
By Manthan Koolwal
Web scraping lets you collect data from web pages across the internet. It's also called web crawling or web data extraction.
PHP is a widely used back-end scripting language for creating dynamic websites and web applications. And you can implement a web scraper using plain PHP code.
But since we do not want to reinvent the wheel, we can leverage some readily available open-source PHP web scraping libraries to help us collect our data.
In this tutorial, we will be discussing the various tools and services you can use with PHP to scrap a web page. The tools we will discuss are Guzzle, Goutte, Simple HTML DOM, and the headless browser Symfony Panther.
Note: before you scrape a website, you should carefully read their Terms of Service to make sure they are OK with being scraped. Scraping data – even if it's publicly accessible – can potentially overload a website's servers. (Who knows – if you ask politely, they may even give you an API key so you don't have to scrape. 😉)
How to Set Up the Project
Before we begin, if you would like to follow along and try out the code, here are some prerequisites for your development environment:
- Ensure you have installed the latest version of PHP.
- Go to this link Composer to set up a composer that we will use to install the various PHP dependencies for the web scraping libraries.
- An editor of your choice.
Once you are done with all that, create a project directory and navigate into the directory:
mkdir php_scraper
cd php_scraper
Run the following two commands in your terminal to initialize the composer.json file:
composer init — require=”php >=7.4" — no-interaction
composer update
Let’s get started.
Web Scraping with PHP using Guzzle, XML, and XPath
Guzzle is a PHP HTTP client that lets you send HTTP requests quickly and easily. It has a simple interface for building query strings.
XML is a markup language that encodes documents so they're human-readable and machine-readable.
And XPath is a query language that navigates and selects XML nodes.
Let’s see how we can use these three tools together to scrape a website.
Start by installing Guzzle via composer by executing the following command in your terminal:
composer require guzzlehttp/guzzle
Once you've installed Guzzle, let’s create a new PHP file to which we will be adding the code. We will call it guzzle_requests.php.
For this demonstration, we will be scraping the Books to Scrape website. You should be able to follow the same steps we define here to scrape any website of your choice.
The Books to Scrape website looks like this:
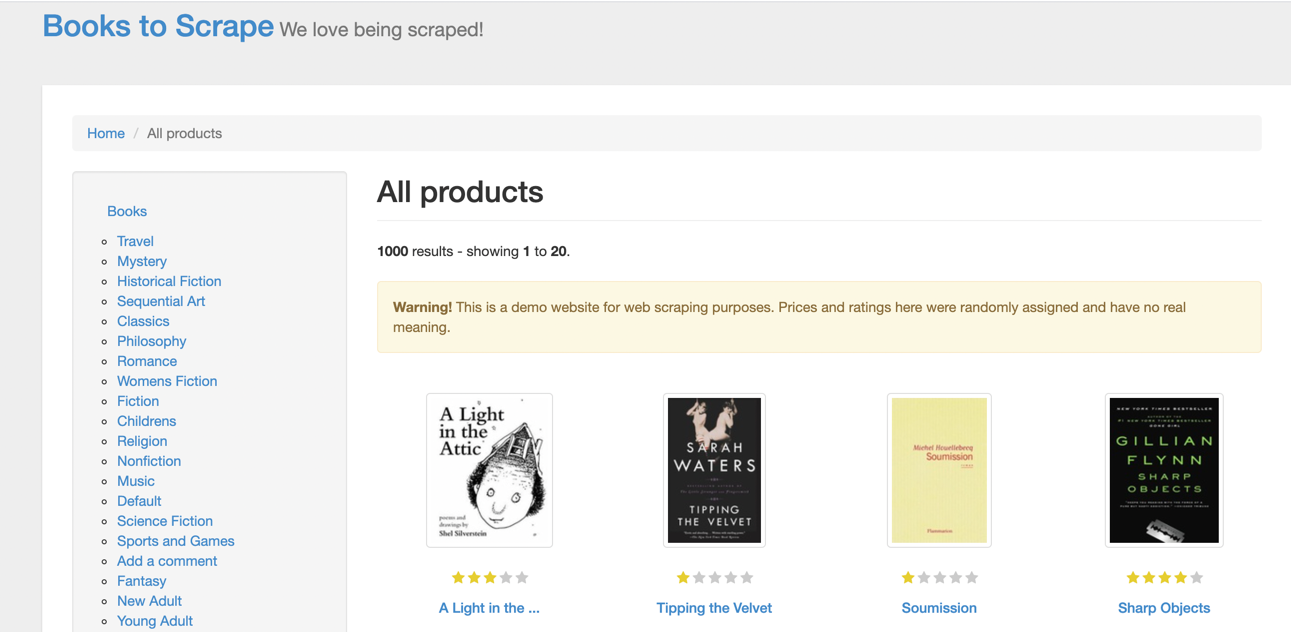
We want to extract the titles of the books and display them on the terminal.
