

Window functions are an advanced type of function in SQL. They let you work with observations more easily.
Window functions give you access to features like advanced analytics and data manipulation without the need to write complex queries.
In this lesson you will learn about what window functions are and how they work. Without further ado let's get started.
What is a Window Function?
Before learning exactly what a window function is, let's define the meaning of a term that will appear frequently in this article: result set.
In SQL, a result set is the data or result that is returned from a query. That is, it's the result (table) of running the code of a select statement.
For you to understand what a window function is, let's break the words down into pieces.
What exactly is a window in SQL?
A window is basically a set of rows or observations in a table or result set. In a table you may have more than one window depending on how you specify the query – you will learn about this shortly. A window is defined using the OVER() clause in SQL.
You will learn how to determine the number of windows in a result set later in this article.
What is a Function?
Functions are predefined in SQL and you use them to perform operations on data. They let you do things like aggregating data, formatting strings, extracting dates, and so on.
So windows functions are SQL functions that enable us to perform operations on a window – that is, a set of records.
The interesting thing about window functions is that with them you can specify the windows you want to apply the function on. For example, we can partition the full result set into various groups/windows.
Before we go into the syntax of Window functions, let's have a look at the categories of window functions.
Different Types of Window Functions
There are a lot of window functions that exist in SQL but they are primarily categorized into 3 different types:
Aggregate window functions
Value window functions
Ranking window functions
Aggregate window functions are used to perform operations on sets of rows in a window(s). They include SUM(), MAX(), COUNT(), and others.
Rank window functions are used to rank rows in a window(s). They include RANK(), DENSE_RANK(), ROW_NUMBER(), and others.
Value window functions are like aggregate window functions that perform multiple operations in a window, but they're different from aggregate functions. They include things like LAG(), LEAD(), FIRST_VALUE(), and others. We will see their usefulness later in the section.
Sample Table
In this tutorial you will be working with a table called student_score which contains data such as student_id, student_name, dep_name and score.
You can create the table using the following code:
DROP TABLE IF EXISTS student_score;
CREATE TABLE student_score (
student_id SERIAL PRIMARY KEY,
student_name VARCHAR(30),
dep_name VARCHAR(40),
score INT
);
INSERT INTO student_score VALUES (11, 'Ibrahim', 'Computer Science', 80);
INSERT INTO student_score VALUES (7, 'Taiwo', 'Microbiology', 76);
INSERT INTO student_score VALUES (9, 'Nurain', 'Biochemistry', 80);
INSERT INTO student_score VALUES (8, 'Joel', 'Computer Science', 90);
INSERT INTO student_score VALUES (10, 'Mustapha', 'Industrial Chemistry', 78);
INSERT INTO student_score VALUES (5, 'Muritadoh', 'Biochemistry', 85);
INSERT INTO student_score VALUES (2, 'Yusuf', 'Biochemistry', 70);
INSERT INTO student_score VALUES (3, 'Habeebah', 'Microbiology', 80);
INSERT INTO student_score VALUES (1, 'Tomiwa', 'Microbiology', 65);
INSERT INTO student_score VALUES (4, 'Gbadebo', 'Computer Science', 80);
INSERT INTO student_score VALUES (12, 'Tolu', 'Computer Science', 67);
Syntax for Window Functions
In a simple expression, a window function looks like this:
function(expression|column) OVER(
[ PARTITION BY expr_list optional]
[ ORDER BY order_list optional]
)
Let's go over the syntax piece by piece:
function(expression|column) is the window function such as SUM() or RANK().
OVER() specifies that the function before it is a window function not an ordinary one. So when the SQL engine sees the over clause it will know that the function before the over clause is a window function.
The OVER() clause has some parameters which are optional depending on what you want to achieve. The first one being PARTITION BY.
The PARTITION BY divides the result set into different partitions/windows. For example if you specify the PARTITION BY clause by a column(s) then the result-set will be divided into different windows of the value of that column(s).
The expr_list in the PARTITION BY clause is:
expression | column_name [, expr_list ]
Which means that the PARTITION BY can have an expression, a column, or more than one occurrence or an expression or column which must be separated by a comma. For example PARTITION BY column1, column2.
