
By Patrick Ferris
I love the web. It is a modern-day superpower for the dissemination of information and empowerment of the individual. Of course, it has its downsides like trolling (largely possible through anonymity) and privacy issues, not to mention the problems of ownership and copyright infringement about to come into effect with the highly divisive article 13. But, let’s forget about that for just a moment and marvel at the technological innovation of the internet and the browsers which support it.
I first learnt to code in Javascript and have since been ridiculed by many for liking it. Yes, I know there are weird bits like this gem: [] == ![] // true but it has become one of the most ubiquitous languages on the planet thanks to the internet, browsers and the interpreters that run the code (Google’s V8 and Firefox’s SpiderMonkey to name a few).
As I got more into web development, I noticed a new name on the block: WebAssembly. As a computer science student and a developer, I believe one of the best ways to learn something is to try and understand why the engineers who built it made those design choices. So here is a brief look at some of the interesting design principles in WebAssembly and also why I think everyone should be excited.
Why do we need WebAssembly?
Okay, so first of all, to all my Javascript fans out there — no you shouldn’t be worried. When Javascript first came about, it was designed to be used in a lightweight way but has since gone on to do a lot of heavy lifting. Maybe it was used for manipulating some DOM elements, some client-side verification in forms but not everything that is trying to be done on the web now. Certainly not running fully-fledged games.
Why is Javascript not so fast or great? One of the main reasons is because it is an interpreted language. Scanning the code line by line and executing, luckily with Just-in-Time compilers, the efficiency improved massively but still there is only so much room to improve. But even then there’s the issue of Javascript’s dynamic typing causing another ceiling on performance
Alex Danilo discussed the improvements WebAssembly could make in his Google I/O talk in 2017. What really brought home the inefficiencies was his example add(a, b) function and the complexity that the Javascript interpreters have to go through in order to make sense of it.
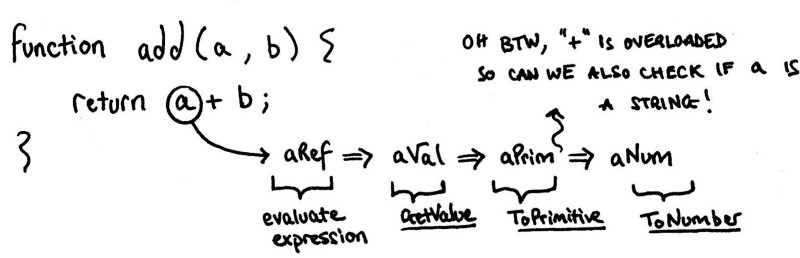 _A simple Javascript function — [ECMAScript Rabbit Hole p.263](https://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf" rel="noopener" target="blank" title=") (be sure to follow the links of the other function calls)
_A simple Javascript function — [ECMAScript Rabbit Hole p.263](https://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf" rel="noopener" target="blank" title=") (be sure to follow the links of the other function calls)
WebAssembly opens the door to compilation, which opens another door to optimisation. It’s ability to take C/C++ source language allows it to do some static type checking which helps improve speed. This is what the developers of the Mozilla Foundation realised and wanted to fix. To summarise this great video, Javascript was designed for humans and browsers were left to try and make it fast; WebAssembly was designed as a target language for compilers that browsers could already run quickly.
The realisation that we could have two choices of code run in the engines was an exciting prospect — and the four major browsers (Chrome, Safari, Firefox and IE) all began plans to let their engines run Javascript and WebAssembly. Again, let me reiterate… WebAssembly is not replacing Javascript.
Why compile code?
Compiling code really means taking it from one (source) language and translating it into another (target) language. This is an incredibly simplified understanding of compilation. Most modern day compilation pipelines involve many more stages that allow us to really fine-tune and optimise our code making it faster and more energy-efficient.
The first steps usually include lexical, syntactic and semantic analysers to get the code into some kind of intermediate language that is perfect for optimisation. Then we optimise independently, generate the target code and then maybe optimise dependently on the hardware or environment.
All projects need to start small first, and the engineers at Mozilla decided to begin with their source language being C/C++ and using an existing toolchain called LLVM (not an acronym) they would compile using that.