The first step in scraping a website is understanding its HTML layout. In this case, you can view the HTML layout of this page by right-clicking on the page, just above the first product in the list, and selecting Inspect.
Here is a screenshot showing a snippet of the page source:

You can see that the list is contained inside the
What we want is the book title. It is inside the , which is in turn inside the
, which is inside the , which is finally inside the element.To initialize Guzzle, XML and Xpath, add the following code to the guzzle_requests.php file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \GuzzleHttp\Client();
$response = $httpClient->get('https://books.toscrape.com/');
$htmlString = (string) $response->getBody();
//add this line to suppress any warnings
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($htmlString);
$xpath = new DOMXPath($doc);
The above code snippet will load the web page into a string. We then parse the string using XML and assign it to the $xpath variable.
The next thing you want is to target the text content inside the tag. Add the following code to the file:
$titles = $xpath->evaluate('//ol[@class="row"]//li//article//h3/a');
$extractedTitles = [];
foreach ($titles as $title) {
$extractedTitles[] = $title->textContent.PHP_EOL;
echo $title->textContent.PHP_EOL;
}
In the code snippet above, //ol[@class=”row”] gets the whole list.
Each item in the list has an tag that we are targeting to extract the book’s actual title. We only have one
tag containing the , which makes it easier to target it directly.
We use the foreach loop to extract the text contents and echo them to the terminal.
At this step you may choose to do something with your extracted data, maybe assign the data to an array variable, write to file, or store it in a database.
You can execute the file using PHP on the terminal by running the command below. Remember, the highlighted part is how we named our file:
php guzzle_requests.php
This should display something like this:

That went well.
Now, what if we wanted to also get the price of the book?

The price happens to be inside
tag, inside a tag. As you can see there are more than one tag and more than one
tag.
To find the right target, we will use the CSS class selectors which, lucky for us, are unique for each tag. Here is the code snippet to also get the price tag and concatenate it to the title string:
$titles = $xpath->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $xpath->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $prices[$key]->textContent.PHP_EOL;
}
If you execute the code on your terminal, you should see something like this:

Your whole code should look like this:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \GuzzleHttp\Client();
$response = $httpClient->get('https://books.toscrape.com/');
$htmlString = (string) $response->getBody();
//add this line to suppress any warnings
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($htmlString);
$xpath = new DOMXPath($doc);
$titles = $xpath->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $xpath->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $prices[$key]->textContent.PHP_EOL;
}
Of course, this is a basic web scraper, and you can certainly make it better. Let’s move to the next library.
Web Scraping in PHP with Goutte
Goutte is another excellent HTTP client for PHP that's specifically made for web scraping. It was developed by the creator of the Symfony Framework and provides a nice API to scrape data from the HTML/XML responses of websites.
Below are some of the components it includes to make web crawling straightforward:
- BrowserKit Component to simulate the behavior of a web browser.
- CssSelector component for translating CSS queries into XPath queries.
- DomCrawler component brings the power of DOMDocument and XPath.
- Symfony HTTP Client is a fairly new component from the Symfony team.
Install Goutte via composer by executing the following command on your terminal:
composer require fabpot/goutte
Once you have installed the Goutte package, create a new PHP file for our code – let’s call it goutte_requests.php.
In this section we'll discuss what we did with the Guzzle library in the first section.