The next parameter ORDER BY is used to sort the observations in a window. The ORDER BY clause takes order_list which is:
expression | column_name [ ASC | DESC ]
[ NULLS FIRST | NULLS LAST ][, order_list ]
where order_list can be a expression or column name and you can also specify the sort order (either ascending or descending), or you can sort any null values first or last. Also the order by can take many expressions or column names.
As stated earlier, the OVER() clause is used to specify the window in a result set. Now one thing to note is if any parameter is not specified in the OVER() clause the default number of windows in the result set will be one.
You use the PARTITION BY and ORDER BY parameters to determine or specify the numbers of windows. Let's go over an example.
How to Use a Window Function – Example
Let's go over an example of how to use a window function. Say for instance you want to compare the minimum score and maximum score from all the records in the table we created earlier. You can do that using a window function as shown below.
Remember that not specifying a partition clause in the OVER clause will cause all the windows to span through the entire dataset.
SELECT
*,
MAX(score) OVER() AS maximum_score,
MIN(score) OVER() AS minimum_score
FROM student_score;
As you can see, we have the minimum and maximum salary across the entire dataset.
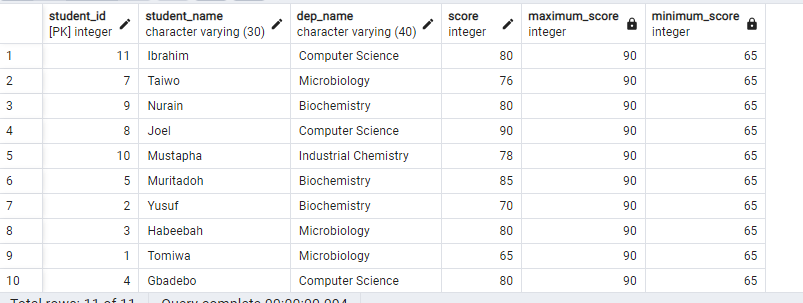
Table showing result of window function
Also, note that the above query can be also achieved using subqueries like this:
SELECT *,
(SELECT MAX(score) FROM student_score) AS maximum_score,
(SELECT MIN(score) FROM student_score) AS minimum_score
FROM student_score;
As you can see, the window function is easier to comprehend compared to the subquery method which looks a bit more advanced.
How to Use a Window Function with PARTITION BY
Say, for instance, that you want to split the dataset into different partitions. Then you want to compare each record in each partition with an aggregate value or a calculated value of each partition. You can specify the PARTITION BY clause in the OVER function.
For example, say you want to compare the maximum score and average score in each department with the individual score. You can do this by specifying the PARTITION BY clause in the OVER statement and also use it with the aggregate function you want to use to achieve your desired result.
SELECT
*,
MAX(score)OVER(PARTITION BY dep_name) AS dep_maximum_score,
ROUND(AVG(score)OVER(PARTITION BY dep_name), 2) AS dep_average_score
FROM student_score;
You can see that the PARTITION BY clause specified in the OVER() clause split the result set into 4 different partitions. This is because there are 4 different departments in the dep_name column (which are Biochemistry, Computer Science, Industrial Chemistry, and Microbiology).
Now after the PARTITION BY clause, you can then calculate the aggregate function for each record in the different departments.

You can see from the above image that the aggregate function MAX() and AVG() is calculated for each partition.
Other Examples of Window Functions
Let's go over some of the common window functions you will work with in SQL.
How to Use the ROW_NUMBER Function
You use ROW_NUMBER() to assign serial numbers to records in a window. Say we want to assign serial numbers to the records in a partition. For example, we want to add row numbers to the dataset based on their names in alphabetical order. You can do that using the following code:
SELECT
*,
ROW_NUMBER() OVER(ORDER BY student_name) AS name_serial_number
FROM student_score;

As you can see from the above image, the student_name with the smallest value (that is, the one that falls earliest in the alphabet) is Gbadebo since it starts with G. Then 1 is added as its row number which is followed by the name that begins with H, and so on.
