system. No half completed transactions.
Isolation — No transaction has access to any other transaction that is in an intermediate or unfinished state. Each transaction is independent.
Durability — Ensures that once a transaction commits to the database, it is preserved through the use of backups and transaction logs.
The ACID properties aren’t flexible.
For example, RDBMS follows Normalization or a single point of truth concept. For every change you make, you should ensure strict ACID properties. The entity integrity and referential integrity rules also apply.
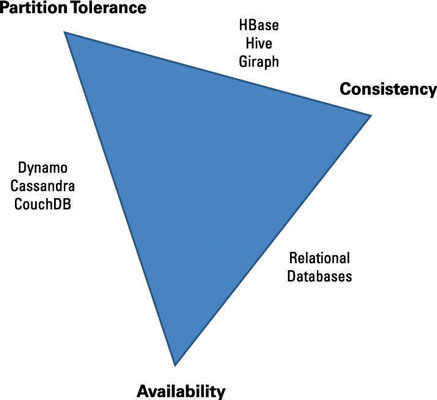
The CAP Theorem
According to Wikipedia, the CAP theorem (Brewer’s theorem) states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
Consistency: Like the C in ACID.
Availability: Resources should be always available. There should be a non error response.
Partition tolerance: No single point (or node) of failure.
It is difficult to achieve all the three conditions. One must compromise between the three.
 _[Source](https://www.dummies.com/wp-content/uploads/423504.image0.jpg" rel="noopener" target="blank" title=")
_[Source](https://www.dummies.com/wp-content/uploads/423504.image0.jpg" rel="noopener" target="blank" title=")
BASE to the rescue!
NoSQL relies upon a softer model known as the BASE model. BASE (Basically Available, Soft state, Eventual consistency).
Basically Available: Guarantees the availability of the data . There will be a response to any request (can be failure too).
Soft state: The state of the system could change over time.
Eventual consistency: The system will eventually become consistent once it stops receiving input.
NoSQL databases give up the A, C and/or D requirements, and in return they improve scalability.
NoSQL
This is when NoSQL came to the rescue. It is “Not Only SQL” or “Non-relational” databases.
Characteristics of NoSQL:
- Schema free
- Eventually consistent (as in the BASE property)
- Replication of data stores to avoid Single Point of Failure.
- Can handle Data variety and huge amounts of data.
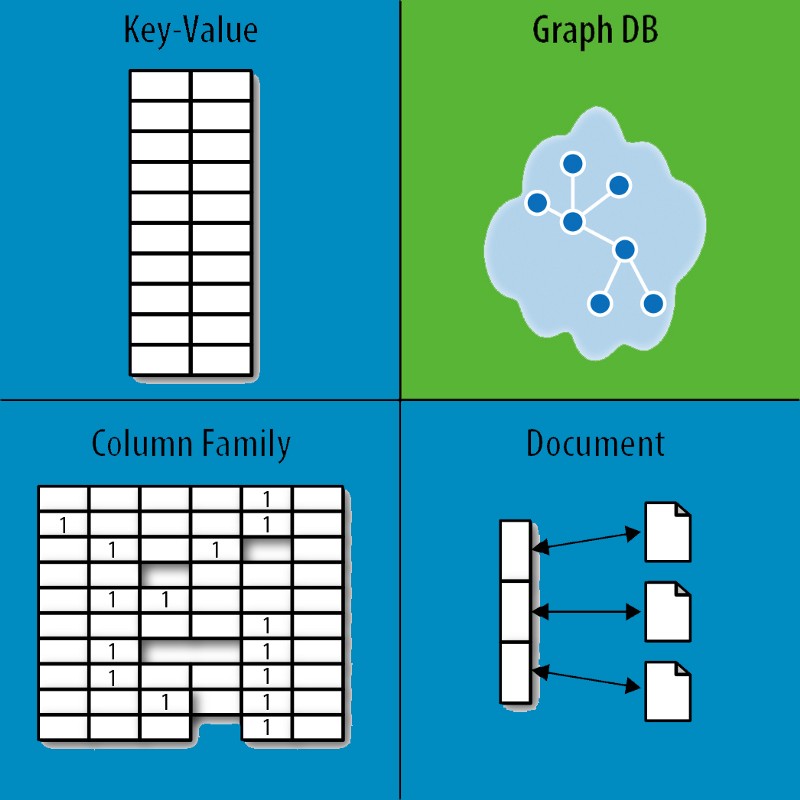
Types of NoSQL databases
NoSQL databases fall into four main categories:
Key value Stores — Riak, Voldemort, and Redis
Wide Column Stores — Cassandra and HBase.
Document databases — MongoDB
Graph databases — Neo4J and HyperGraphDB.
The words to the right hand side are examples of the types of NoSQL database types.