We will scrape book titles from the Books to Scrape website using Goutte. Then we'll see how you can add the prices into an array variable and use the variable within the code.
Add the following code inside the goutte_requests.php file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
$titles = $response->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $response->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
// we can store the prices into an array
$priceArray = [];
foreach ($prices as $key => $price) {
$priceArray[] = $price->textContent;
}
// we extract the titles and display to the terminal together with the prices
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $priceArray[$key] . PHP_EOL;
}
Execute the code by running the following command in the terminal:
php goutte_requests.php
Here is the output:

This is one way of web scraping with Goutte.
Let’s discuss another method using the CSS Selector component that comes with Goutte. The CSS selector is more straightforward than using XPath shown in the previous methods.
Create another PHP file, let’s call it goutte_css_requests.php. Add the following code to the file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
// get prices into an array
$prices = [];
$response->filter('.row li article div.product_price p.price_color')->each(function ($node) use (&$prices) {
$prices[] = $node->text();
});
// echo titles and prices
$priceIndex = 0;
$response->filter('.row li article h3 a')->each(function ($node) use ($prices, &$priceIndex) {
echo $node->text() . ' @ ' . $prices[$priceIndex] .PHP_EOL;
$priceIndex++;
});
As you can see, using the CSS Selector component results in cleaner and more readable code.
You may have noticed that we used the & operator. This ensures that we take the reference of the variable into the “each” loop, and not just the value of the variable. If the &$prices are modified within the loop, the actual value outside the loop is also modified.
You can read more on assignment by references from official PHP docs.
Execute the file in your terminal by running the command:
php goutte_css_requests.php
You should see an output similar to the one in the previous screenshots:

Our web scraper with PHP and Goutte is going well so far. Let’s go a little deeper and see if we can click on a link and navigate to a different page.
On our demo website, Books to Scrape, if you click on a title of a book, a page will load showing details of the book such as:
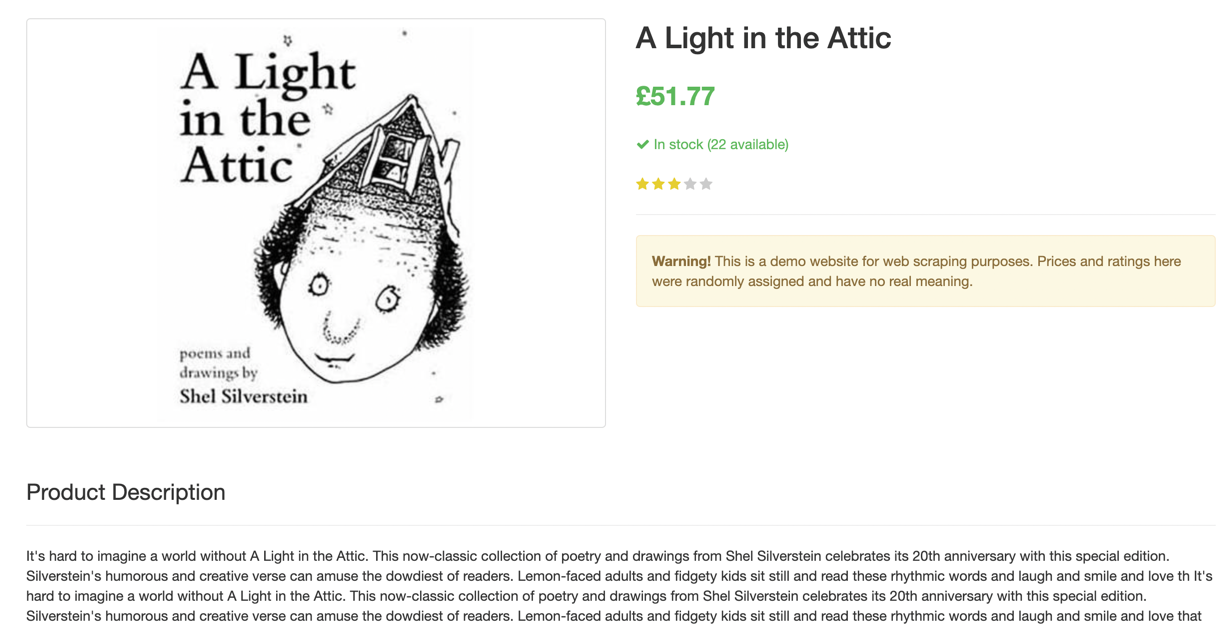
We want to see if you we click on a link from the books list, navigate to the book details page, and extract the description. Inspect the page to see what we will be targeting:

Our target flow will be from the
element, then , then the tag which only appears once, and finally the tag.
