By Oguz Gelal
The standardization of transactional state management brought predictability to front-end development. Then with immutability and single-source-of-truth for state, applications became more maintainable and robust. However, there is still some ambiguity surrounding what to do with the business logic.
I propose a model where the business logic gets operated under the same command channel that the reducers use. Managing logic with the same unidirectional transactions brings many benefits during development. I will first walk through the problem in more detail. Then, I will explain how this model works over Reclare, the library that implements this model. Finally I will discuss some of these benefits.
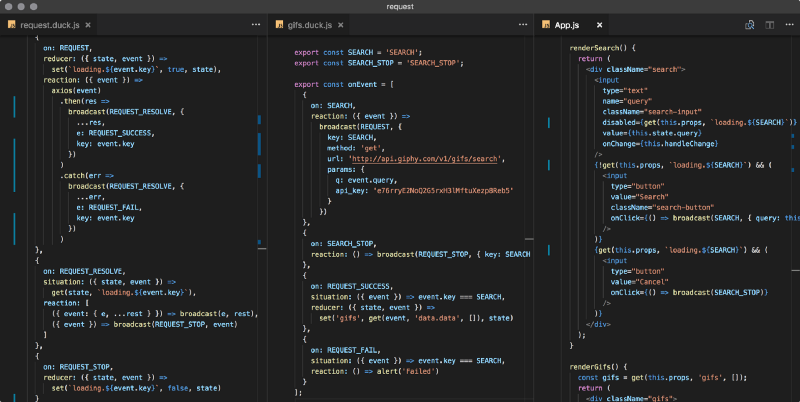 _From the [React-Reclare](https://github.com/reclarejs/reclare/tree/master/examples/request" rel="noopener" target="_blank" title="">request example with Reclare and <a href="https://github.com/reclarejs/react-reclare" rel="noopener" target="blank" title=")
_From the [React-Reclare](https://github.com/reclarejs/reclare/tree/master/examples/request" rel="noopener" target="_blank" title="">request example with Reclare and <a href="https://github.com/reclarejs/react-reclare" rel="noopener" target="blank" title=")
Eternal struggle with data
In the early days, people used to build user interfaces with plain HTML and CSS. They handled DOM (document object model) manipulations using JavaScript or jQuery. It was reasonable back then — front-end applications were simple and not as data-driven. But then the responsibility grew into fetching and handling data, instead of only displaying it. DOM manipulation lost its feasibility.
Front-end frameworks solved this problem by having DOM reflect the underlying state of the application. Developers no longer had to worry about updating the DOM, but managing the state was still on their plate.
Then modern state management started to gain some ground. Elm and Flux standardized event-sourcing-style transactional state management in front-end development. How and when the state can update got restricted with unidirectional data flows. This brought predictability to the state, made it easier to follow and reason with.
Redux made a breakthrough with immutability and single-source-of-truth for state. It also introduced flexible, pure, functional and composable reducers. These brought some advantages over the Flux architecture, but there is still some ambiguity about how to handle business logic and where it should live. There are many articles and discussions on this topic, but no clear answer seems to exist.
This got me confused as much as it confused others. I decided to address this problem and find a clean way to handle business logic in my applications. Then I came up with the idea of bundling business logic together with reducers. This allowed logic to operate together with reducers under the same event channel.
I realized that this approach brought more than just some organizational benefits. It brought other advantages like predictability and declarativeness in logic. There was a need for a library to orchestrate logic together with the state and maintain all the benefits of modern state management. This is when I decided to create Reclare.
Brief Introduction to Reclare
Reclare is a simple library that revolves around declarations and events. A declaration is a simple object invokable by Reclare. It describes the situational condition for it to invoke, and what to do if its invocation takes place. It’s reaction could be updating the state, executing logic / side-effects, or both. Here is what a declaration looks like:
It is a general purpose API and there are different kinds of declarations. Different kinds gets invoked in different ways. Currently there are two kinds: event and subscription declarations.
Event declarations listen to the event channel and subscribe to specific events. The broadcast method could be used to broadcast events to the event channel. The first parameter is the event key, followed by the event payload. This payload gets passed on to the declaration functions.
broadcast("event_key", { bar: 'foo' })
Subscription declarations get invoked upon every state change. Depending on the declaration type, the functions may receive extra parameters, but the structure does not change.
When Reclare context gets created, all declarations get merged by their on keys. This reduces the complexity of finding declarations on broadcasts to O(1) time. It also makes working with declarations very natural, as it is possible to have multiple declarations with the same event key. Here is an example:
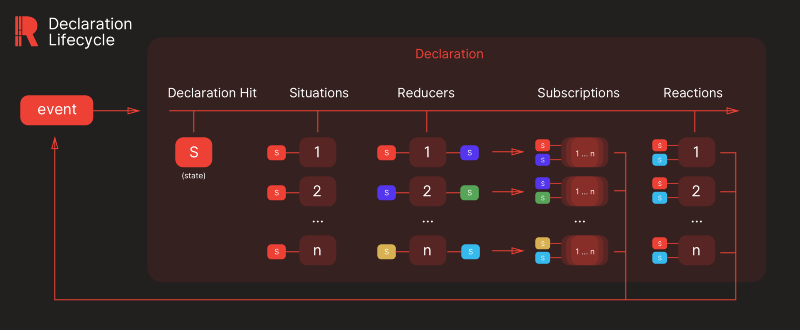 The lifecycle of declaration invocation
The lifecycle of declaration invocation
Declaration Lifecycle
The declaration lifecycle begins when one or more declarations get triggered. First, all situation functions of all declarations that have the broadcasted event on their on key get evaluated. If the situational condition holds, reducers and reactions of that declaration get queued. Then, the queued reducers start getting executed.
