By Preethi Kasireddy
We covered a lot of ground in Part 1! With syntax out of the way, let’s finally get to the fun part: exploring the advantages and disadvantages of using static types.
The Advantages of using static types
Static types offer many benefits when writing programs. Let’s explore a few of them.
Advantage #1: You can detects bugs and errors early
Static type checking allows us to verify that the invariants we specified are true without actually running the program. And if there’s any violation of those invariants, they will be discovered before runtime instead of during it.
A quick example: suppose we have a simple function that takes a radius and calculates the area:
Now, if we were to pass a radius which is not a number (e.g. ‘im evil’)…
…we’d get back NaN. If some piece of functionality relied on this calculateArea function always returning a number, then this result might lead to a bug or crash. That’s not very pleasing, is it?
Had we used static types, we could have specified the exact input(s) and output types for the function:
Try to pass anything but a number into our calculateArea function now, and Flow will send us a handy-dandy message:
Now we’re guaranteed that the function will only ever accept valid numbers as inputs and return a valid number as output.
Because the type checker tells you when there are errors while you’re coding, it’s a lot more convenient (and a lot less expensive) than finding out about the bug once the code has been shipped to your customers.
Advantage #2: You get living documentation
Types serve as living, breathing documentation for both ourselves and other users of our code.
To see how, let’s look at this method that I once found in a large code base that I was working in:
At first glance (and the second and third), I had no idea how to use this function.
Is quote a number? Or a boolean? Is payment method an object? Or maybe it’s a string representing the type of payment method? Does the function return the date as a string? Or as a Date object?
No clue.
My solution at the time was to evaluate the business logic and grep through the codebase until I figured it out But that’s a lot of work just to understand how a simple function works.
On the other hand, if we had written something like:
It becomes immediately clear what type of data the function takes as input and what type of data it returns as output. This demonstrates how we can use static types to communicate the intent of the function. We can tell other developers what we expect from them, and can see what they expect from us. Next time someone goes to use this function, there will be no questions asked.
There’s an argument to be made that adding code comments or documentation could solve the same problem:
This works. But it’s way more verbose. Beyond verbosity, code comments like this are difficult to maintain because they’re unreliable and lack structure — some developers might write good comments, some might write obscure comments, and some might forget to write them at all.
It’s especially easy to forget to update them when you refactor. Type annotations, however, have a defined syntax and structure and can never go out of date — they’re encoded into the code.
Advantage #3: It reduces convoluted error handling
Types help remove convoluted error handling. Let’s revisit our calculateArea function to see how.
This time, I’ll have it take an array of radii and calculate the area for each radius:
This function works, but doesn’t properly handle invalid input arguments. If we wanted to make sure that we properly handle cases where the input is not a valid array of numbers, we’d end up with a function that looks like:
Wow. That’s a lot of code for a little bit of functionality.
But with static types, we could simply do:
Now the function actually looks like what it originally looked like without all the visual clutter from error handling.
Easy enough to see the benefit, right? :)
Advantage #4: You can refactor with greater confidence
I’ll explain this one through an anecdote: I was working in a very large codebase once and there was a method defined on the User class that we needed to update — specially, we needed to change one of the function parameters from a string to an object.
I made the change, but was having cold feet to commit the change — there were so many invocations of this function sprinkled around the code base that I had no idea if I’d updated all the instances properly. What if I missed some invocation deep in some untested helpers file?
The only way to know was to ship the code and pray that it didn’t blow up with errors.
Using static types would have avoided this. It would have given me the assurance and peace of mind that if I updated a function and in turn, updated the type definitions, the type checker would be there for me to catch all the errors I missed. All I’d have to do is go through those type errors and fix them.
Advantage #5: It separates data from behavior
One less talked-about benefit of static types is that they help separate data from behavior.
Let’s revisit our calculateAreas function with static types:
Think about how we’d go about composing this function. Because we’re annotating types, we are forced to first think about the type of data we intend to use so that we can appropriately define the input and output types.