We have several
tags – the tag with the description is the fourth inside the parent. Since arrays start at 0, we will be getting the node at the 3rd index.
Now that we know what we are targeting, let’s write the code.
First, add the following composer package to help with HTML5 parsing:
composer require masterminds/html5
Next, modify the goutte_css_requests.php file as follows:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
// get prices into an array
$prices = [];
$response->filter('.row li article div.product_price p.price_color')
->each(function ($node) use (&$prices) {
$prices[] = $node->text();
});
// echo title, price, and description
$priceIndex = 0;
$response->filter('.row li article h3 a')
->each(function ($node) use ($prices, &$priceIndex, $httpClient) {
$title = $node->text();
$price = $prices[$priceIndex];
//getting the description
$description = $httpClient->click($node->link())
->filter('.content #content_inner article p')->eq(3)->text();
// display the result
echo "{$title} @ {$price} : {$description}\n\n";
$priceIndex++;
});
If you execute the file in your terminal, you should see a title, price, and description displayed:

Using the Goutte CSS Selector component and the option to click on a page, you can easily crawl an entire website with several pages and extract as much data as you need.
Web Scraping in PHP with Simple HTML DOM
Simple HTML DOM is another minimalistic PHP web scraping library that you can use to crawl a website. Let’s discuss how you can use this library to scrape a website. Just like in the previous examples, we will be scraping the Books to Scrape website.
Before you can install the package, modify your composer.json file and add the following lines of code just below the require:{} block to avoid getting the versioning error:
"minimum-stability": "dev",
"prefer-stable": true
Now, you can install the library with the following command:
composer require simplehtmldom/simplehtmldom
Once the library is installed, create a new PHP file called simplehtmldom_requests.php.
We have already discussed the layout of the web page we are scraping in the previous sections. So, we will just go straight to the code. Add the following code to the simplehtmldom_requests.php file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \simplehtmldom\HtmlWeb();
$response = $httpClient->load('https://books.toscrape.com/');
// echo the title
echo $response->find('title', 0)->plaintext . PHP_EOL . PHP_EOL;
// get the prices into an array
$prices = [];
foreach ($response->find('.row li article div.product_price p.price_color') as $price) {
$prices[] = $price->plaintext;
}
// echo titles and prices
foreach ($response->find('.row li article h3 a') as $key => $title) {
echo "{$title->plaintext} @ {$prices[$key]} \n";
}
If you execute the code in your terminal, it should display the results:
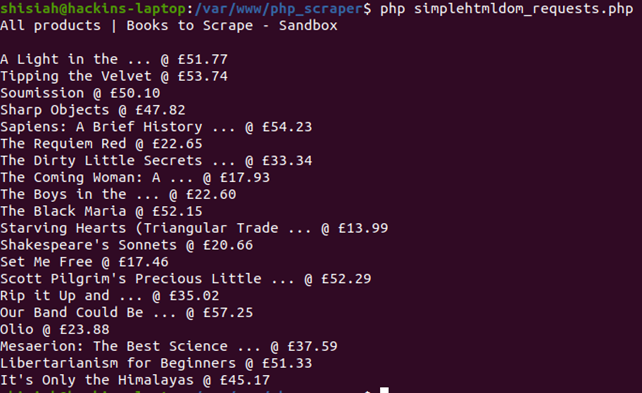
You can find more methods to crawl a web page using the Simple HTML DOM library from the official API docs.
Web Scraping in PHP with a Headless Browser (Symfony Panther)
A headless browser is a browser without a graphical user interface. Headless browsers allow you to use your terminal to load a web page in an environment similar to a web browser. This allows you to write code to control the browsing as we have just done in the previous steps.