Each one receives the state and returns a new state, which is then piped on to the next one. Each reducer triggers the subscription declarations. They receive the state before and after the reducer that triggered them. Next, the queued reactions get executed. Each reaction receives the initial and the current state as arguments. They get executed after the reducers, so the state they receive is at its final. The event payload gets passed on to every function executed on each step.
Benefits
Modern state management libraries focus only on managing the application state. The logic behind the scenes is usually overlooked. There are benefits in operating the state and business logic together. Granted there needs to be a separation between the two. The impurities and side effects of logic should be kept away from the management of the state. But they functionally belong to each other, so they should coexist and be operated together.
Predictable logic
Managing business logic with the same unidirectional transactions with reducers brings a similar predictability to logic that it does to the state. It makes it easier to reason with, follow, understand and test the code.
Predictability in the context of business logic is not a one-to-one comparison to the predictability of the state, but the underlying idea is the same. Broadcasted events can be recorded with their payloads and the invocations they caused. Thus, it is possible to travel back in the event history to tell what happened in the course of execution. You could investigate which declarations got invoked, which reactions they executed, and how they changed the state.
Code Structure and Fragmentation
A typical front-end codebase contains many different types of entities. For instance, a typical React + Redux + redux-saga codebase would have containers, components, actions, reducers, types, selectors, sagas, services and others depending on the selection of libraries. Dan Abramov mentions in his article You might not need Redux:
People often choose Redux before they need it. “What if our app doesn’t scale without it?” Later, developers frown at the indirection Redux introduced to their code. “Why do I have to touch three files to get a simple feature working?” Why indeed!
You shouldn’t have to touch three different files to work on a single function. Codes that have functional relevancy should not get fragmented into different entities. They should be grouped and handled together instead.
Reclare attempts to make this ordeal more pleasant with declarations and duck files.
Declarations are bundles that hold reducers together with reactions. Since they execute upon the same event, they will be functionally relevant.
The duck files’ approach is based on the ducks modular redux by Erik Rasmussen. It is a proposal to bundle shattered pieces of Redux together as an isolated module.
Reclare follows this pattern in its own way. It allows bundling declarations and other relevant entities together into a single file. Moreover, it supports composition, allowing you to have logical parent-child relationships. Duck files can export other entities like constants and selectors. It is a simple yet handy way to divide your code into modules.
Modularity and Declarativeness
Reclare operates both reducers and reactions together with uni-directional transactions. This allows you to build your logic in a declarative and modular nature. I will explain with a simple login scenario:
The login form component broadcasts login_submitted with email and password on submit. It also receives the loading status in the props, which gets handled by the request module below.
Above is the module that manages the login process. The first declaration gets invoked on login_submitted if the input is valid. It broadcasts the on_request event with the request details. Notice how it doesn’t care at all about handling the requests? The module is only interested in the outcome of the requests of type login.
The next two declarations listen to the request_success and request_fail events. Upon those events, if the request type condition holds, they will get invoked. The first one saves the user to the state and triggers a route change, and the second one shows an error message.
This is an example of a general purpose module which handles the requests and loading states. The first declaration gets invoked on on_request event. Once invoked, it will set the loading state for the request type, and then start the request. Then based on the outcome, it will broadcast request_success or request_fail events. It will also broadcast request_resolved, which terminates the loading state.
There are two take-aways from this example. The first is how the business logic is managed. Most state management libraries using unidirectional data flows will allow you to manage the state declaratively. But with Reclare, you can take advantage of this pattern to manage your business logic as well.
Second is the modularity. Every declaration and module is an isolated piece of code that gets invoked by particular events. The declarations receive a payload and does their thing: performs a set of actions and / or updates the state. They are unaware and unaffected by other parts of the code.
This will help you to keep the mental mapping of your code even when it scales. It also brings many advantages while testing your code.
Final Words
Since I’ve completed the implementation and tests of Reclare, I’ve used it a few times on side projects and production environments at work. So far it’s been a fun experience, and I had nothing but success with it. I truly hope Reclare can be of help to the community as much as it has helped me.
One last thing: there is an official React middleware built on top of the new Context API. When I wrote this article, Reclare was ready for usage in a React project. It can also be used without the middleware on any JavaScript project. I will look into creating middlewares for other frameworks (unless someone else wants to do it ?).
As for the future plans, here is a short-term roadmap:
- Creating Reclare DevTools for debugging
- I will also be looking into Redux DevTools integration
- More documentation and examples
- Contribution guidelines
- TypeScript support
- Tests and improvements on React-Reclare
- Ability to extend the declaration API
reducerDefault/reactionDefault
You can also find some examples on the repositories:
Reclare — https://github.com/reclarejs/reclare
React-Reclare — https://github.com/reclarejs/react-reclare
