

Welcome to the world of web scraping! Have you ever needed data from a website but found it hard to access it in a structured format? This is where web scraping comes in.
Using scripts, we can extract the data we need from a website for various purposes, such as creating databases, doing some analytics, and even more.
Disclaimer: Be careful when doing web scraping. Always make sure you're scraping sites that allow it, and performing this activity within ethical and legal limits.
JavaScript and Node.js offers various libraries that make web scraping easier. For simple data extraction, you can use Axios to fetch an API responses or a website HTML.
But if you're looking to do more advanced tasks including automations, you'll need libraries such as Puppeteer, Cheerio, or Nightmare (don't worry the name is nightmare, but it's not that bad to use 😆).
I'll introduce the basics of web scraping in JavaScript and Node.js using Puppeteer in this article. I structured the writing to show you some basics of fetching information on a website and clicking a button (for example, moving to the next page).
At the end of this introduction, I'll recommend ways to practice and learn more by improving the project we just created.
Prerequisites
Before diving in and scraping our first page together using JavaScript, Node.js, and the HTML DOM, I'd recommend having a basic understanding of these technologies. It'll improve your learning and understanding of the topic.
Let's dive in! 🤿
How to Initialize Your First Puppeteer Scraper
New project...new folder! First, create the first-puppeteer-scraper-example folder on your computer. It'll contain the code of our future scraper.
mkdir first-puppeteer-scraper-example
Now, it's time to initialize your Node.js repository with a package.json file. It's helpful to add information to the repository and NPM packages, such as the Puppeteer library.
npm init -y
After typing this command, you should find this package.json file in your repository tree.
{
"name": "first-puppeteer-scraper-example",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^19.6.2"
},
"type": "module",
"devDependencies": {},
"description": ""
}
Before proceeding, we must ensure the project is configured to handle ES6 features. To do so, you can add the "types": "module" instruction at the end of the configuration.
{
"name": "first-puppeteer-scraper-example",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^19.6.2"
},
"type": "module",
"description": "",
"types": "module"
}
The last step of our scraper initialization is to install the Puppeteer library. Here's how:
npm install puppeteer
Wow! We're there – we're ready to scrape our first website together. 🤩
How to Scrape Your First Piece of Data
In this article, we'll use the ToScrape website as our learning platform. This online sandbox provides two projects specifically designed for web scraping, making it a great starting point to learn the basics such as data extraction and page navigation.
For this beginner's introduction, we'll specifically focus on the Quotes to Scrape website.
How to Initialize the Script
In the project repository root, you can create an index.js file. This will be our application entry point.
To keep it simple, our script consists of one function in charge of getting the website's quotes (getQuotes).
In the function's body, we will need to follow different steps:
- Start a Puppeteer session with
puppeteer.launch(it'll instantiate abrowservariable that we'll use for manipulating the browser) - Open a new page/tab with
browser.newPage(it'll instantiate apagevariable that we'll use for manipulating the page) - Change the URL of our new page to
http://quotes.toscrape.com/withpage.goto
Here's the commented version of the initial script:
import puppeteer from "puppeteer";
const getQuotes = async () => {
// Start a Puppeteer session with:
// - a visible browser (`headless: false` - easier to debug because you'll see the browser in action)
// - no default viewport (`defaultViewport: null` - website page will in full width and height)
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open a new page
const page = await browser.newPage();
// On this new page:
// - open the "http://quotes.toscrape.com/" website
// - wait until the dom content is loaded (HTML is ready)
await page.goto("http://quotes.toscrape.com/", {
waitUntil: "domcontentloaded",
});
};
// Start the scraping
getQuotes();
What do you think of running our scraper and seeing the output? Let's do it with the command below:
node index.js
After doing this, you should have a brand new browser application started with a new page and the website Quotes to Scrape loaded onto it. Magic, isn't it? 🪄
 Quotes to Scrape homepage loaded by our initial script
Quotes to Scrape homepage loaded by our initial script
Note: For this first iteration, we're not closing the browser. This means you will need to close the browser to stop the running application.
How to Fetch the First Quote
Whenever you want to scrape a website, you'll have to play with the HTML DOM. What I recommend is to inspect the page and start navigating the different elements to find what you need.
In our case, we'll follow the baby step principle and start fetching the first quote, author, and text.
After browsing the page HTML, we can notice a quote is encapsulated in a <div> element with a class name quote (class="quote"). This is important information because the scraping works with CSS selectors (for example, .quote).