So why is this necessary?
In modern web development, most developers use JavaScript web frameworks. These frameworks generate the HTML code inside the browsers. In other cases, AJAX dynamically loads the content.
In the previous examples, we used a static HTML page, so the output was consistent.
In dynamic cases, where you use JavaScript and AJAX to generate the HTML, the output of the DOM tree may differ greatly. This would cause our scrapers to fail. Headless browsers come into the picture to handle such issues in modern websites.
The Symfony Panther PHP library works well with headless browsers. You can use the library to scrape websites and run tests using real browsers.
In addition, it provides the same methods as the Goutte library, so you can use it instead of Goutte.
Unlike the previous web scraping libraries we've discussed in this tutorial, Panther can do the following:
- Execute JavaScript code on web pages
- Supports remote browser testing
- Supports asynchronous loading of elements by waiting for other elements to load before executing a line of code
- Supports all implementations of Chrome of Firefox
- Can take screenshots
- Allows running your custom JS code or XPath queries within the context of the loaded page.
We have already been doing a lot of scraping, so let’s try something different. We will be loading an HTML page and taking a screenshot of the page.
Install Symfony Panther with the following command:
composer require symfony/panther
Create a new php file, let’s call it panther_requests.php. Add the following code to the file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = \Symfony\Component\Panther\Client::createChromeClient();
// for a Firefox client use the line below instead
//$httpClient = \Symfony\Component\Panther\Client::createFirefoxClient();
// get response
$response = $httpClient->get('https://books.toscrape.com/');
// take screenshot and store in current directory
$response->takeScreenshot($saveAs = 'books_scrape_homepage.jpg');
// let's display some book titles
$response->getCrawler()->filter('.row li article h3 a')
->each(function ($node) {
echo $node->text() . PHP_EOL;
});
For this code to run on your system, you must install the drivers for Chrome or Firefox, depending on which client you used in your code.
Fortunately, Composer can automatically do this for you. Execute the following command in your terminal to install and detect the drivers:
composer require - dev dbrekelmans/bdi && vendor/bin/bdi detect drivers
Now you can execute the PHP file in your terminal and it will take a screenshot of the webpage and store it in the current directory. It will then display a list of titles from the website.

Conclusion
In this tutorial, we discussed the various PHP open source libraries you can use to scrape a website.
If you followed along with the tutorial, you should've been able to create a basic scraper to crawl a page or two.
While this was an introductory article, we covered most methods you can use with the libraries. You may choose to build on this knowledge and create complex web scrapers that can crawl thousands of pages. The code for this tutorial is available from this GitHub repository.
Feel free to get in touch if you have any questions.
You can check out some other articles on web scraping with Nodejs and web scraping with Python if you're interested.
php guzzle_requests.php
tag and more than one
To find the right target, we will use the CSS class selectors which, lucky for us, are unique for each tag. Here is the code snippet to also get the price tag and concatenate it to the title string:
$titles = $xpath->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $xpath->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $prices[$key]->textContent.PHP_EOL;
}
If you execute the code on your terminal, you should see something like this:
Your whole code should look like this:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \GuzzleHttp\Client();
$response = $httpClient->get('https://books.toscrape.com/');
$htmlString = (string) $response->getBody();
//add this line to suppress any warnings
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($htmlString);
$xpath = new DOMXPath($doc);
$titles = $xpath->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $xpath->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $prices[$key]->textContent.PHP_EOL;
}
Of course, this is a basic web scraper, and you can certainly make it better. Let’s move to the next library.
Web Scraping in PHP with Goutte
Goutte is another excellent HTTP client for PHP that's specifically made for web scraping. It was developed by the creator of the Symfony Framework and provides a nice API to scrape data from the HTML/XML responses of websites.
Below are some of the components it includes to make web crawling straightforward:
- BrowserKit Component to simulate the behavior of a web browser.
- CssSelector component for translating CSS queries into XPath queries.
- DomCrawler component brings the power of DOMDocument and XPath.
- Symfony HTTP Client is a fairly new component from the Symfony team.