 _[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/nosql-quadrant.jpg" rel="noopener" target="blank" title=")
_[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/nosql-quadrant.jpg" rel="noopener" target="blank" title=")
1. Key Value Stores
A key value store uses a hash table in which there exists a unique key and a pointer to a particular item of data.
Imagine key value stores to be like a phone directory where the names of the individual and their numbers are mapped together.
Key value stores have no default query language. You retrieve data using get, put, and delete commands. This is the reason it has high performance.
Applications: Useful for storage of Comments and Session information. Pinterest uses Redis to store lists of users, followers, unfollowers, boards.
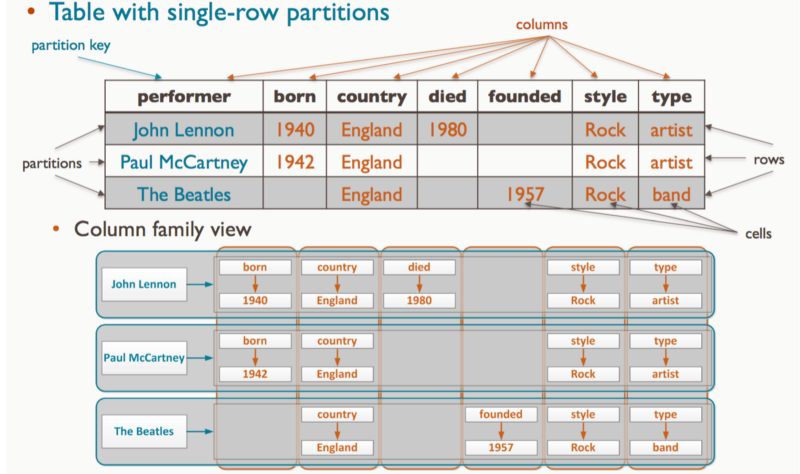
2. Wide column stores
In a column store database, the columns in each row are contained within that row.
Each column family is a container of rows in an RDBMS table. The key identifies the row consisting of multiple columns.
Rows do not need to have the same number of columns. Columns can be added to any row at any time without having to add it to other rows. It is a partitioned row store.
 _[Source](https://studio3t.com/wp-content/uploads/2017/12/cassandra-column-family-example.png" rel="noopener" target="blank" title=")
_[Source](https://studio3t.com/wp-content/uploads/2017/12/cassandra-column-family-example.png" rel="noopener" target="blank" title=")
How does a columnar database store data?
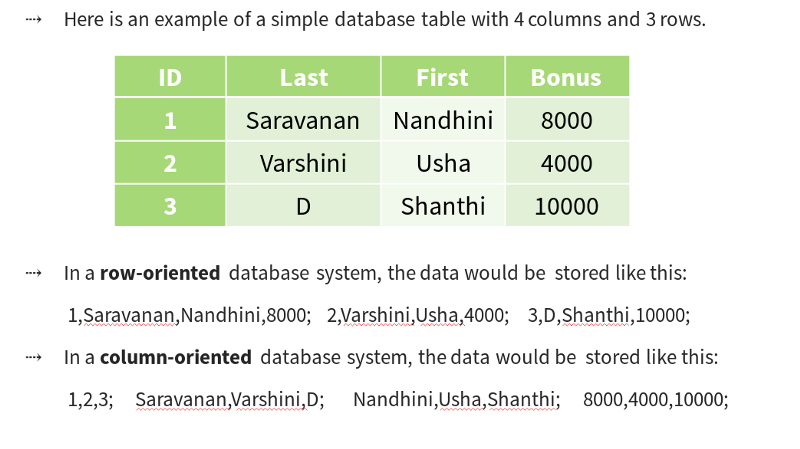 How columnar stores store data
How columnar stores store data
Applications: Spotify uses Cassandra to store user profile attributes and metadata.
3. Document Databases
Document stores uses JSON, XML, or BSON (binary encoding of JSON) documents to store data.
It is like a key-value database, but a document store consists of semi-structured data.
A single document is to store records and its data.
It does not support relations or joins.
 _An example of a JSON document — [Source](https://webassets.mongodb.com/_com_assets/cms/JSON_Example_Python_MongoDB-mzqqz0keng.png" rel="noopener" target="blank" title=")
_An example of a JSON document — [Source](https://webassets.mongodb.com/_com_assets/cms/JSON_Example_Python_MongoDB-mzqqz0keng.png" rel="noopener" target="blank" title=")
If we want to store the customer details and their orders, we can use document stores to do it.