 Browser inspector with the first quote
Browser inspector with the first quote <div> selected
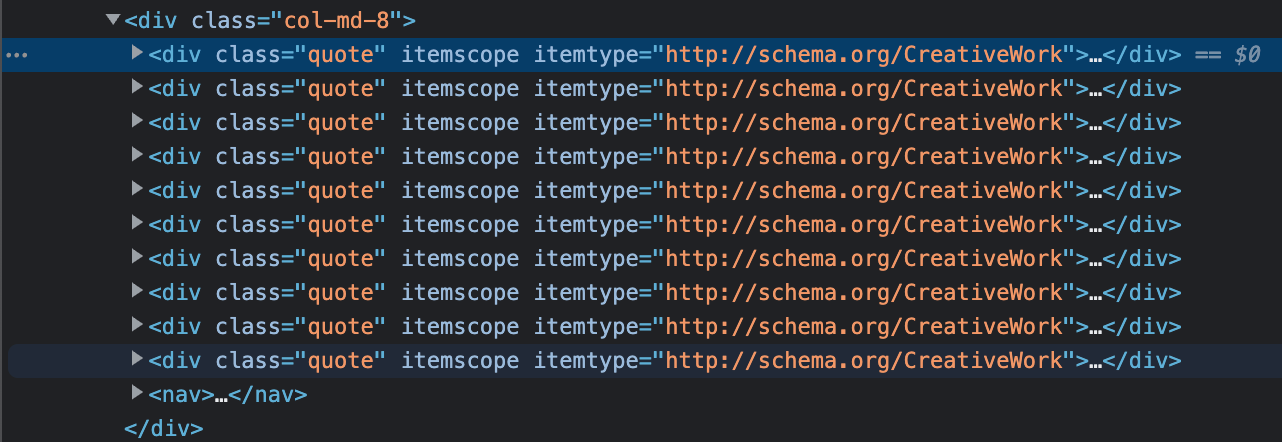 An example of how each quote is rendered in the HTML
An example of how each quote is rendered in the HTML
Now that we have this knowledge, we can return to our getQuotes function and improve our code to select the first quote and extract its data.
We will need to add the following after the page.goto instruction:
- Extract data from our page HTML with
page.evaluate(it'll execute the function passed as a parameter in the page context and returns the result) - Get the quote HTML node with
document.querySelector(it'll fetch the first<div>with the classnamequoteand returns it) - Get the quote text and author from the previously extracted quote HTML node with
quote.querySelector(it'll extract the elements with the classnametextandauthorunder<div class="quote">and returns them)
Here's the updated version with detailed comments:
import puppeteer from "puppeteer";
const getQuotes = async () => {
// Start a Puppeteer session with:
// - a visible browser (`headless: false` - easier to debug because you'll see the browser in action)
// - no default viewport (`defaultViewport: null` - website page will in full width and height)
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open a new page
const page = await browser.newPage();
// On this new page:
// - open the "http://quotes.toscrape.com/" website
// - wait until the dom content is loaded (HTML is ready)
await page.goto("http://quotes.toscrape.com/", {
waitUntil: "domcontentloaded",
});
// Get page data
const quotes = await page.evaluate(() => {
// Fetch the first element with class "quote"
const quote = document.querySelector(".quote");
// Fetch the sub-elements from the previously fetched quote element
// Get the displayed text and return it (`.innerText`)
const text = quote.querySelector(".text").innerText;
const author = quote.querySelector(".author").innerText;
return { text, author };
});
// Display the quotes
console.log(quotes);
// Close the browser
await browser.close();
};
// Start the scraping
getQuotes();
Something interesting to point out is that the function name for selecting an element is the same as in the browser inspect. Here's an example:
 After running the
After running the document.querySelector instruction in the browser inspector, we have the first quote as an output (like on Puppeteer)
Let's run our script one more time and see what we have as an output:
{
text: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
author: 'Albert Einstein'
}
We did it! Our first scraped element is here, right in the terminal. Now, let's expand it and fetch all the current page quotes. 🔥
How to Fetch All Current Page Quotes
Now that we know how to fetch one quote, let's trick our code a bit to get all the quotes and extract their data one by one.
Previously we used document.getQuerySelector to select the first matching element (the first quote). To be able to fetch all quotes, we will need the document.querySelectorAll function instead.