Install Goutte via composer by executing the following command on your terminal:
composer require fabpot/goutte
Once you have installed the Goutte package, create a new PHP file for our code – let’s call it goutte_requests.php.
In this section we'll discuss what we did with the Guzzle library in the first section.
We will scrape book titles from the Books to Scrape website using Goutte. Then we'll see how you can add the prices into an array variable and use the variable within the code.
Add the following code inside the goutte_requests.php file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
$titles = $response->evaluate('//ol[@class="row"]//li//article//h3/a');
$prices = $response->evaluate('//ol[@class="row"]//li//article//div[@class="product_price"]//p[@class="price_color"]');
// we can store the prices into an array
$priceArray = [];
foreach ($prices as $key => $price) {
$priceArray[] = $price->textContent;
}
// we extract the titles and display to the terminal together with the prices
foreach ($titles as $key => $title) {
echo $title->textContent . ' @ '. $priceArray[$key] . PHP_EOL;
}
Execute the code by running the following command in the terminal:
php goutte_requests.php
Here is the output:
This is one way of web scraping with Goutte.
Let’s discuss another method using the CSS Selector component that comes with Goutte. The CSS selector is more straightforward than using XPath shown in the previous methods.
Create another PHP file, let’s call it goutte_css_requests.php. Add the following code to the file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
// get prices into an array
$prices = [];
$response->filter('.row li article div.product_price p.price_color')->each(function ($node) use (&$prices) {
$prices[] = $node->text();
});
// echo titles and prices
$priceIndex = 0;
$response->filter('.row li article h3 a')->each(function ($node) use ($prices, &$priceIndex) {
echo $node->text() . ' @ ' . $prices[$priceIndex] .PHP_EOL;
$priceIndex++;
});
As you can see, using the CSS Selector component results in cleaner and more readable code.
You may have noticed that we used the & operator. This ensures that we take the reference of the variable into the “each” loop, and not just the value of the variable. If the &$prices are modified within the loop, the actual value outside the loop is also modified.
You can read more on assignment by references from official PHP docs.
Execute the file in your terminal by running the command:
php goutte_css_requests.php
You should see an output similar to the one in the previous screenshots:
Our web scraper with PHP and Goutte is going well so far. Let’s go a little deeper and see if we can click on a link and navigate to a different page.
On our demo website, Books to Scrape, if you click on a title of a book, a page will load showing details of the book such as:
We want to see if you we click on a link from the books list, navigate to the book details page, and extract the description. Inspect the page to see what we will be targeting:
Our target flow will be from the
element, then , then the tag which only appears once, and finally the tag.We have several
tags – the tag with the description is the fourth inside the parent. Since arrays start at 0, we will be getting the node at the 3rd index.Now that we know what we are targeting, let’s write the code.
First, add the following composer package to help with HTML5 parsing:
composer require masterminds/html5
Next, modify the goutte_css_requests.php file as follows:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \Goutte\Client();
$response = $httpClient->request('GET', 'https://books.toscrape.com/');
// get prices into an array
$prices = [];
$response->filter('.row li article div.product_price p.price_color')
->each(function ($node) use (&$prices) {
$prices[] = $node->text();
});
// echo title, price, and description
$priceIndex = 0;
$response->filter('.row li article h3 a')
->each(function ($node) use ($prices, &$priceIndex, $httpClient) {
$title = $node->text();
$price = $prices[$priceIndex];
//getting the description
$description = $httpClient->click($node->link())
->filter('.content #content_inner article p')->eq(3)->text();
// display the result
echo "{$title} @ {$price} : {$description}\n\n";
$priceIndex++;
});
If you execute the file in your terminal, you should see a title, price, and description displayed:
Using the Goutte CSS Selector component and the option to click on a page, you can easily crawl an entire website with several pages and extract as much data as you need.
Web Scraping in PHP with Simple HTML DOM
Simple HTML DOM is another minimalistic PHP web scraping library that you can use to crawl a website. Let’s discuss how you can use this library to scrape a website. Just like in the previous examples, we will be scraping the Books to Scrape website.