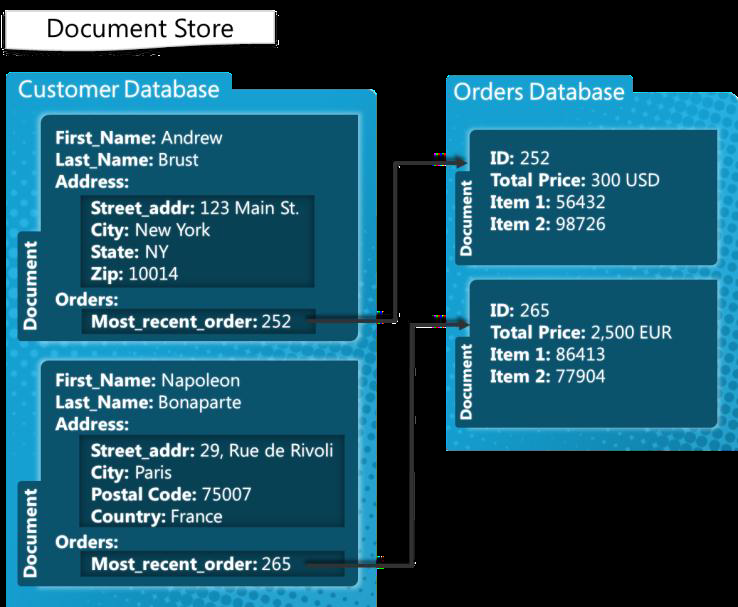 _The Customer database is stored as a set of documents(can be JSON) which is mapped to the Orders database. Source : [MSDN Microsoft Blog](https://blogs.msdn.microsoft.com/usisvde/2012/04/05/getting-acquainted-with-nosql-on-windows-azure/" rel="noopener" target="blank" title=")
_The Customer database is stored as a set of documents(can be JSON) which is mapped to the Orders database. Source : [MSDN Microsoft Blog](https://blogs.msdn.microsoft.com/usisvde/2012/04/05/getting-acquainted-with-nosql-on-windows-azure/" rel="noopener" target="blank" title=")
Applications: SEGA uses MongoDB for handling 11 million in-game accounts built on MongoDB.
4. Graph databases
Nodes and relationships are the essential constituents of graph databases. A node represents an entity. A relationship represents how two nodes are associated.
In RDBMS, adding another relation results in a lot of schema changes.
Graph database requires only storing data once (nodes). The different types of relationships (edges) are specified to the stored data.
The relationships between the nodes are predetermined, that is, it is not determined at query time.
Traversing persisted relationships are faster.
It is difficult to change a relation between two nodes. It would result in regressive changes in the database.
Example: This image is how MySQL works where it has to perform many operations to find a correct result for Alice.
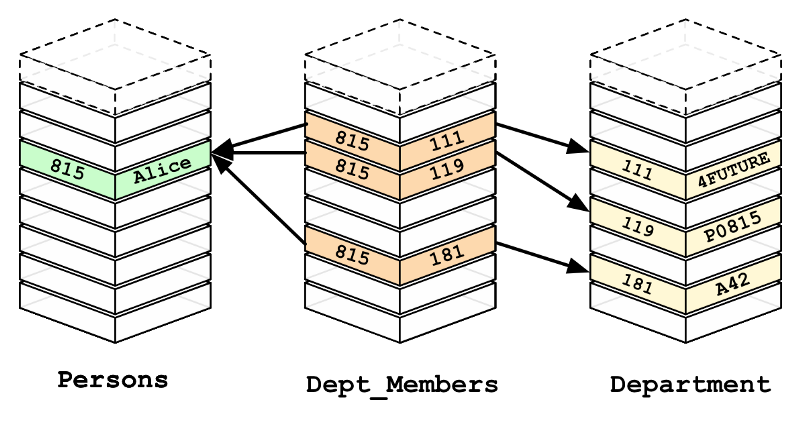 _[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/from_relational_model.png" rel="noopener" target="blank" title=")
_[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/from_relational_model.png" rel="noopener" target="blank" title=")
A graph database, which predetermines relationships.
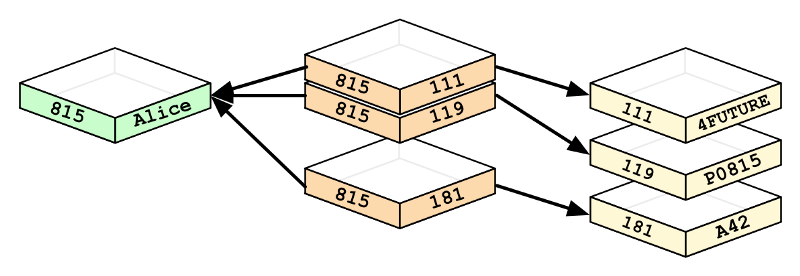 _[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/relational_to_graph.png" rel="noopener" target="blank" title=")
_[Source](https://s3.amazonaws.com/dev.assets.neo4j.com/wp-content/uploads/relational_to_graph.png" rel="noopener" target="blank" title=")
This is some of the basic information you will need to start exploring NoSQL. New databases are being invented for specific uses.
Learn the type of data your application generates, and then it is easy to choose the right database.