Only then do we implement the logic:

This ability to precisely express the data separate from the behavior allows us to be explicit about our assumptions and more accurately convey our intent, which relieves some mental burden and brings some mental clarity to the programmer. Without it, we are left to track this mentally in some fashion.
Advantage #6: It eliminates an entire category of bugs
One of the most common errors or bugs we encounter as JavaScript developers are type errors at runtime.
For instance, let’s say our initial application state is defined as:
And let’s assume that we then make an API call to fetch the messages in order to populate our appState. Next, our app has an overly simplified view component that takes in the messages (defined in our state) as a prop and displays the unread count and each message as a list item:
If the API call to fetch the messages fails or returns undefined, we’d end up with a type error in production:
TypeError: Cannot read property ‘length’ of undefined
… and your program crashes. You lose a customer. Bummer.
Let’s see how types can help us. We’ll start by adding Flow types to our application state. I’ll type alias the AppState and then use that to define the state:
Since our API to fetch messages is known to be unreliable, here we’re saying that messages is a maybe type of an array of strings.
Same deal as last time — we fetch our messages from the unreliable API and use it in our view component:
Except now, Flow would catch our error and complain:
Whoa buddy!
Because we defined messages as a maybe type, we are saying that it is allowed to be null or undefined. But it still does not allow us to perform operations on it (like .length or .map) without doing a null check because if the messages value was in fact null or undefined, we’d end up with a type error if we perform any operation on it.
So let’s go back and update our view function to be something like:
Flow now knows that we’ve handled the case where messages is null or undefined, and so the code type checks with 0 errors. Long dead runtime type errors :)
Advantage #7: It reduces the number of unit tests
We saw earlier how static types can help eliminate convoluted error handling because they guarantee input and output types. As a result, they also reduce the # of unit tests.
For instance, let’s go back to our dynamically-typed calculateAreas function with error handling:
If we were diligent programmers, we might have thought to test invalid inputs to make sure they are handled correctly in our program:
… and so on. Except it’s very likely that we forget to test some edge cases — then our customer is the one to discover the problem. :(
Since tests are solely based on the cases we think to test, they are existential and easy to circumvent.
On the other hand, when we’re required to define types:
…not only are we guaranteed that our intent matches reality, but they are also simply harder to escape. Unlike empirically-based tests, types are universal and difficult to be wishy-washy around.
The big picture here is: tests are great at testing logic, and types at testing data types. When combined, the sum of the parts is greater than the whole.
Advantage #8: It provides a domain modeling tool
One of my favorite use cases for types is domain modeling. A domain model is a conceptual model of a domain that includes both the data and behavior on that data. The best way to understand how you can use types to do domain modeling is by looking at an example.
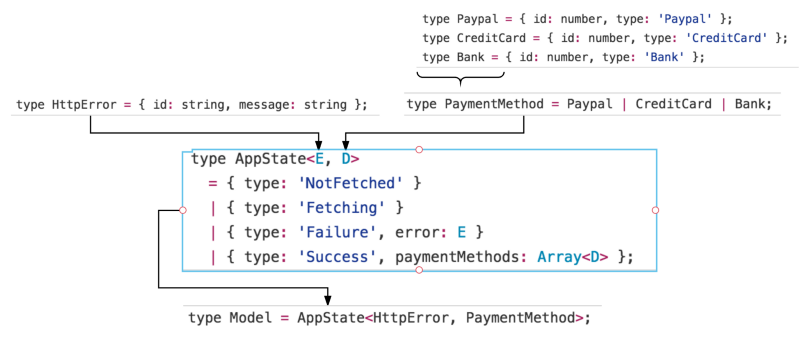
Let’s say I have an application where a user has one or more payment methods to make purchases on the platform. There are three types of payment methods they’re allowed to have (Paypal, Credit card, Bank Account).
So we’ll first type alias these three different payment method types:
Now we can define our PaymentMethod type as a disjoint union with three cases:
Next, let’s model our app state. To keep it simple, let’s assume that our app data only consists of the user’s payment methods.
