
By David Brailovsky
Visualizing which part of an image a neural network uses to recognize traffic lights

In my last post I described how I trained a ConvNet (Convolutional Neural Network) to recognize traffic lights in dash-cam images. The best performing single network achieved an impressive accuracy of >94%.
While ConvNets are very good at learning to classify images, they are also somewhat of a black box. It’s hard to tell what they’re doing once they’re trained. Since I never explicitly “told” the network to focus on traffic lights, it’s possible that it’s using some other visual cues in the images to predict the correct class. Maybe it’s looking for static cars to predict a red light? ?
In this post I describe a very simple and useful method for visualizing what part of an image the network uses for its prediction. The approach involves occluding parts of the image and seeing how that changes the network’s prediction. This approach has been described in “Visualizing and Understanding Convolutional Networks”.
Self-driving cars today use much more sophisticated methods for detecting objects in a scene, as well as many more sensors as inputs. The ConvNet we examine throughout the post should be seen as a simplified version of what self-driving cars actually use. Nonetheless, the visualization method described in this post can be useful and adapted for different kinds of neural network applications.
You can download a notebook file with the code I used from here.
Example #1
I started with the following image which has a red traffic light:

The network predicts this image has a red traffic light with 99.99% probability. Next I generated many versions of this image with a grey square patch in different positions. More specifically, a 64 x 64 sliding square with a step size of 16 pixels.

I ran each image through the network and recorded the probability it predicted for the class “red”. Below you can see a plot of a heat-map of those recorded probabilities.
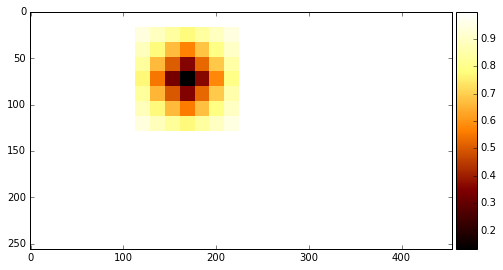
The color represents the probability of the class “red” when there was a square patch covering that position. Darker color means lower probability. There’s a smoothing effect because I averaged the probabilities each pixel got for all the patches that covered it.
Then I plotted the heat-map on top of the original image:

Very cool! ? The lowest probability is exactly when covering the traffic light. I then repeated this process with a smaller patch size of 16x16:

Exactly on the traffic light! ?
Example #2
I kept examining more images and came across this interesting example:

The ConvNet predicted the class “green” with 99.99% probability for this image. I generated another heat-map by sliding a patch of size 32x32 and a step size of 16 pixels:

Hmm… something’s not right ?. The lowest probability for “green” that any patched image got was 99.909% which is still very high. The image with the lowest probability was:

That actually looks fine, it covers the traffic light perfectly. So why was the network still predicting “green” with a high probability? Could be because of the second green traffic light in the image. I repeated the sliding patch process on the patched image above and plotted the heat-map:

Much better! ? After hiding the second traffic light, the probability for “green” dropped close to zero, 0.25% to be exact.
Looking at mistakes
Next I wanted to see if I could learn anything interesting by using this technique to understand some the network’s misclassifications. Many of the mistakes were caused by having two traffic lights in the scene, one green and one red. It was pretty obvious that the other traffic light is the part of the image that caused the mistake in those cases.
Another type of mistake was when the network predicted there’s no traffic light in the scene when there actually was. Unfortunately this technique was not very useful for understanding the reason the network got it wrong since there was no specific part of the image it focused on.
The last kind of mistake I looked at was when the network predicted a traffic light when there actually wasn’t one. See the example below:

And with the heat-map plotted on top:

Looks like the network confused the parking sign light for a traffic light. Interesting to see that it was just the right parking sign and not the left one.
Conclusion
This method is very simple yet effective to gain insights into what a ConvNet is focusing on in an image. Unfortunately it doesn’t tell us why it’s focusing on that part.
I also experimented a little with generating a saliency map as described in “Deep Inside Convolutional Networks”, but didn’t get any visually pleasing results.
If you know of any other interesting ways to understand what ConvNets are doing, please write a comment below ?
If you enjoyed reading this post, please tap ♥ below!