
By Ugo Cupcic
Image credit: http://www.esa.int/images/DSC03062.JPG
What it’s like to be a robot in 2017
What will a state-of-the-art robot be able to do in 2017?
There are many different types of robots out there, from humanoid robots to industrial arms that can move with an amazing accuracy and speed.
Given my area of expertise, I’ll focus more on grasping and using objects. These are core human skills that robots need to acquire if you want them to be truly useful.
But why’s it so hard for a robot to replicate these skills?
Here are the capabilities robots need:
For a grasping / manipulating robot
Hardware-wise, a grasping or manipulating robot needs an arm, a hand, and a 3d sensor. The arm usually has about 6 degrees of freedom (for reference, the human arm has 7). This makes it possible to get to any given point in a workspace.
On top of a good position control — being able to drive each joint towards its given target quickly and reliably — the arm and hand also need a reliable torque control. This means that you’re able to apply a given torque with a given joint.
An advanced hand will also have tactile sensing, which makes it possible to manipulate the objects.

A 3d scene acquired from a Kinect.
For a modern robot, understanding its environment is essential. You can’t grasp or use an object if you can’t see it.
The pipeline that’s used the most often for this task is the following:
First, the vision pipeline will run a segmentation algorithm to isolate the different objects in the incoming scene, for example, a 3d point cloud.
Then it will run through some recognition steps. The goal is to identify the objects if possible, and align some known mesh of the object.
The diagrams below are quite simple compared to the real use-case above. Recent advances in deep learning are showing great promises in this domain.



Full scene / segmented results: each object is a different color / each object is recognised, the model is aligned in blue.
Now that the robot has a rough understanding of where things are in the scene, it needs to be able to navigate the environment, avoiding the obstacles. This is the field of motion planning. There are plenty of different algorithms that deal with motion planning.
Now that the robot has a way of reaching the object you want it to grasp, you need to know how to close the hand around the object. There are different ways to address this issue, but two main approaches used most often are grasp planning and teaching by demonstration.
In the grasp planning approach, the algorithm uses some heuristics to compute different grasps and evaluate the grasps using a grasp quality measurement. In the teaching by demonstration approach, a human shows the robot how to do the action. The algorithm then takes care of extracting the information to make the action work reliably on the robot.



Teaching by demonstration — opening a bottle at Bielefled university.
Finally, it’s possible to close the loop using the different sensors available in the robot to accomplish an action, such as stabilizing a grasp when detecting slippage, or moving a finger on an object without letting go of it. Running a tight control loop, then using its data to modify a robot’s next command is a one of the most challenging aspect of robotics.
How can we move forward
It will take a lot of work to develop all of these capabilities and get them to work in all environments. Each individual and each robotics department will have its own specific area of expertise. For example, my area of expertise is in grasping and manipulation, while other people focus more on humanoid robots, mobile platforms and vision.
We all face the same challenge, though: solving complex problems with unreliable data.
Advanced robots are still too often reserved for specialists. They’re hard to program, and you need a lot of knowledge to get them to accomplish new things. But often, what you want your robot to do can be described easily. This is a task that you could do yourself.
To solve this issue, more and more companies are turning to visual programming interfaces in robotics: NAO’s Choregraphe, Robot Blockly (used at Shadow and Erle Robotics), and Franka’s Desk.
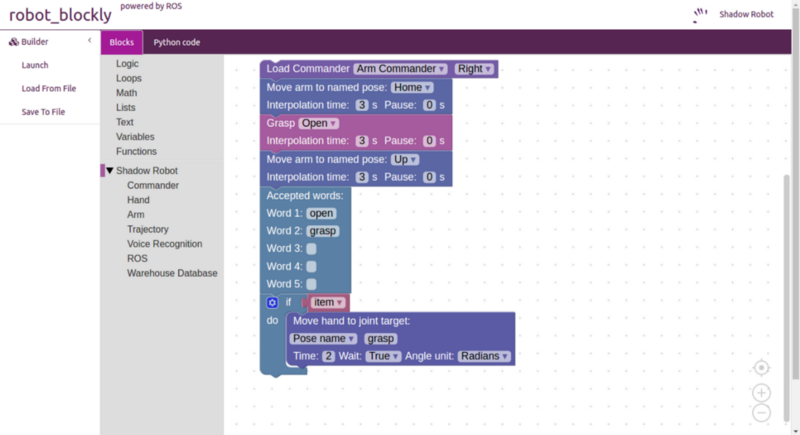
Shadow Robot’s Blockly interface.
But to be able to program advanced robots intuitively through these interfaces, you need advanced — and robust — capabilities.
I’m personally convinced that the way forward is to build more and more intelligence inside the tools themselves. This way, each capability can be implemented by experts.
This black-box approach makes it easier to combine different high-level capabilities, reusing the various state-of-the-art techniques developed by different experts. The boxes don’t need to be black, but the result should be that end users be able to just focus on that box’s functionality — its inputs and its outputs — instead of being distracted by how that functionality should be implemented.
As roboticists, if we want advanced robots to be useful to non-specialists, we need to simplify the interface. But in order do that, we first need to implement more and more advanced capabilities, then wrap them up inside the tools themselves.
If you enjoyed this article, how about liking and sharing it? Also, If you want to discuss robotics, let’s connect on Twitter.