Is this good enough? Well, we know that to get the user’s payment methods, we need to make an API request, and depending on where in the fetching process we are, our app will have different states. So there’s actually four possible states:
1) We haven’t fetched the payment methods
2) We are fetching the payment methods
3) We successfully fetched the payment methods
4) We tried fetching but there was an error fetching the payment methods
But our simple Model type with paymentMethods doesn’t cover all these cases. Instead, it assumes that paymentMethods always exists.
Hmmm. Is there a way to model our app state to be one of these four cases, and only these four cases? Let’s take a look:
We used a disjoint union type to define our state as one of the four scenarios described above. Notice how I am using a type property to determine which of the four states our app is in. This type property is actually what makes this a disjoint union. Using this, we can do case analysis to determine when we have the payment methods and when we don’t.
You’ll also notice that I pass in a generic type E and D into the app state. Type D will represent the user’s payment method (PaymentMethod defined above). We haven’t defined type E, which will be our error type, so let’s do that now:
Now, we can model our app domain as:
In summary, the signature for our app state is now AppState<E, D> — where E is of the shape HttpError and D is PaymentMethod. And AppState has four (and only these four) possible states: NotFetched, Fetching, Failure and Success.
I find this type of domain modeling useful for thinking about and building user interfaces against certain business rules. The business rules tells us that our app can only ever be in one of these states. So this allows us to explicitly represent build our app state and guarantees that it will only ever be in one of the pre-defined states. And when we build off of this model (e.g. to create a view component), it comes blatantly obvious that we need to handle all four possible states.
Moreover, the code become self-documenting — you can look at the union cases and immediately figure out how the app state is structured.
The Disadvantages of using static types
Like anything else in life and programming, static type checking comes with its tradeoffs.
It’s important that we understand and acknowledge them so we can make an informed decision of when static types make sense and when they simply aren’t worth it.
Here are a few of those considerations:
Disadvantage #1: Static types require investment upfront to learn
One reason JavaScript is such a fantastic language for beginners is because it doesn’t require the student to learn an entire type system before they can be productive in the language.
When I initially learned Elm (a statically-typed functional language), the types often got in the way. I would constantly run into compiler errors related to my type definitions.
Learning how to use the type system effectively has been half the battle in learning the language itself. As a result, static types made the learning curve for Elm steeper than for JavaScript.
This matters especially for beginners where the cognitive load of learning syntax is at an all time high. Adding types to the mix can overwhelm a beginner.
Disadvantage #2: Verbosity can bog you down
Static types often make programs look more verbose and cluttered.
For example, instead of:
We’d have to write:
And instead of:
We’d have to write:
Obviously, this can add extra lines of code. But there are a couple arguments against this being a real downside.
Firstly, as we mentioned earlier, static types help eliminate an entire category of tests. Some developers would consider this a perfectly reasonable tradeoff.
Secondly, as we saw earlier, static types can sometimes eliminate the convoluted error handling and in turn reduce the visual clutter of code significantly.
It’s hard to say whether verbosity is a real argument against types, but it’s one worth keeping in mind.
Disadvantage #3: Types take time to master
It takes time and lots of practice to learn how best to specify types in a program. Moreover, developing a good sense for what is worth tracking statically and what to keep dynamic also requires careful thought, practice, and experience.
For example, one approach we might take is to encode critical business logic with types, while leaving short-lived or unimportant pieces of logic dynamic to avoid needless complexity.
This distinction can be tough to make, especially when developers less experienced with types are making judgment calls on the fly.
Disadvantage #4: Static types can hold up rapid development
As I mentioned earlier, types tripped me up a bit when I was learning Elm — particularly when adding code or making changes. Constantly being distracted by compiler errors made it difficult to feel like I was making any progress.
The argument here is that static type checking might cause a programmer to lose focus too often — and as we know, focus is key for writing good programs.
Not only that, but static type checkers aren’t always perfect. Sometimes you run into situations where you know what you need to do and the type checking just gets in the way.
I’m sure there are other tradeoffs I’m missing, but these were the big ones for me.
Up next, the final conclusion
In the final section, we’ll conclude by discussing whether it makes sense to use static types.
I’ll see you there.