How to Use the RANK Function
RANK(), as the name implies, lets you rank observations in a window but with gaps. Let's see what this means:
SELECT
*,
RANK()OVER(PARTITION BY dep_name ORDER BY score DESC)
FROM student_score;
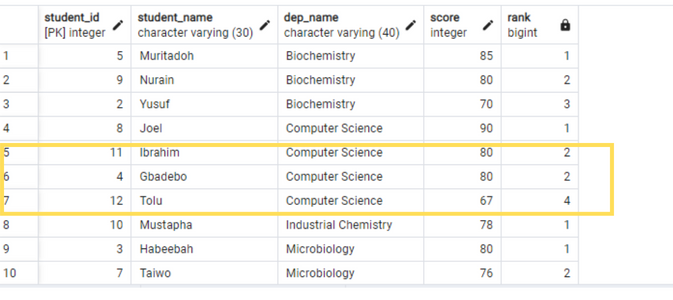
As you can see in the above code, the result set was partitioned into different windows based on the department column. Then we used the ORDER BY clause to sort the student records based on their score in descending order in each partition. After that, we applied the RANK function.
Now concerning the gaps, as you can see in the highlighted part in the above image, two records in the Computer Science department have the same score (80). This caused both to be ranked with the value 2 (instead of one being ranked 2 and the other 3). So it doesn't know how to handle a tie, basically.
You can avoid this scenario using another window function called DENSE_RANK that ranks observations in a window without these gaps.
How to Use the DENSE_RANK Function
DENSE_RANK is similar to RANK except that it ranks observations in a window without gaps.
SELECT
*,
DENSE_RANK()OVER(PARTITION BY dep_name ORDER BY score DESC)
FROM student_score;
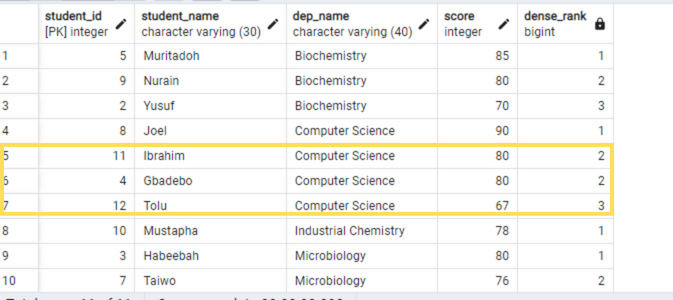
As you can see in the output above, when using DENSE_RANK, the next rank number (which is 3) was assigned to Tolu (unlike when using RANK which assigned Tolu a rank of 4, skipping 3 because of the tie).
How to Use the LAG Function
LAG is used to return the offset row before the current row within a window. By default it returns the previous row before the current row.
You typically use LAG when you want to compare the value of a previous row with the current row. It's commonly applied in time-series analysis. For example:
SELECT
*,
LAG(score) OVER(PARTITION BY dep_name ORDER BY score)
FROM student_score;

As shown in the first partition, the first record in the biochemistry partition (Yusuf's) does not have a previous value (that is, no record comes before it) so that's why null was returned. Then moving to the next record – Muritadoh's – it has a previous record, so it returns the previous value which is 70.
How to Use the Frame Clause in ORDER BY
Now you've learned some common window functions you might work with on a daily basis. So let's move on to learning another key concept related to the ORDER BY clause called the frame clause.
A frame clause, as the name implies, provides the frame (that is, the set of rows in a window) on which the function is to be applied. You use it to provide the offset of rows to be included or calculated with the current row (that is, the rows before or after the current row – the SQL engine process row one after the other).
Now before we look into how to specify a frame clause, let's look at some of the frame clause's assumptions:
First, a frame clause does not apply to ranking functions. The ranking function only ranks the observation in the window based on the
ORDER BYclause.When using an aggregate window function, you may not include the
ORDER BYclause. But when you use theORDER BYclause, it's a best practice to specify the frame clause for accurate results. What this means is say you want to use an aggregate window function and you want to also order the observations in that window by a column. It's best practice is to specify a frame clause so that you will get an accurate result. But if you are not ordering the observations in the window when using an aggregate function, you don't need to specify a frame clause.