Initially, the search for a better performing web started with [asm.js](http://asmjs.org/spec/latest/) (at least in WebAssembly narrative. See PNaCL — Google’s earlier attempts) a small subset of Javascript that could be the compile target for C/C++ programs that used annotations and other clever tricks to improve the Javascript performance.
Unfortunately, it lacked one crucial design principle underlying what was wanted: Portability. Different Javascript engines gave different performance reviews, but it was a clear indication that this may be a good approach.
The developers of WebAssembly decided their target representation would be a binary format that provided a “dense, linear encoding of the abstract syntax”… Which is a lot of words, so let’s unpack that.
The “dense” part refers to the high-level goal of achieving a size and load time efficient format. The internet is all about sending data along wires, and whilst there are lots of projects to improve the latency of this, one foolproof way of achieving this is to send less data. Another important aspect is the increased decoding speed thanks to array indexing over dictionary lookup (if they used compressed text format). Read more about this design choice here.
What is wat?
The binary format that the C and C++ programs compile to are .wasm files, these have a 1:1 mapping straight to a (somewhat) human readable text format. These files are labelled .wat , this WasmExplorer is great for getting your head around text representation and how it relates to the original code. Let’s take a simple example.
There’s a lot going on here so let’s take it slowly and explain the concepts as they come.
First, there is this weird module word, where did that come from? Mejin Leechor gave a great talk on modules in Javascript and describes them as giving code “structure and boundaries”. This is very similar to the idea of WebAssembly modules (and there are plans in the future to try and integrate with es6 modules).
Straight from the docs, we have that the module is the “distributable, loadable, and executable unit of code in WebAssembly”. Modules can have the following sections each with their own unique responsibility: import, export, start, global, memory, data, table, elements, function and code. For now, let’s just look at what we have in our module.
The first declaration is (type $type0 (func (param i32) (result i32))) . This is intimately linked to the table call on the next line. We are declaring a new type with the func signature that takes a 32 bit integer parameter and returns a 32 bit integer. If we were to make use of the function we wrote again, we would have to make a call_indirect into our table and then we could do some type-checking to make sure everything was correct. As part of the minimal viable product only one table is allowed, but there are future plans to allow multiple tables and for these to be indexed.
The next declaration is (table 0 anyfunc) . The table section is reserved for defining zero or more tables. A table is similar to a linear memory in the sense that they are resizable arrays which contain references. The 0 makes reference to the fact that we have nothing in our table, but we still need to provide the MVP’s only possible value of anyfunc (a function).
The problem that the developers had was linked to security. If a function wanted to call another function, giving it direct access to a function stored in linear memory was unsafe. Instead functions are stored in the table ready to be indexed if needed. Lin Clark wrote a great article describing tables (as used in imports) in more detail and how they provide better security.
We then have a declaration of (memory 1) , this is the linear memory used by the module and we declare that we need 1 page of memory (64KiB).
The next declaration is (export "memory" memory) . An export is something that is returned to the host at instantiation time. Basically, the cool bits we want from the WebAssembly code.
The structure is quite simple (export <name-of-export> (<type> <name/index>)) so here we are just exporting the memory we declared in the previous line. This allows for direct memory access within our Javascript code, as an ArrayBuffer which drastically improves the efficiency as there are no backwards and forwards calls across the WASM/JS border. Similarly we then export our function with (export "main" $func0) .
Now to the slightly more interesting bit, our code and its representation.
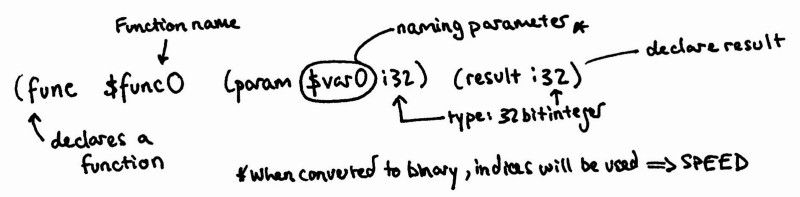 The different parts of the function declaration in WebAssembly Text Format
The different parts of the function declaration in WebAssembly Text Format
Before moving on, this is the perfect opportunity to introduce yet another design component: the stack machine.
