
By Armstrong Subero
If you have programmed before, you are sure to have come across hashing and hash tables. Many developers have used hash tables in one form or another, and beginner developers must learn this fundamental data structure. There is just one problem:
All the tutorials you come across are sure to discuss hashing and hash tables in JavaScript, Python, or some other programming language.
What this means is that you may understand a little about how hashing works and how to use a hash table in [insert language here], but may miss the principles of how it works.
Wouldn't it be great if we could learn about hashing without knowing any particular language? If you know how hashing works, and what a hash table is, the language shouldn't matter.
That is the codeless approach, and in this post I will teach you all about hashing and hash tables regardless of which programming language you are currently using. Whether you're a junior or senior dev, everyone will learn something from this post.
So What's a Hash Function Anyway?
Before we get into all the fancy stuff, let me tell you what hashing is. To make it easy let's imagine we have a black box:
 I'm a Black Box
I'm a Black Box
This black box is special. It is called a function box. We'll call it a function box because this box will map an independent variable on the input to a dependent variable on the output (it sounds mathy but bear with me).
Our function box works like this: if we put a letter into the box, we get a number out. Since our box is a function box, there can only be one output for every input into the box.
Our function box will take a letter from A-J on the input and output a corresponding number from 0 to 9 on the output. So if we input C we will get 2 on the output.
 Function Box
Function Box
This forms the basics of what a hash function is. The hash function, however, takes it a step further. We will map data on the input to some numeric value on the output, usually a hexadecimal sequence.
 Hash Function
Hash Function
So essentially all hashing does is it uses a function to map data to a representative numeric or alphanumeric value. For the hash function, regardless of the size of the input, the output will always remain the same.
What about Hash Tables?
So at this point you may be wondering what a hash table is. Hash tables utilize hashing to form a data structure.
Hash tables use an associative method to store data by using what is known as a key-value lookup system. All that means is that, in a hash table, keys are mapped to unique values.
This system of organizing data results in a very fast way to find data efficiently. This is because since each key is mapped to a unique value – once we know a key then we can find the associated value instantly.
Hash tables are extremely fast, having a time complexity that is in the order of O(1).
Confused? Take a look at this diagram, where we have multiple function boxes generating hash values.
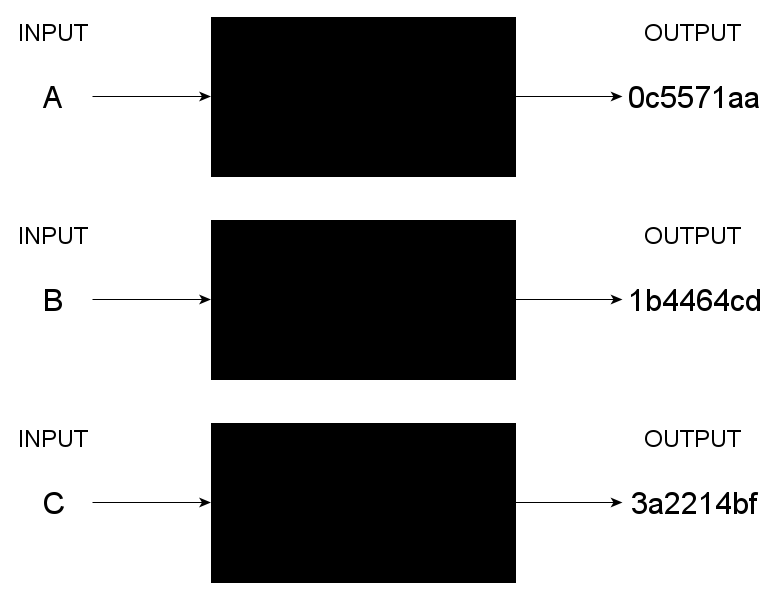 Multiple Function Boxes
Multiple Function Boxes
In this scenario, each character on the input (each is a key) has a hash function applied to it, and the hash function in the function box generates the hash value. This resulting value is then mapped to an index in the underlying linked list or array used to implement the hash table.
The resulting structure will look like this:
 Hash Table
Hash Table
Hash Collisions
This is a good time to talk about collision in hash functions and hash tables.
A function in mathematics is ideal in that an element in the input is mapped to exactly one element in the output.
In a hash function, however, it is not always like this. Sometimes differing hash values in the input may produce the same hash value in the output. When this occurs you get what is known as a hash collision.
Hash collisions are not very common in most use cases, as a small change in the input can produce a dramatically differing output. But the more data you have to input to the hash function, the more likely a collision is to occur.
In the hash table example we provided earlier, we assumed that an array was used to implement the hash table. While this is good for simple hash tables, in practice these are not very good for handling collisions.
As such, a method known as chaining is used. In chaining, if the hash table returns the same hash value for multiple elements, we simply "chain" the elements together with the same hash values at the same index in the hash table.
This way instead of being implemented as an array with an index, we implement the hash table using a linked list where each element is a list rather than merely having a single value assigned to it.
But as the length of the chain increases, the time complexity of the hash table can get worse. A method known as open addressing is also used. In it, alternate locations in the underlying data structure implementing the hash table are found. Just keep in mind that this method will reduce the efficiency of the hash table and has a worse time complexity.
Is Hashing the Same as Encryption or Encoding?
Many people tend to associate hashing with encryption or encoding. So is hashing encryption? Is it the same as encoding?
You see, in encryption we muddle data so that only someone with the key needed to decrypt the data will have access to it. When we utilize an encryption cipher, we not only make the data encrypted, but we also want to decrypt the data at some point. In encryption we want to recover the original data.
Hashing, on the other hand, takes data and produces an output for the purpose of confirming the integrity of data. In hashing we have no intention of recovering the original data.
Encoding differs from encryption and hashing in that the goal of encoding is not to obscure data for any security purpose, but merely to convert the data into a format that another system can use.
What Can I Do with Hashing?
Hashes and hash tables have numerous uses! These include:
- Cryptosystems
- Cyclic Redundancy Checks
- Search Engines
- Databases
- Compilers
Or any system that has a complex lookup process.
Wrapping Up
In this post we've covered the basics of hashing, all without writing a single line of code! This was easy right? The codeless approach is a much easier way of learning about these fundamental topics.
We learned that hash functions can be used to convert objects into a fixed length alphanumeric output. We also learned that hash tables are key-value lookup systems and, while they work well, are not perfect and sometimes suffer from collisions.
By the end of this post you should know the difference between hashing, encryption, and encoding, and also have an idea of where hashes can be used.
Did you like the codeless approach? Want to go further?
Learn about hash tables and other data structures and algorithms in the book "Codeless Data Structures and Algorithms". You'll get an expansion of what was covered in this post and learn about many more topics, all without writing a single line of code!