You can specify a frame clause using two things – ROWS and RANGE. But in this part you will learn how to use the ROWS keyword since it is commonly used to specify a frame clause. The RANGE keyword is beyond the scope of this article.
The ROWS clause defines the frame in terms of the physical offset rows from the current rows. That is, it is used to specify the rows that will be used in conjunction with the current row for calculation.
For example the following frame clause ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING defines a frame that includes the current row, 1 row preceding it and 1 row following it.
Let's look at the keywords that you can use in conjunction with the ROWS clause:
N PRECEDINGis a keyword you use to specify the N rows that will be included in the calculation along with the current row. For example3 PRECEDINGmeans 3 rows preceding the current row.N FOLLOWINGworks likeN PRECEDINGexcepts that it works in an opposite manner.N FOLLOWINGspecifies the numbers of row after the current row.UNBOUNDED PRECEDINGmeans all rows before the current row.UNBOUNDED FOLLOWINGmeans all rows after the current row.CURRENT ROWis used to specify the current row.
For example, let's look at the below frame clause:
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW will use less than or equal to 2 rows before the current row, along with the current row for the calculation.
Frame clause example
Let's look at an example. Say for instance you want to get the cumulative sum of all the student scores. You can do that by using a frame clause.
So first, to be able to do this, you need to first know the types of keywords you will specify in the frame clause.
Since you want to sum up all rows before the current row and the current row itself, you can use the UNBOUNDED PRECEDING keyword. Remember that this gets all rows before the current row and also uses the current row itself.
So the code to achieve that task is shown below:
SELECT
*,
SUM(score)OVER(ORDER BY student_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cummulative_sum
FROM student_score
Let's break down the window function code:
SUM(score)OVER(ORDER BY student_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cummulative_sum
Firstly in the OVER() clause, we sort the entire window – which is the whole dataset – using the student id.
Then we specify the frame clause which is ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. This is all rows before the current row and the current row will be used for calculation.
The result is shown in the below image:
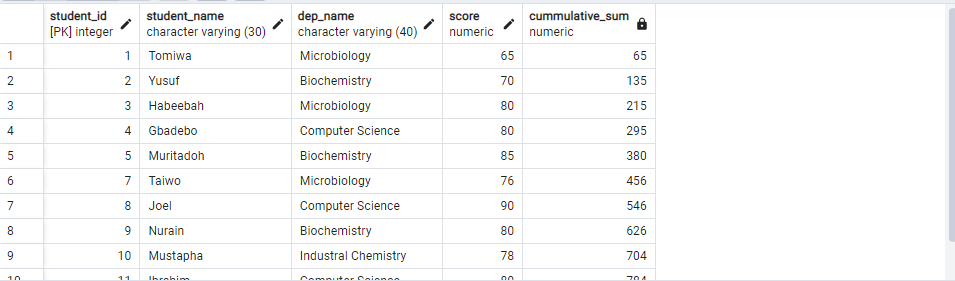
The first row in the dataset does not have any row before it. But since we also specify the CURRENT ROW keyword as the last frame, then the SQL engine finds its sum which equals 65.
Then moving to the second row. It has 1 row before it. So the SQL engine sums the score of the first row 65 with the current row which is 70. That is why the result is 135...and so on down the table.
When to Use a Window Function
You've learned what window functions are in this tutorial. Some practical cases where you can use them are:
When you want to compare an aggregate value in a window with individual records in that window.
When you want to do things like ranking, percentile, cumulative sum or running total, moving average, and so on.
Conclusion
In this tutorial, you've learned what window functions are, and you've also looked at some of the clauses you can add in Windows functions. One example is the PARTITION BY clause, which divides the result set into separate partitions or windows.
You also learned how to utilize the ORDER BY clause to order observations in a window and you saw various common examples of window functions.
Finally, you learned another advanced clause that you can use with window functions, the frame clause, which allows you to access more features of a window.
Thank you for reading all the way to the end. You can use the tutorial listed below to learn about more SQL window functions.