

Yesterday GitHub — the center of the open source universe — went down for three hours.
If you’re new to software development, it may seem strange that a website going down for three hours would warrant an article.
This outage is newsworthy for two reasons. First, because these kinds of outages are rare. GitHub’s last major outage was in 2010, when its CEO accidentally destroyed its production database.
 The last time GitHub’s 500 page was widely seen was way back in 2010.
The last time GitHub’s 500 page was widely seen was way back in 2010.
Second, GitHub is now the 87th most-trafficked site on the internet, worth $2 billion, and has a team of nearly 500 people — most of whom are engineers.
A website that’s built for developers, by developers, with a strong engineering culture, crashing in the middle of a work day — that’s a stark reminder of how hard web development really is.
While we await GitHub’s forthcoming post-mortem of the outage (update: it was a power outage), let’s explore the concept of “availability”, and talk about why it’s so important.
High availability — uptime, downtime, and lots of nines
First, let’s cover some terminology you’ll hear developers throw around.
Uptime is when a service is available and responding to requests. You’re reading this article on Medium, so that means that Medium is up. Now is Medium’s uptime.
Uptime’s arch nemesis is downtime — when a service is not responding to requests.
Unless a service was scheduled to go down for a planned outage (maintenance) — or there’s a network connectivity issue — downtime usually means that servers have crashed. Somewhere, a developer is frantically trying to get these servers back up, so they can salvage their career prospects at their current employer.
Availability is the ratio of uptime to downtime. It’s expressed in “nines.” You’ll hear someone say “We’ve got five nines uptime.” That means that the service is available 99.999% of the time (uptime), and only down 0.001% of the time (downtime).
So what do these numbers look like to humans like you and me?
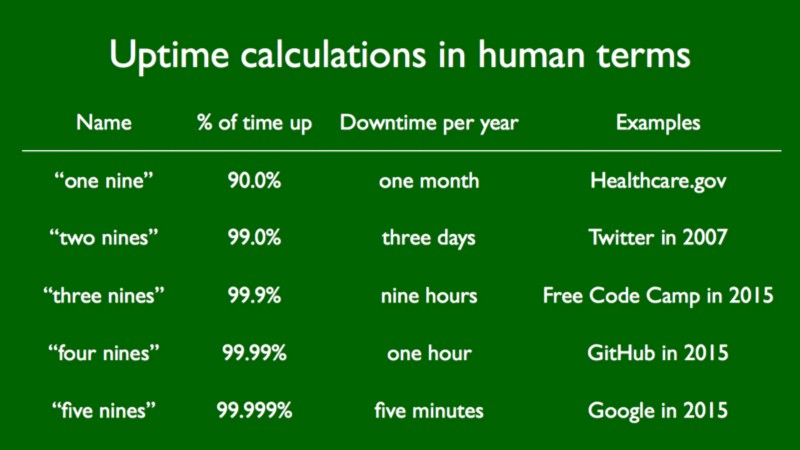
The gold standard of high availability is usually considered five nines.
As you can see, going down for more than an hour in total during the same year knocks you down to “three nines.” Sorry GitHub, I guess you’re going to be stuck down here in the “three nines” club with Free Code Camp this year.
Free Code Camp hasn’t actually gone down for more than a few seconds so far in 2016, but we plan to go down for a few minutes at a time throughout the year (planned outages) — usually late at night in the western hemisphere. And this will probably add up to more than an hour in total.
For us, three nines is fine. Because getting to high availability is hard, and usually costs a lot of money.
Why is high availability such a big deal?
High availability is expensive to achieve. Adding an extra nine to your availability may involve millions of dollars in developer time and redundant infrastructure. So why bother?
If you saw the brooding 2010 hatchet job movie “The Social Network”, you may remember the scene were Mark Zuckerberg’s character talks about the importance of availability. “We don’t crash ever. If the servers are down for even a day, our reputation is irreversibly destroyed.”

Did you see this quote and think: “down for even a day — gee, that already puts you all the way down at two nines!” If so, thanks for taking the time to read my chart.
Whether this quote is hyperbole — Twitter used to crash all the time and it didn’t “irreversibly destroy” its reputation — going down does make you look marginally less professional, at least to other developers. So the less you go down, the better.
 _Twitter’s infamous “fail whale”. For curious readers, here’s a [one-hour talk](https://vimeo.com/53693402" rel="noopener" target="blank" title=") on how they eventually solved their uptime woes by restructuring.
_Twitter’s infamous “fail whale”. For curious readers, here’s a [one-hour talk](https://vimeo.com/53693402" rel="noopener" target="blank" title=") on how they eventually solved their uptime woes by restructuring.
Another reason high availability is important is that downtime can literally cost some companies millions of dollars in lost revenue.
Amazon grossed $81 billion in 2014. There are 525,600 minutes in a year. So Amazon sells $156,110 worth of stuff each minute.
The difference between “four nines availability” and “five nines availability” is about 47 minutes per year, which for Amazon comes out to more than $7 million in revenue.
How can I maximize uptime without breaking the bank?
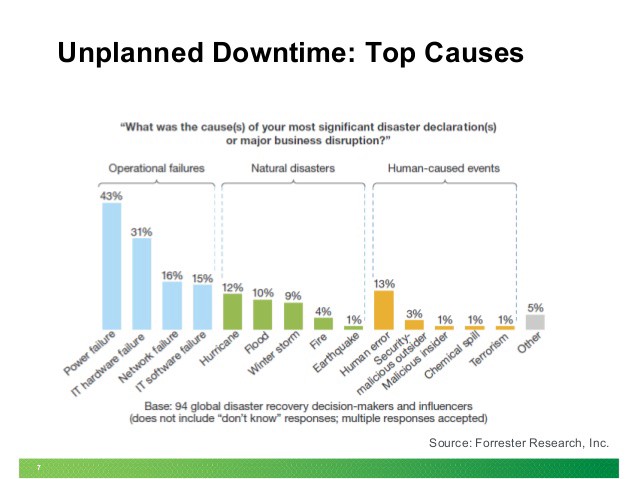 There’re acts of God, and then there’re acts of humans.
There’re acts of God, and then there’re acts of humans.
Here are some fast and inexpensive ways you can maximize the uptime of your website by preventing avoidable mistakes:
- Write automated tests, and if possible, use a Continuous Integration tool to catch broken tests before you deploy new code.
 We use Travis CI integrated into GitHub to ensure all our tests pass before we accept pull requests.
We use Travis CI integrated into GitHub to ensure all our tests pass before we accept pull requests.
- Create a local testing environment that’s as close to your production website as possible (one way to do this is to use Docker).
- Create a staging environment that mimics your production environment, and have your team members QA fixes and features there.
- Make sure your test and staging environments can’t access your production data (this was what caused GitHub’s big 2010 outage).
- Don’t push code to production late at night. Most of Free Code Camp’s unplanned downtime have been caused by bad judgement (usually mine) after pulling all-nighters. Take it from me — no feature is worth crashing production over. When in doubt, sleep on it!
I hope this article inspires you to pursue the number of nines that’s right for you.
Oh, and don’t go to hard on yourself if you occasionally do something dumb and crash your website. If it can happen to the awesome engineers at GitHub, it can happen to anyone.
I only write about programming and technology. If you follow me on Twitter I won’t waste your time. ?