
By Sergei Bachinin
In this article, we'll thoroughly explore base64 encoding. You'll learn how it came into being and why it's still so prevalent in modern systems.
Here's what we'll cover:
- What is base64?
- Why use base64?
- When to use base64
- A Case of SMTP
- Are These Limitations Still Relevant Today?
- How base64 Helps with These Limitations
- Why Only 64 Characters?
- Do I Have to Use base64 with HTTP/1.1?
- Why is base64 Used for Data URLs?
- Conclusion
What is base64?
Base64 is a way of transforming any data into a gibberish of digits and letters. Today it's widely used and taken for granted. Most of the time you use it because there is no choice: in many situations, only such text-like gibberish is considered valid.
At the same time, base64 is a costly instrument. It makes data about 33% larger in terms of memory usage. So base64 is one of these little things that make software slow. That's why you should use it only when it's absolutely necessary.
Again, typically you don't have a choice. But sometimes you do, and that's why it can be useful to understand how it works and what problems it is meant to solve.
This article is aimed at those who've already encountered base64 in their programming practice and may be wondering what on earth it is. You'll likely get more out of this guide if you have at least basic knowledge of data types and some understanding of how computer memory is organized at a binary level (bits, bytes and all that).
The encoding algorithm of base64 is straightforward. It takes as an input one binary sequence and ouputs another binary sequence. It doesn't care what the original bytes stood for – be it an image or a PDF or whatever. It just goes through the original binary stuff, splits it into chunks of 6 bits, and converts every chunk into a safe textual character (or, strictly speaking, a binary sequence that represents such a character). A "safe" character refers to one from a very limited set, which we'll discuss more later.
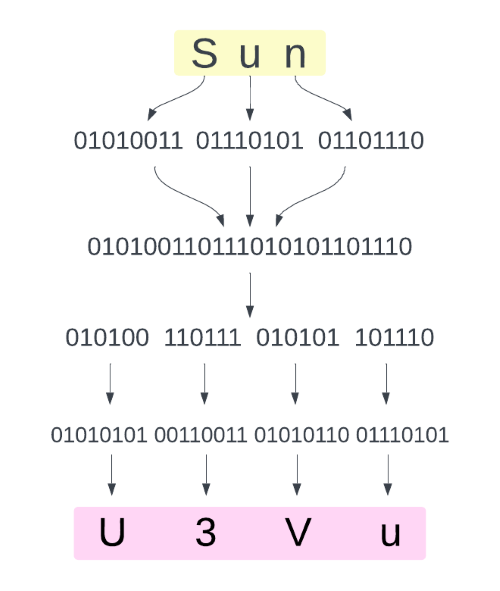 This image shows approximately how the text "Sun" is encoded to base64
This image shows approximately how the text "Sun" is encoded to base64
Then at some point you have to decode this pseudo-text back into an original data – because base64 gibberish in itself is useless. Decoding performs similar binary operations but in reverse. The restored data is guaranteed to be exactly the same as before encoding.
I won't discuss the encoding/decoding algorithm in more depth here. Wikipedia explains it in exhaustive detail if you want to read more.
In practice, you (as a developer) will almost never deal with anything in binary itself when encoding your data. Instead, you'll use convenient wrappers that are available in almost any language, such as the btoa() and atob() functions in JavaScript. You can read more about them here.
Why Use base64?
What problems is base64 meant to solve? We have 3 main theories here:
- Base64 is used because some systems are restricted to ASCII characters but are actually used for all kinds of data. Base64 can "camouflage" this data as ASCII and thus help this data pass validation.
- Because some older systems think that data consists of 7-bit chunks (bytes), whereas modern ones use 8-bit bytes. This may lead to misunderstandings between systems. And base64 presumably can help with this – but it's not so obvious how.
- Because some characters may have special meaning and this will differ from system to system. Base64 tackles this by using only the most "purely textual" characters from the ASCII set.
Many experts on base64 advocate one theory and turn down all other theories. It may seem we should be able to (or that we need to) pick the right one from the list – but actually they are all correct. Well, the "7-bit problem" is much less of a problem today but the other two are still relevant and base64 addresses them both.