We'll need to follow these steps to make it work:
- Replace
document.getQuerySelectorwithdocument.querySelectorAll(it'll fetch all<div>elements with the classnamequoteand return them) - Convert the fetched elements to a list with
Array.from(quoteList)(it'll ensure the list of quotes is iterable) - Move our previous code to get the quote text and author inside the loop and return the result (it'll extract the elements with the classname
textandauthorunder<div class="quote">for each quote)
Here's the code update:
import puppeteer from "puppeteer";
const getQuotes = async () => {
// Start a Puppeteer session with:
// - a visible browser (`headless: false` - easier to debug because you'll see the browser in action)
// - no default viewport (`defaultViewport: null` - website page will be in full width and height)
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open a new page
const page = await browser.newPage();
// On this new page:
// - open the "http://quotes.toscrape.com/" website
// - wait until the dom content is loaded (HTML is ready)
await page.goto("http://quotes.toscrape.com/", {
waitUntil: "domcontentloaded",
});
// Get page data
const quotes = await page.evaluate(() => {
// Fetch the first element with class "quote"
// Get the displayed text and returns it
const quoteList = document.querySelectorAll(".quote");
// Convert the quoteList to an iterable array
// For each quote fetch the text and author
return Array.from(quoteList).map((quote) => {
// Fetch the sub-elements from the previously fetched quote element
// Get the displayed text and return it (`.innerText`)
const text = quote.querySelector(".text").innerText;
const author = quote.querySelector(".author").innerText;
return { text, author };
});
});
// Display the quotes
console.log(quotes);
// Close the browser
await browser.close();
};
// Start the scraping
getQuotes();
As an end result, if we run our script one more time, we should have a list of quotes as an output. Each element of this list should have a text and an author property.
[
{
text: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
author: 'Albert Einstein'
},
{
text: '“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
author: 'J.K. Rowling'
},
{
text: '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
author: 'Albert Einstein'
},
{
text: '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”',
author: 'Jane Austen'
},
{
text: "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”",
author: 'Marilyn Monroe'
},
{
text: '“Try not to become a man of success. Rather become a man of value.”',
author: 'Albert Einstein'
},
{
text: '“It is better to be hated for what you are than to be loved for what you are not.”',
author: 'André Gide'
},
{
text: "“I have not failed. I've just found 10,000 ways that won't work.”",
author: 'Thomas A. Edison'
},
{
text: "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”",
author: 'Eleanor Roosevelt'
},
{
text: '“A day without sunshine is like, you know, night.”',
author: 'Steve Martin'
}
]
Good job! All the quotes from the first page are now scraped by our script. 👏
How to Move to the Next Page
Our script is now able to fetch all the quotes for one page. What would be interesting is clicking on the "Next page" at the page bottom and doing the same on the second page.
 "Next" button at the Quotes to Scrape page bottom
"Next" button at the Quotes to Scrape page bottom
Back to our browser inspect, and let's find how we can target this element using CSS selectors.
As we can notice, the next button is placed under an unordered list <ul> with a pager classname (<ul class="pager">). This list has an element <li> with a next classname (<li class="next">). Finally, there is a link anchor <a> that links to the second page (<a href="/page/2/">).
In CSS, if we want to target this specific link there are different ways to do that. We can do:
.next > a: but, it's risky because if there is an other element with.nextas a parent element containing a link, it'll click on it..pager > .next > a: safer, because we make sure the link should be inside the.pagerparent element under the.nextelement. There is a low risk of having this hierarchy more than once.
 An example of how the "Next" button is rendered in the HTML
An example of how the "Next" button is rendered in the HTML
To click this button, at the end of our script after the console.log(quotes);, you can add the following: await page.click(".pager > .next > a");.
Since we're now closing the browser page with await browser.close(); after all instructions are done, you need to comment on this instruction to see the second page opened in the scraper browser.
It's temporary and for testing purposes, but the end of our getQuotes function should look like this:
// Display the quotes
console.log(quotes);
// Click on the "Next page" button
await page.click(".pager > .next > a");
// Close the browser
// await browser.close();
After this, if you run our scraper again, after processing all instructions, your browser should stop on the second page:
 Quotes to Scrape second page loaded after clicking the "Next" button
Quotes to Scrape second page loaded after clicking the "Next" button
It’s Your Time! Here’s What You Can Do Next:
Congrats on reaching the end of this introduction to scraping with Puppeteer! 👏
Now it's your turn to improve the scraper and make it get more data from the Quotes to Scrape website. Here's a list of potential improvements you can make:
- Navigate between all pages using the "Next" button and fetch the quotes on all the pages.
- Fetch the quote's tags (each quote has a list of tags).
- Scrape the author's about page (by clicking on the author's name on each quote).
- Categorize the quotes by tags or authors (it's not 100% related to the scraping itself, but that can be a good improvement).
Feel free to be creative and do any other things you see fit 🚀
Scraper Code Is Available on GitHub
Check out the latest version of our scraper on GitHub! You're free to save, fork, or utilize it as you see fit.
=> First Puppeteer Scraper (example)
Successful Scraping Start: Thanks for reading the article!
I hope this article gave you a valuable introduction to web scraping using JavaScript and Puppeteer. Writing this was a pleasure, and I hope you found it informative and enjoyable.
Join me on Twitter for more content like this. I regularly share content to help you grow your web development skills and would love to have you join the conversation. Let's learn, grow, and inspire each other along the way!