Register versus Stack Machines
Computers, at their simplest, consume inputs and produce outputs. As a ‘machine’ executes a program it can do so in multiple different ways. Two of the main approaches are register and stack machines. In a register machine, parameters to functions are kept in memory locations and are then manipulated depending on the program in execution.
A simple, but somewhat flawed, analogy could be a kitchen and making a recipe. The ingredients are stored in different locations, you get them and make something which you might put somewhere for another day or immediately consume (yum). It’s far from perfect but hopefully you get the idea.
Stack machines, on the other hand, employ a different model. Imagine you are a journalist or secretary, your job is to read and respond to letters. You ‘pop’ the top letter from your pile and begin writing a response whilst someone else comes along with more work and ‘pushes’ to the top of the pile. These are the ones you are going to have to do next. Again, grossly oversimplified but it should help visualise the mechanics.
WebAssembly uses a stack machine model for code execution. If you’re short of some great reading, and are into programming semantics, the paper “Bringing the Web up to Speed with WebAssembly” is really good. It also indicates why they choose the stack machine representation: “The stack organization is merely a way to achieve a compact program representation, as it has been shown to be smaller than a register machine” with reference to this paper which found “… the bytecode size of the register machine being only 26% larger than that of the corresponding stack one”.
Even though the stack machine approach isn’t necessarily faster, it offered smaller bytecode; an incredibly important design goal for internet-based transactions.
So how can we understand the text-format as a stack machine. As we read the code line by line we end up pushing arguments to the stack, then popping them off, doing some computation and pushing the result back. And repeat.
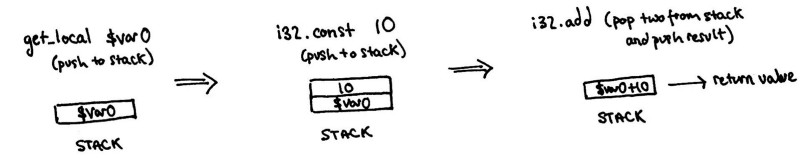 A small example of WebAssembly and the implicit stack machine approach
A small example of WebAssembly and the implicit stack machine approach
At first it might seem a little odd to have a text format, if in the end it will be compiled to the binary format for compression. But, the internet has always had the policy of viewing the source and that’s why the developers behind WebAssembly produced the text format. To go one step further and avoid conflicts of syntax they used the Lisp-like s-expression style.
Safety and Sandboxing
One of the greatest sources of bugs (and exploits) in unsafe languages is buffer overflows. C and C++ are almost interchangeable with this idea and it is one of the first aspects you are taught when learning these languages. In exchange for a little overhead costs, WebAssembly adds this safety net by enforcing fixed-sized, indexed memory (although certain memory can be grown).
The local variables to our function, for example$var0 , are not referenced by address but instead are indexed providing a layer of security. Access is granted via the get_local and set_local commands which all happens within the index space of the local variables.
Memory security was a top priority when designing WebAssembly. Straight from the documentation: “Linear memory is sandboxed; it does not alias other linear memories, the execution engine’s internal data structures, the execution stack, local variables, or other process memory.” Lin Clark, again, wrote a great article describing this.
The basic idea is comparable to the Javascript ArrayBuffer object — resizable and bound-checked. What we’re trying to achieve is program isolation to prevent errors and malicious code from spreading and corrupting data it shouldn’t even have access to.
What can WebAssembly do?
One of the major end-goals for WebAssembly was revolutionising what was possible in terms of graphics on the web. The classic examples are ZenGarden by EpicGames and Tanks!.
Thanks to its design, WebAssembly marks a pivotal moment in web development. The internet has a new tool in its arsenal to create amazing experiences and share information. WebAssembly provides smaller code-sizes, faster execution, greater security and a lot of room for extensibility. With ideas like threads, single-instruction multiple-data (SIMD) primitives and zero-cost execution on the horizon, WebAssembly’s abilities look only set to expand.