When to Use base64
When do you need to present data as base64 gibberish? In a great many situations, of course. But let's understand the main principle.
The official spec (RFC4648) says that base64 "is used to store or transfer data in environments that, perhaps for legacy reasons, are restricted to ASCII data".
So you need base64 when:
- Incompatible data is transmitted through the network. First of all it's a problem of emails – for example, encoding is necessary when you need to attach an image to a textual message. This was the reason why base64 was first introduced.
- Incompatible data is stored in files or elsewhere. Often you need to embed non-textual data in a textual file like JSON, XML or HTML. Or to store something fancy in a brower cookie (and cookies must be only text).
The official spec continues that base64 also:
- "makes it possible to manipulate objects with text editors". Apparently it means "rich text editors" such as Microsoft Word where you can combine text with images and other things. Do such programs use base64 for embedded content? That's possible, but let's leave it to more persistent researchers.
A Case of SMTP
SMTP is an age-old email protocol still prevalent today and used by Gmail, Outlook, and others. It defines how email messages must be transmitted between servers. Original SMTP rules were really strict, and by the end of 80s they were already a great nuisance.
First of all, SMTP allowed only plain text in the English language (which consists of only 128 characters known as ASCII). So some workarounds were necessary to send both non-English text and non-textual attachments.
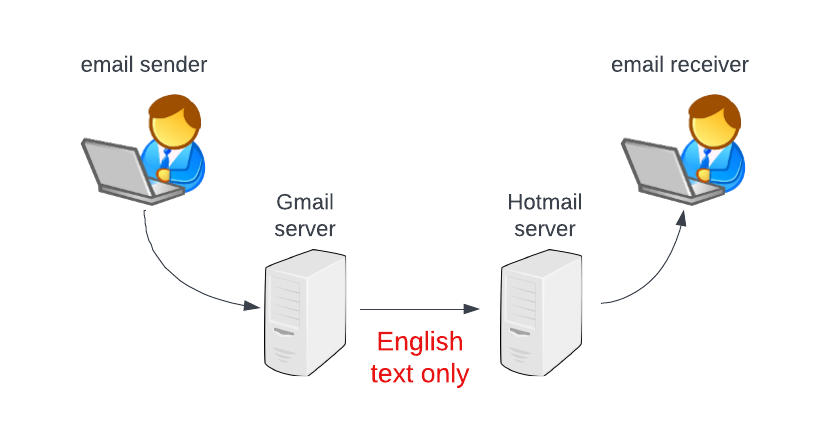 Diagram showing email going between two people via servers using English text only
Diagram showing email going between two people via servers using English text only
Base64 solved this problem by converting all data to "safe English text". This conversion is necessary only for the time being, and when the danger is over, data is converted back to normal.
This is basically a very ugly practice that is somewhat similar to contraband. Data is obfuscated (well, really) in order to cheat a system that doesn't allow this kind of data.
And by the way, the restrictions of SMTP were meant for safety in the first place. But it was long ago and today nobody needs this safety anymore. Instead everyone needs an unobtrusive channel to transport anything whatsoever. So the old rules act like a pesky bureaucracy. But that's what legacy systems are and you have to live with them.
Are These Limitations Still Relevant Today?
Yes, despite all the extensions and tricks.
Many restrictions of SMTP are relaxed thanks to various extensions. For instance, the "8BIT MIME" extension allows you to send email messages in 8-bit bytes and in characters other than ASCII. So in theory, today you can send a letter with an attachment without encoding.
But in practice it's still impossible to ignore the old restrictions. Because there are outdated email servers which didn't adopt new extensions. And you have to be able to communicate with them even if your own email server supports all the modern stuff.
Before sending a message to a certain email server, you first ask what kind of SMTP rules it supports. Does it implement an 8BIT MIME extension? If not, you will need to convert your message to the older format.