Before you can install the package, modify your composer.json file and add the following lines of code just below the require:{} block to avoid getting the versioning error:
"minimum-stability": "dev",
"prefer-stable": true
Now, you can install the library with the following command:
composer require simplehtmldom/simplehtmldom
Once the library is installed, create a new PHP file called simplehtmldom_requests.php.
We have already discussed the layout of the web page we are scraping in the previous sections. So, we will just go straight to the code. Add the following code to the simplehtmldom_requests.php file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = new \simplehtmldom\HtmlWeb();
$response = $httpClient->load('https://books.toscrape.com/');
// echo the title
echo $response->find('title', 0)->plaintext . PHP_EOL . PHP_EOL;
// get the prices into an array
$prices = [];
foreach ($response->find('.row li article div.product_price p.price_color') as $price) {
$prices[] = $price->plaintext;
}
// echo titles and prices
foreach ($response->find('.row li article h3 a') as $key => $title) {
echo "{$title->plaintext} @ {$prices[$key]} \n";
}
If you execute the code in your terminal, it should display the results:
You can find more methods to crawl a web page using the Simple HTML DOM library from the official API docs.
Web Scraping in PHP with a Headless Browser (Symfony Panther)
A headless browser is a browser without a graphical user interface. Headless browsers allow you to use your terminal to load a web page in an environment similar to a web browser. This allows you to write code to control the browsing as we have just done in the previous steps.
So why is this necessary?
In modern web development, most developers use JavaScript web frameworks. These frameworks generate the HTML code inside the browsers. In other cases, AJAX dynamically loads the content.
In the previous examples, we used a static HTML page, so the output was consistent.
In dynamic cases, where you use JavaScript and AJAX to generate the HTML, the output of the DOM tree may differ greatly. This would cause our scrapers to fail. Headless browsers come into the picture to handle such issues in modern websites.
The Symfony Panther PHP library works well with headless browsers. You can use the library to scrape websites and run tests using real browsers.
In addition, it provides the same methods as the Goutte library, so you can use it instead of Goutte.
Unlike the previous web scraping libraries we've discussed in this tutorial, Panther can do the following:
- Execute JavaScript code on web pages
- Supports remote browser testing
- Supports asynchronous loading of elements by waiting for other elements to load before executing a line of code
- Supports all implementations of Chrome of Firefox
- Can take screenshots
- Allows running your custom JS code or XPath queries within the context of the loaded page.
We have already been doing a lot of scraping, so let’s try something different. We will be loading an HTML page and taking a screenshot of the page.
Install Symfony Panther with the following command:
composer require symfony/panther
Create a new php file, let’s call it panther_requests.php. Add the following code to the file:
<?php
# scraping books to scrape: https://books.toscrape.com/
require 'vendor/autoload.php';
$httpClient = \Symfony\Component\Panther\Client::createChromeClient();
// for a Firefox client use the line below instead
//$httpClient = \Symfony\Component\Panther\Client::createFirefoxClient();
// get response
$response = $httpClient->get('https://books.toscrape.com/');
// take screenshot and store in current directory
$response->takeScreenshot($saveAs = 'books_scrape_homepage.jpg');
// let's display some book titles
$response->getCrawler()->filter('.row li article h3 a')
->each(function ($node) {
echo $node->text() . PHP_EOL;
});
For this code to run on your system, you must install the drivers for Chrome or Firefox, depending on which client you used in your code.
Fortunately, Composer can automatically do this for you. Execute the following command in your terminal to install and detect the drivers:
composer require - dev dbrekelmans/bdi && vendor/bin/bdi detect drivers
Now you can execute the PHP file in your terminal and it will take a screenshot of the webpage and store it in the current directory. It will then display a list of titles from the website.
Conclusion
In this tutorial, we discussed the various PHP open source libraries you can use to scrape a website.
If you followed along with the tutorial, you should've been able to create a basic scraper to crawl a page or two.
While this was an introductory article, we covered most methods you can use with the libraries. You may choose to build on this knowledge and create complex web scrapers that can crawl thousands of pages. The code for this tutorial is available from this GitHub repository.
Feel free to get in touch if you have any questions.
You can check out some other articles on web scraping with Nodejs and web scraping with Python if you're interested.