By Filipe Tavares
I love Node.js. I’ve re-discovered Javascript through it, and I’m never going back.
Its lightweight character, non-blocking nature, and quick development experience shine in Microservices.
I also love Express — it makes writing server applications so simple. And its Connect-based middleware stack approach makes extending applications easy and fun. Couple it with Docker and the sky’s the limit. Or, better yet, go serverless.
Smaller than small…

First they gave us Servers, so we built Service-Oriented Architectures.
Then they gave us Containers, so we built Microservices.
Now they give us Serverless Event Handlers, so we’ll build Functions.
Our hosting platforms have become more amenable to deploying smaller units. And so have our applications broken down into smaller software packages. There are many reasons for this, and there are diverging opinions on whether it’s a good thing.
But if we look back at the original concepts behind cloud computing, there was a dream of having code distributed infinitely in a network of connected computation nodes. We’re getting a little closer with the emergence of serverless platforms.
Plus: they allow us to scale infinitely, while only paying for what we use.
…but not too small
Sequences of computational steps (procedures) need shared memory to execute efficiently. We wrap those around a function definition, that defines a contract for its input and output. And this allows composition with other such functions.
This approach has been very successful in the architecture of Unix, and is one of the reasons for its longevity and ubiquity. I don’t mean to suggest that Web applications should follow a comparable cloud-based shared eco-system (though some are trying). But we can benefit from applying similar principles when building Web applications.
Beyond function definitions, we also group closely related functions in modules. An example could be the CRUD operations for data within a given domain, such as user management. Those tend to share code, like data models, parsing logic and formatting. So when we deploy individual functions to serverless environments, we end up with lots of duplicated code.
Current serverless environments encourage single-function deployment. But, when applied to Microservices, that leads to messy stacks that are hard to manage.

But let’s assume we don’t mind duplicated code deployments. After all, we can deal with it in our code repositories. We still want to share temporary resources, though, such as database connections. We also want to make sure that we deploy and manage all operations for the same domain as a single unit. We’re better off managing function modules.
It fits well with the Single Responsibility Principle:
Gather together those things that change for the same reason, and separate those things that change for different reasons.
Going serverless
So, Node.js is great for Microservices. And it’s also great for writing smaller function modules. And Express is great for building Web application in Node.js.
Yet, most serverless environments already handle many common Web server functions out of the box. And for these Nanoservices, that provide a mere handful of functions, we shouldn’t bother with the overhead of complex Web server logic. We must leverage HTTP, as it is the ubiquitous transport mechanism between Web services. But we should do it in a more RPC (Remote Procedure Call) kind of way.

This is where most current frameworks offer a sledgehammer to crack a nut. If anything, I’d argue that going serverless frees us from frameworks, to focus instead on building purer functions.
Yet, there is a need for basic routing within a Nanoservice, to map incoming requests to the appropriate handler function. Also, because of the proprietary nature of these commercial serverless environments, we can make a case for having a certain level of abstraction, to decouple our functions from the specifics of the platform they’re executed in.
Functional programming applied to serverless deployments is likely to surface in more applications. Which I’m very hopeful about, because it feels like a step in the right direction. We still need to address many real-world considerations like latency, performance, and memory usage. But like with Microservices, we’ll find the right set of tools and practices to make this not just practical, but also highly performant on real-world applications.
Modules in Cloud Functions
I wrote a small Node.js package to address these needs. It’s called modofun.

It carries no extra dependencies, because we want our deployments to be as small as possible. It adds minimal functionality to simplify deployments of function modules on serverless platforms. It also allows extensibility through existing middleware, such as authentication, logging, and others. Here are a few of its features:
- Basic routing to functions
- Parameter parsing
- Automatic HTTP response building
- Support for ES6 Promises (or any other then-able)
- Connect/Express-like middleware support
- Google Cloud Functions
- AWS Lambda (with AWS API Gateway events)
- Automatic error handling
Support for Azure Functions coming shortly.
Using Modofun
Modofun makes it easy to expose functions as serverless cloud request handlers:
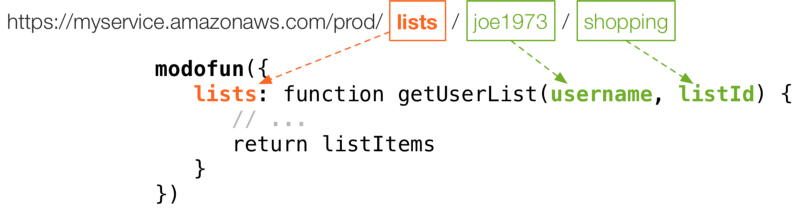
A simplistic router maps incoming requests to functions. It applies the trailing components of the URL path as function arguments. Other request data is also available as context (this) for the function invocation.
We can specify middleware that will run for every incoming request. Or apply it selectively to individual functions (more details in the documentation). Modofun returns the appropriate handler for events generated by the serverless platform.
Get it with npm:
npm install modofun
For more examples and detailed documentation, head to the official website. You can also find the full source code on GitHub.