How base64 Helps with These Limitations
It's self-evident that base64 must be a solution to an "ASCII only" problem because it transforms everything to ASCII characters. But it becomes less obvious when you combine it with the "7 bits" problem. Because no matter what kind of characters you use, they must be somehow transmittable by both 7-bit and 8-bit channels, depending on the situation.
Experts usually say something like:
"Base64 transforms the binary sequence 01001101 01100001 01101110 (whatever it means) into text "TWFu".
Such statements can lead you to think that something binary becomes non-binary. In fact, all ASCII characters produced by base64 are ultimately bits and bytes, just like the original data. (But of course the amount and order of bits change).
Here is a bash command to get a binary representation of a string:
echo -n "TWFu" | xxd -b
It will tell you that "TWFu" is actually "01010100 01010111 01000110 01110101". But if every character is 8 bits long, a 7-bit channel may not recognize this TWFu as text. Apparently some additional binary juggling must take place to make it work for all channels.
Fortunately, with ASCII characters this binary juggling is easy. Because to store an ASCII character in memory you actually need only 7 bits. They can be fattened to 8 bits only if you need a conventional "octet". This is done simply by adding a "0" bit in front of the original seven. For example, "T" can be stored as both 1010100 and 01010100.
So, conversion between 7-bit and 8-bit ASCII characters is a matter of adding/removing the leftmost "0" bit. Apparently email servers have to perform this kind of stuff when talking to each other.
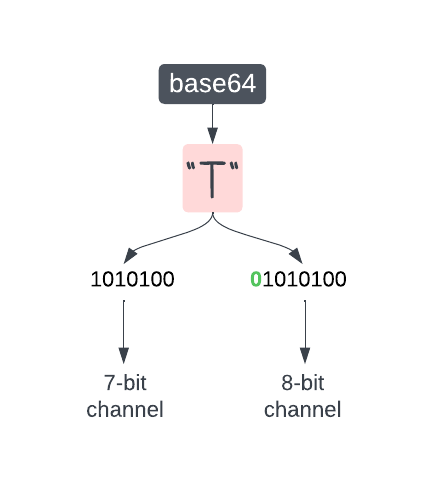 This image shows how a character "T" produced by base64 can be consumed by both 7- and 8-bit channels
This image shows how a character "T" produced by base64 can be consumed by both 7- and 8-bit channels
So let's keep in mind that base64 in itself doesn't solve the "7 bit" problem. It just produces ASCII characters and this allows for a brisk conversion between 7 and 8 bits. But this conversion is the responsibility of a wider system, such as MIME (extension of SMTP).
Memory cost depends on byte length
By the way, if you use only 7 bits per character, then base64 must be less wasteful in terms of memory usage.
The main theory is that base64 causes a memory overhead of 33% (or 37% or whatever). But it seems to be correct only for an 8-bit scenario.
Because, as I previously explained, base64 converts every 6-bit chunk of original data into a single ASCII character. If such a character is 8 bits long, it means that you are wasting 2 bits per every original chunk which is about 33%, just as promised by the experts. But with 7-bit characters this loss must be about half the size.
Why Only 64 Characters?
Base64 would be overkill if it was made only to bypass the ASCII restriction.
ASCII is 128 characters long, and if you could use all of them, the encoding algorithm would be more memory-efficient. It's cumbersome to explain but, in short, with a 128-long alphabet, a single character could represent 7 (instead of only 6) bits of original data.
But the authors of base64 decided to use only half of the ASCII characters, and surely they had a very good reason for that.
Characters can be wrong (unsafe) for at least two reasons:
- They can be invalid (forbidden by a system, like SMTP forbids anything beyond ASCII)
- They can be valid but mistakenly recognized as a special character
In ASCII there are 30+ "control characters". They are not printable and are meant to cause some other effects. For example: "line feed", "backspace", "delete", "escape". Many of these commands are a legacy of some prehistoric devices like teleprinters.
 Table showing 34 non-printable characters from ASCII set
Table showing 34 non-printable characters from ASCII set
Apparently you have to exclude all non-printable characters from the encoding alphabet. So you are left with some 90+ printable ones. But printable doesn't mean safe and reliable. They can also have special meaning in different systems. And a bunch of them have special meaning in SMTP, for example "@", "<", and ">". They will surely produce "some other effects" and it won't make you happy.
So it ended up with 64 chars – first of all, because 64 is easier to deal with algorithmically. And it looks like a really safe alphabet that can be used in a wide range of systems, not only SMTP.
Unfortunately it's not completely safe. There are only 62 characters that are guaranteed to have no special meaning in all systems. They are digits, English small letters, and English capital letters. You need 2 more characters for base64. And their choice differs from system to system.
The most popular candidates are "+" and "/" but still in some situations they will break stuff. For example, they have special meaning in URLs. That's why we have a "base64url" variant where the last two characters are "_" and "-".
Base64 does not fix the problem of "ambiguous" special characters
Here I'd like to briefly explain one misconception that often pops up in various discussions about base64.
Some special characters are treated differently by different systems. The most notorious of them are "line feed" and "carriage return". Both are concerned with line breaks. But different systems have different opinions on how to combine these two chars to produce an actual line break.
There is a widespread belief that base64 somehow helps to reconcile these differences.
But base64 has nothing to do with how data is interpreted – for example, how text is displayed on a screen. Because in order to display something you first need to decode it from base64 back to the original form. Decoded data will be exactly the same as it was before encoding. It will be the same sequence of bits with the same ambiguous characters as before.
So, again, base64 can only conceal special chars for the time being. It doesn't magically sanitize data from dangerous chars.
Do I Have to Use base64 with HTTP/1.1?
HTTP/1.1 is a text-based protocol. So you may ask whether non-textual data has to be encoded to transmit stuff over the Internet.
(Also, let's call it just HTTP. Keep in mind that HTTP/2 and /3 are binary protocols, so they are not in question).
HTTP actually allows all kinds of data in the body of a message. The body is not restricted to textual characters. So, for instance, an image can be sent in its original form, without jumbling its bits and bytes.
What is really "text-based" about HTTP is headers. Basically they are restricted to ASCII (this is not exactly true, but it's a good practice to use only ASCII).
Today HTTP headers are used in many different ways – and sometimes they have to carry non-ASCII stuff too.
For example, a basic HTTP authentication scheme suggests that you send username and password as part of the "Authentication" header. Username and password can contain a lot of incompatible stuff, so you have to encode them to safe textual chars. Base64 is recommended to use in such cases. For this reason some developers think that base64 is a kind of encryption (data protection) which is not true.
Why is base64 Used for Data URLs? Is There a More Efficient Encoding for This?
Data URLs are probably the most well-known use of base64 today. It's a way to inline various assets like images (not links to them but their actual code) into HTML or CSS files.
Note that Data URLs have nothing to do with the transmission of data. Base64 is used here not because HTTP protocol forbids any binary sequences. When you send HTML or CSS file over network, HTTP doesn't care what's inside these files. But HTML and CSS files have to be only text to be properly interpreted (displayed) by text editors and browsers.
It makes sense, but still it's a pity – because, again, base64 is expensive. This notorious 33% or 37% of memory overhead is especially annoying with Data URLs. In most cases it defeats their purpose entirely.
The purpose is to improve performance of course. You get an image without an extra HTTP request and thus save some milliseconds. But this performance gain is small and easily nullified by the extra bytes created by base64.
So why base64 is used for data URLs at all? Could we use some less wasteful encoding for that (that is, encoding that uses a wider alphabet and thus outputs shorter strings of characters)?
At present it's very unlikely, because browsers allow only URL-safe characters in Data URLs. And there aren't too many URL-safe characters – just a tiny bit more than 64. Why are we restricted to URL-safe characters? Because we insert the encoded data into places where browsers expect a URL.
In theory, browsers could be smarter and relax this limitation when necessary. So let's ask a broader question next.
Is there a better encoding for non-textual data in HTML?
Technically, Data URLs are not the only way to embed non-textual data in HTML files.
You can build your homemade solutions where non-textual data is inserted elsewhere in HTML markup (attributes, innerText, or whatever). In such cases, you are not restricted to a URL-safe alphabet. So in theory, you can use any characters that are allowed in HTML.
Most HTML files use the UTF-8 character set. It contains all Unicode characters, and it's more than 1 million. So it must be possible to create some baseNNN encoding where at least 256 Unicode characters will be used. Such encoding would have no (or almost no) memory overhead.
In practice, everything is much more complicated.
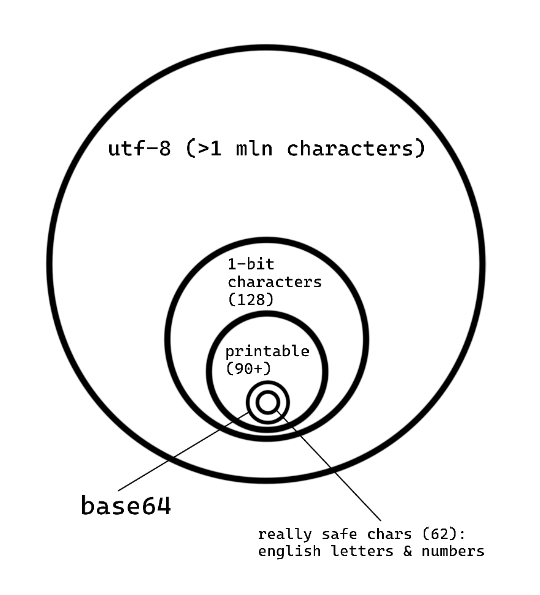 Diagram showing how few characters from UTF-8 are "really safe" and usable for a hypothetical baseNNN encoding
Diagram showing how few characters from UTF-8 are "really safe" and usable for a hypothetical baseNNN encoding
Why not encode stuff with Chinese characters, for example? Because they are too heavy. They take 3 or even 4 bytes of memory. That's how UTF-8 encoding works – it uses different number of bytes for different characters. And we are interested only in those that take 1 byte.
(You may consider using multi-byte characters for our baseNNN encoding, but let's not go into that. You need only 1-byte ones – let's take it as an axiom.)
How many 1-byte characters are there in UTF-8? Only 128, and it's a good old ASCII range. Can you take all of them? No, because, again, you need only printable characters. You really need to see them in text editors and dev tools and elsewhere.
Then, just like in case of SMTP, you have to exclude a bunch of visible characters because they have special meaning in HTML. For example, double quotes (") won't do because it can prematurely terminate the Data URL string. This won't work:
<img src="data:image/png;base64,iVBOR"w0KAA" />
So a possible alphabet again shrinks to 80-90 characters. This, in theory, allows you to create another encoding that will use a bit less memory than base64.
Such encodings actually exist, for example base85 made in Adobe. It is more memory-efficient because it encodes 4 bytes of original data into 5 characters. But base85 is also much slower to compute, so its overall benefits are tiny, if any. And by the way it's not intended for web development and contains characters that can break things in HTML and CSS. (Though it must be possible to build a similar but web-friendly algorithm by swapping some characters.)
Can we find a better baseNNN for other kinds of text files (JSON, XML, and so on)? It seems unlikely, because these formats are predominantly UTF-8-encoded and this means roughly the same limitations as in case of HTML. Only the amount of special printable characters may differ (it's very small in JSON for example) but it's not a big deal.
Conclusion
Base64 was first introduced as a way to bypass a number of archaic restrictions imposed on email messages by the SMTP protocol.
Base64 allowed us to camouflage any data as text in order to pass validation when transmitted between email servers. It also ensured that this pseudo-text contained only safe characters, that is 1) only printable ones and 2) only those that have no special meaning in SMTP and (hopefully) in most other systems.
The final alphabet happened to be really narrow, and it allowed us to use base64 practically everywhere (but in slightly different variants). It helps in many cases where you have to mix textual and non-textual data.
Modern systems also use base64 despite its significant memory cost. At first glance this practice looks strange, because modern systems don't have these age-old restrictions that SMTP had. But it turns out that in most cases you still have very few cheap and non-special characters, and potential alternatives to base64 offer very small benefits.